 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersian Pronoun Resolution: Leveraging Neural Networks and Language Models
May 17, 2024



Coreference resolution, critical for identifying textual entities referencing the same entity, faces challenges in pronoun resolution, particularly identifying pronoun antecedents. Existing methods often treat pronoun resolution as a separate task from mention detection, potentially missing valuable information. This study proposes the first end-to-end neural network system for Persian pronoun resolution, leveraging pre-trained Transformer models like ParsBERT. Our system jointly optimizes both mention detection and antecedent linking, achieving a 3.37 F1 score improvement over the previous state-of-the-art system (which relied on rule-based and statistical methods) on the Mehr corpus. This significant improvement demonstrates the effectiveness of combining neural networks with linguistic models, potentially marking a significant advancement in Persian pronoun resolution and paving the way for further research in this under-explored area.
A hybrid entity-centric approach to Persian pronoun resolution
Nov 11, 2022



Pronoun resolution is a challenging subset of an essential field in natural language processing called coreference resolution. Coreference resolution is about finding all entities in the text that refers to the same real-world entity. This paper presents a hybrid model combining multiple rulebased sieves with a machine-learning sieve for pronouns. For this purpose, seven high-precision rule-based sieves are designed for the Persian language. Then, a random forest classifier links pronouns to the previous partial clusters. The presented method demonstrates exemplary performance using pipeline design and combining the advantages of machine learning and rulebased methods. This method has solved some challenges in end-to-end models. In this paper, the authors develop a Persian coreference corpus called Mehr in the form of 400 documents. This corpus fixes some weaknesses of the previous corpora in the Persian language. Finally, the efficiency of the presented system compared to the earlier model in Persian is reported by evaluating the proposed method on the Mehr and Uppsala test sets.
Review of coreference resolution in English and Persian
Nov 08, 2022
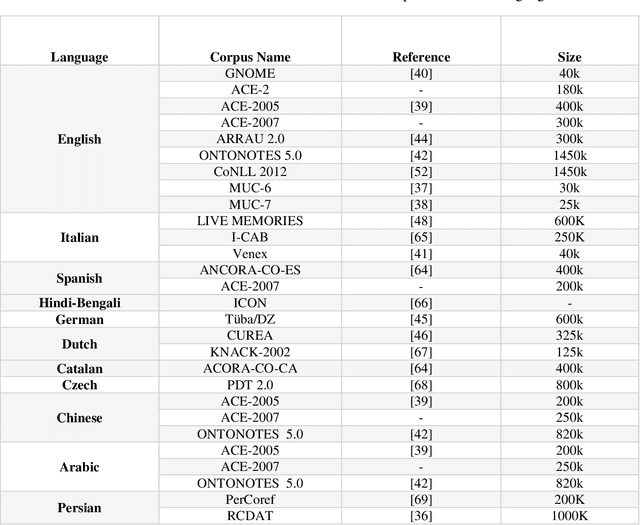
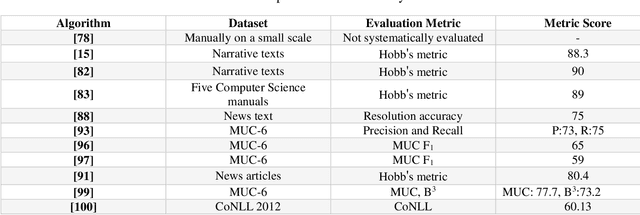

Coreference resolution (CR) is one of the most challenging areas of natural language processing. This task seeks to identify all textual references to the same real-world entity. Research in this field is divided into coreference resolution and anaphora resolution. Due to its application in textual comprehension and its utility in other tasks such as information extraction systems, document summarization, and machine translation, this field has attracted considerable interest. Consequently, it has a significant effect on the quality of these systems. This article reviews the existing corpora and evaluation metrics in this field. Then, an overview of the coreference algorithms, from rule-based methods to the latest deep learning techniques, is provided. Finally, coreference resolution and pronoun resolution systems in Persian are investigated.