 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData is All You Need: Markov Chain Car-Following (MC-CF) Model
Mar 29, 2026Car-following behavior is fundamental to traffic flow theory, yet traditional models often fail to capture the stochasticity of naturalistic driving. This paper introduces a new car-following modeling category called the empirical probabilistic paradigm, which bypasses conventional parametric assumptions. Within this paradigm, we propose the Markov Chain Car-Following (MC-CF) model, which represents state transitions as a Markov process and predicts behavior by randomly sampling accelerations from empirical distributions within discretized state bins. Evaluation of the MC-CF model trained on the Waymo Open Motion Dataset (WOMD) demonstrates that its variants significantly outperform physics-based models including IDM, Gipps, FVDM, and SIDM in both one-step and open-loop trajectory prediction accuracy. Statistical analysis of transition probabilities confirms that the model-generated trajectories are indistinguishable from real-world behavior, successfully reproducing the probabilistic structure of naturalistic driving across all interaction types. Zero-shot generalization on the Naturalistic Phoenix (PHX) dataset further confirms the model's robustness. Finally, microscopic ring road simulations validate the framework's scalability. By incrementally integrating unconstrained free-flow trajectories and high-speed freeway data (TGSIM) alongside a conservative inference strategy, the model drastically reduces collisions, achieving zero crashes in multiple equilibrium and shockwave scenarios, while successfully reproducing naturalistic and stochastic shockwave propagation. Overall, the proposed MC-CF model provides a robust, scalable, and calibration-free foundation for high-fidelity stochastic traffic modeling, uniquely suited for the data-rich future of intelligent transportation.
Characterizing Lane-Changing Behavior in Mixed Traffic
Dec 08, 2025Characterizing and understanding lane-changing behavior in the presence of automated vehicles (AVs) is crucial to ensuring safety and efficiency in mixed traffic. Accordingly, this study aims to characterize the interactions between the lane-changing vehicle (active vehicle) and the vehicle directly impacted by the maneuver in the target lane (passive vehicle). Utilizing real-world trajectory data from the Waymo Open Motion Dataset (WOMD), this study explores patterns in lane-changing behavior and provides insight into how these behaviors evolve under different AV market penetration rates (MPRs). In particular, we propose a game-theoretic framework to analyze cooperative and defective behaviors in mixed traffic, applied to the 7,636 observed lane-changing events in the WOMD. First, we utilize k-means clustering to classify vehicles as cooperative or defective, revealing that the proportions of cooperative AVs are higher than those of HDVs in both active and passive roles. Next, we jointly estimate the utilities of active and passive vehicles to model their behaviors using the quantal response equilibrium framework. Empirical payoff tables are then constructed based on these utilities. Using these payoffs, we analyze the presence of social dilemmas and examine the evolution of cooperative behaviors using evolutionary game theory. Our results reveal the presence of social dilemmas in approximately 4% and 11% of lane-changing events for active and passive vehicles, respectively, with most classified as Stag Hunt or Prisoner's Dilemma (Chicken Game rarely observed). Moreover, the Monte Carlo simulation results show that repeated lane-changing interactions consistently lead to increased cooperative behavior over time, regardless of the AV penetration rate.
Can the Waymo Open Motion Dataset Support Realistic Behavioral Modeling? A Validation Study with Naturalistic Trajectories
Sep 03, 2025The Waymo Open Motion Dataset (WOMD) has become a popular resource for data-driven modeling of autonomous vehicles (AVs) behavior. However, its validity for behavioral analysis remains uncertain due to proprietary post-processing, the absence of error quantification, and the segmentation of trajectories into 20-second clips. This study examines whether WOMD accurately captures the dynamics and interactions observed in real-world AV operations. Leveraging an independently collected naturalistic dataset from Level 4 AV operations in Phoenix, Arizona (PHX), we perform comparative analyses across three representative urban driving scenarios: discharging at signalized intersections, car-following, and lane-changing behaviors. For the discharging analysis, headways are manually extracted from aerial video to ensure negligible measurement error. For the car-following and lane-changing cases, we apply the Simulation-Extrapolation (SIMEX) method to account for empirically estimated error in the PHX data and use Dynamic Time Warping (DTW) distances to quantify behavioral differences. Results across all scenarios consistently show that behavior in PHX falls outside the behavioral envelope of WOMD. Notably, WOMD underrepresents short headways and abrupt decelerations. These findings suggest that behavioral models calibrated solely on WOMD may systematically underestimate the variability, risk, and complexity of naturalistic driving. Caution is therefore warranted when using WOMD for behavior modeling without proper validation against independently collected data.
Persian Pronoun Resolution: Leveraging Neural Networks and Language Models
May 17, 2024



Coreference resolution, critical for identifying textual entities referencing the same entity, faces challenges in pronoun resolution, particularly identifying pronoun antecedents. Existing methods often treat pronoun resolution as a separate task from mention detection, potentially missing valuable information. This study proposes the first end-to-end neural network system for Persian pronoun resolution, leveraging pre-trained Transformer models like ParsBERT. Our system jointly optimizes both mention detection and antecedent linking, achieving a 3.37 F1 score improvement over the previous state-of-the-art system (which relied on rule-based and statistical methods) on the Mehr corpus. This significant improvement demonstrates the effectiveness of combining neural networks with linguistic models, potentially marking a significant advancement in Persian pronoun resolution and paving the way for further research in this under-explored area.
A hybrid entity-centric approach to Persian pronoun resolution
Nov 11, 2022



Pronoun resolution is a challenging subset of an essential field in natural language processing called coreference resolution. Coreference resolution is about finding all entities in the text that refers to the same real-world entity. This paper presents a hybrid model combining multiple rulebased sieves with a machine-learning sieve for pronouns. For this purpose, seven high-precision rule-based sieves are designed for the Persian language. Then, a random forest classifier links pronouns to the previous partial clusters. The presented method demonstrates exemplary performance using pipeline design and combining the advantages of machine learning and rulebased methods. This method has solved some challenges in end-to-end models. In this paper, the authors develop a Persian coreference corpus called Mehr in the form of 400 documents. This corpus fixes some weaknesses of the previous corpora in the Persian language. Finally, the efficiency of the presented system compared to the earlier model in Persian is reported by evaluating the proposed method on the Mehr and Uppsala test sets.
Review of coreference resolution in English and Persian
Nov 08, 2022
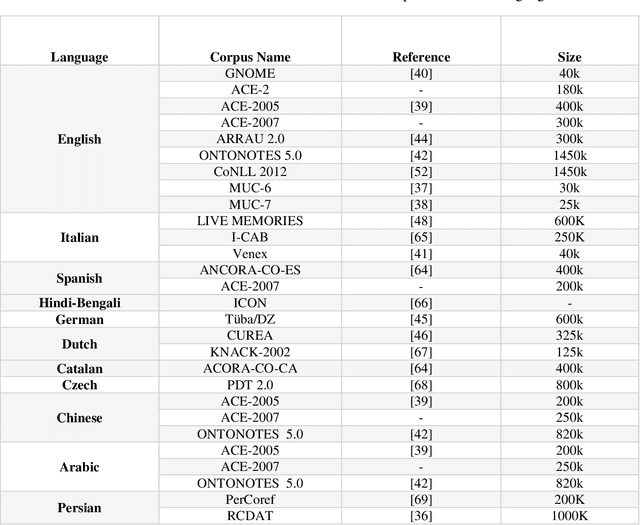

Coreference resolution (CR) is one of the most challenging areas of natural language processing. This task seeks to identify all textual references to the same real-world entity. Research in this field is divided into coreference resolution and anaphora resolution. Due to its application in textual comprehension and its utility in other tasks such as information extraction systems, document summarization, and machine translation, this field has attracted considerable interest. Consequently, it has a significant effect on the quality of these systems. This article reviews the existing corpora and evaluation metrics in this field. Then, an overview of the coreference algorithms, from rule-based methods to the latest deep learning techniques, is provided. Finally, coreference resolution and pronoun resolution systems in Persian are investigated.
The Neural Correlates of Image Texture in the Human Vision Using Magnetoencephalography
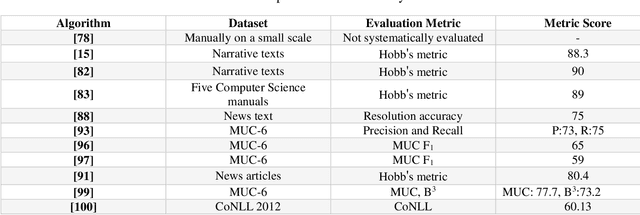
Nov 16, 2021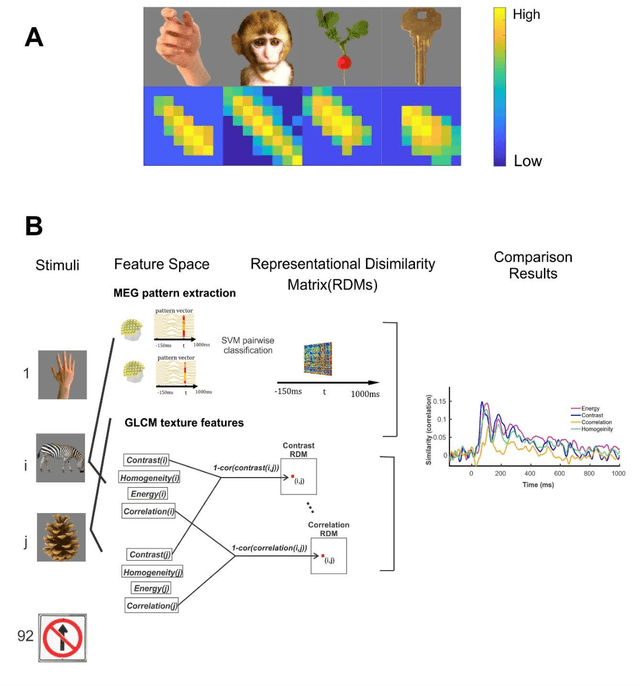
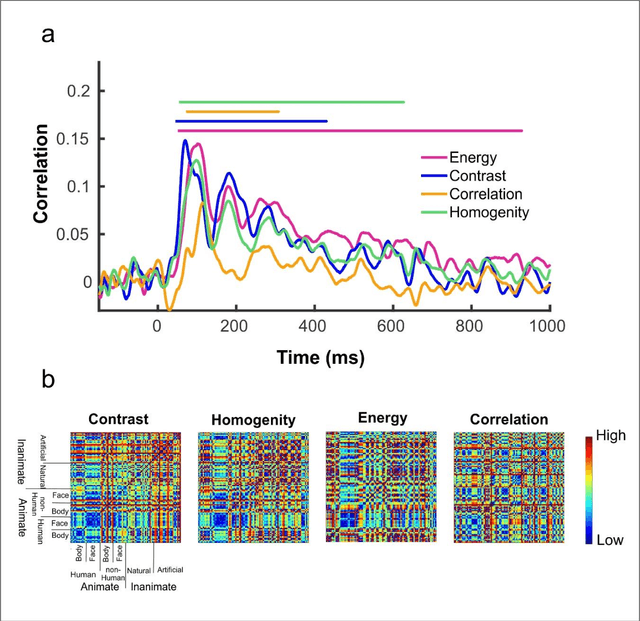
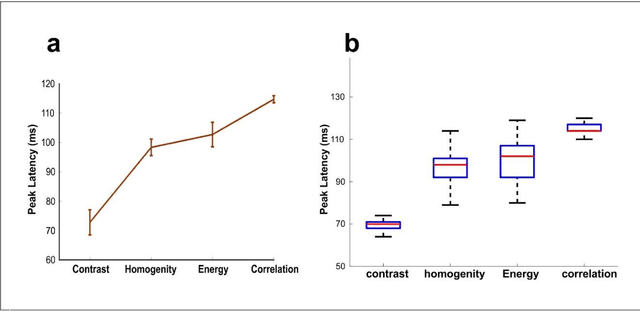
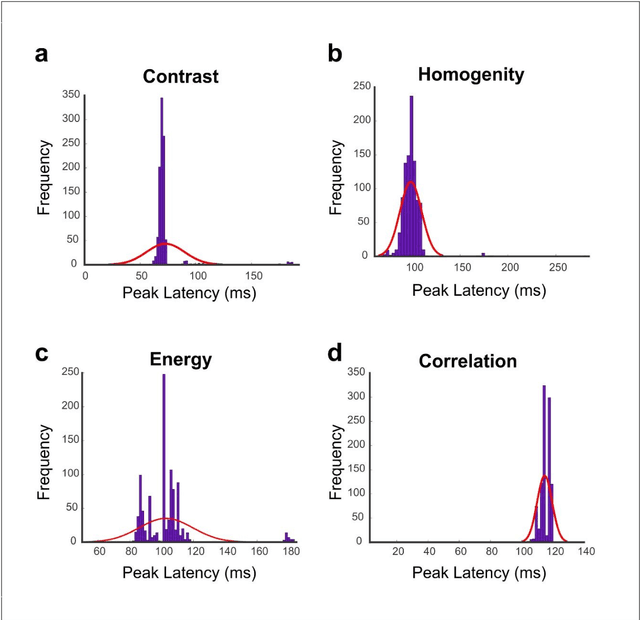
Undoubtedly, textural property of an image is one of the most important features in object recognition task in both human and computer vision applications. Here, we investigated the neural signatures of four well-known statistical texture features including contrast, homogeneity, energy, and correlation computed from the gray level co-occurrence matrix (GLCM) of the images viewed by the participants in the process of magnetoencephalography (MEG) data collection. To trace these features in the human visual system, we used multivariate pattern analysis (MVPA) and trained a linear support vector machine (SVM) classifier on every timepoint of MEG data representing the brain activity and compared it with the textural descriptors of images using the Spearman correlation. The result of this study demonstrates that hierarchical structure in the processing of these four texture descriptors in the human brain with the order of contrast, homogeneity, energy, and correlation. Additionally, we found that energy, which carries broad texture property of the images, shows a more sustained statistically meaningful correlation with the brain activity in the course of time.
Back to the Future: Predicting Traffic Shockwave Formation and Propagation Using a Convolutional Encoder-Decoder Network
May 04, 2019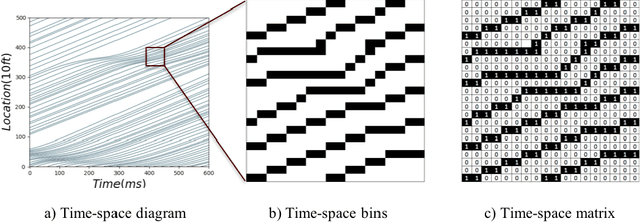
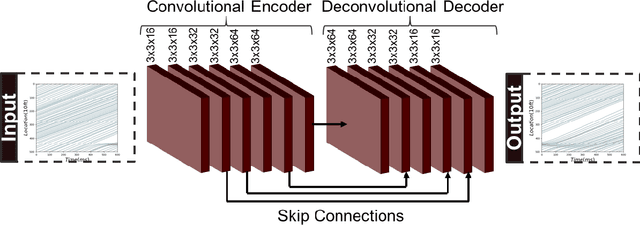
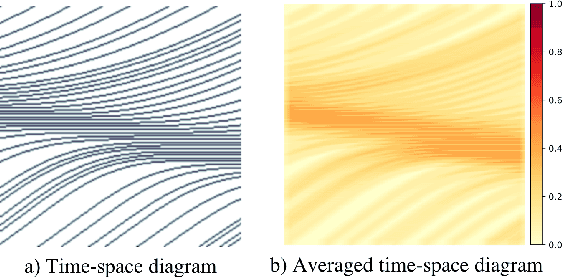

This study proposes a deep learning methodology to predict the propagation of traffic shockwaves. The input to the deep neural network is time-space diagram of the study segment, and the output of the network is the predicted (future) propagation of the shockwave on the study segment in the form of time-space diagram. The main feature of the proposed methodology is the ability to extract the features embedded in the time-space diagram to predict the propagation of traffic shockwaves.
The effect of scene context on weakly supervised semantic segmentation
Feb 12, 2019
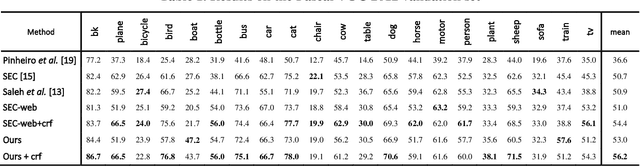
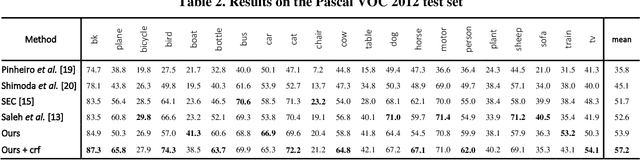

Image semantic segmentation is parsing image into several partitions in such a way that each region of which involves a semantic concept. In a weakly supervised manner, since only image-level labels are available, discriminating objects from the background is challenging, and in some cases, much more difficult. More specifically, some objects which are commonly seen in one specific scene (e.g. 'train' typically is seen on 'railroad track') are much more likely to be confused. In this paper, we propose a method to add the target-specific scenes in order to overcome the aforementioned problem. Actually, we propose a scene recommender which suggests to add some specific scene contexts to the target dataset in order to train the model more accurately. It is notable that this idea could be a complementary part of the baselines of many other methods. The experiments validate the effectiveness of the proposed method for the objects for which the scene context is added.
A Correlation Based Feature Representation for First-Person Activity Recognition
Feb 09, 2018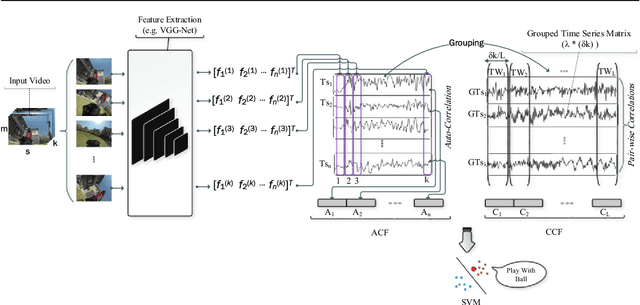
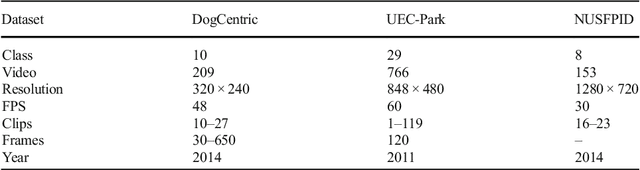
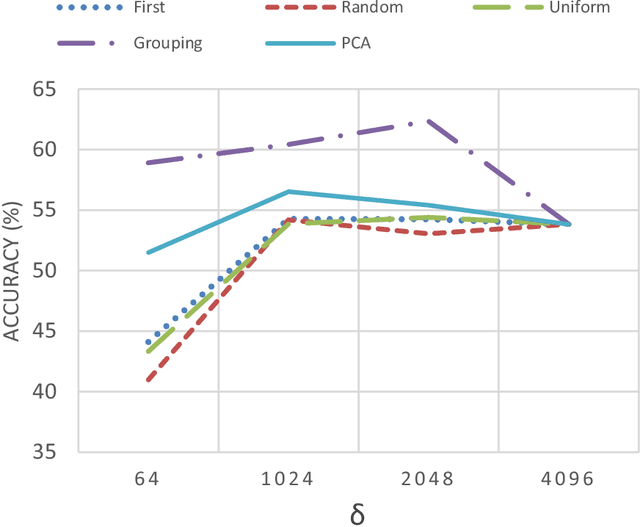

In this paper, a simple yet efficient activity recognition method for first-person video is introduced. The proposed method is appropriate for representation of high-dimensional features such as those extracted from convolutional neural networks (CNNs). The per-frame (per-segment) extracted features are considered as a set of time series, and inter and intra-time series relations are employed to represent the video descriptors. To find the inter-time relations, the series are grouped and the linear correlation between each pair of groups is calculated. The relations between them can represent the scene dynamics and local motions. The introduced grouping strategy helps to considerably reduce the computational cost. Furthermore, we split the series in temporal direction in order to preserve long term motions and better focus on each local time window. In order to extract the cyclic motion patterns, which can be considered as primary components of various activities, intra-time series correlations are exploited. The representation method results in highly discriminative features which can be linearly classified. The experiments confirm that our method outperforms the state-of-the-art methods on recognizing first-person activities on the two challenging first-person datasets.