 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiple Toddler Tracking in Indoor Videos
Nov 29, 2023



Multiple toddler tracking (MTT) involves identifying and differentiating toddlers in video footage. While conventional multi-object tracking (MOT) algorithms are adept at tracking diverse objects, toddlers pose unique challenges due to their unpredictable movements, various poses, and similar appearance. Tracking toddlers in indoor environments introduces additional complexities such as occlusions and limited fields of view. In this paper, we address the challenges of MTT and propose MTTSort, a customized method built upon the DeepSort algorithm. MTTSort is designed to track multiple toddlers in indoor videos accurately. Our contributions include discussing the primary challenges in MTT, introducing a genetic algorithm to optimize hyperparameters, proposing an accurate tracking algorithm, and curating the MTTrack dataset using unbiased AI co-labeling techniques. We quantitatively compare MTTSort to state-of-the-art MOT methods on MTTrack, DanceTrack, and MOT15 datasets. In our evaluation, the proposed method outperformed other MOT methods, achieving 0.98, 0.68, and 0.98 in multiple object tracking accuracy (MOTA), higher order tracking accuracy (HOTA), and iterative and discriminative framework 1 (IDF1) metrics, respectively.
Challenges in Video-Based Infant Action Recognition: A Critical Examination of the State of the Art
Nov 21, 2023


Automated human action recognition, a burgeoning field within computer vision, boasts diverse applications spanning surveillance, security, human-computer interaction, tele-health, and sports analysis. Precise action recognition in infants serves a multitude of pivotal purposes, encompassing safety monitoring, developmental milestone tracking, early intervention for developmental delays, fostering parent-infant bonds, advancing computer-aided diagnostics, and contributing to the scientific comprehension of child development. This paper delves into the intricacies of infant action recognition, a domain that has remained relatively uncharted despite the accomplishments in adult action recognition. In this study, we introduce a groundbreaking dataset called ``InfActPrimitive'', encompassing five significant infant milestone action categories, and we incorporate specialized preprocessing for infant data. We conducted an extensive comparative analysis employing cutting-edge skeleton-based action recognition models using this dataset. Our findings reveal that, although the PoseC3D model achieves the highest accuracy at approximately 71%, the remaining models struggle to accurately capture the dynamics of infant actions. This highlights a substantial knowledge gap between infant and adult action recognition domains and the urgent need for data-efficient pipeline models.
A Video-based End-to-end Pipeline for Non-nutritive Sucking Action Recognition and Segmentation in Young Infants
Mar 29, 2023We present an end-to-end computer vision pipeline to detect non-nutritive sucking (NNS) -- an infant sucking pattern with no nutrition delivered -- as a potential biomarker for developmental delays, using off-the-shelf baby monitor video footage. One barrier to clinical (or algorithmic) assessment of NNS stems from its sparsity, requiring experts to wade through hours of footage to find minutes of relevant activity. Our NNS activity segmentation algorithm solves this problem by identifying periods of NNS with high certainty -- up to 94.0\% average precision and 84.9\% average recall across 30 heterogeneous 60 s clips, drawn from our manually annotated NNS clinical in-crib dataset of 183 hours of overnight baby monitor footage from 19 infants. Our method is based on an underlying NNS action recognition algorithm, which uses spatiotemporal deep learning networks and infant-specific pose estimation, achieving 94.9\% accuracy in binary classification of 960 2.5 s balanced NNS vs. non-NNS clips. Tested on our second, independent, and public NNS in-the-wild dataset, NNS recognition classification reaches 92.3\% accuracy, and NNS segmentation achieves 90.8\% precision and 84.2\% recall.
The Neural Correlates of Image Texture in the Human Vision Using Magnetoencephalography
Nov 16, 2021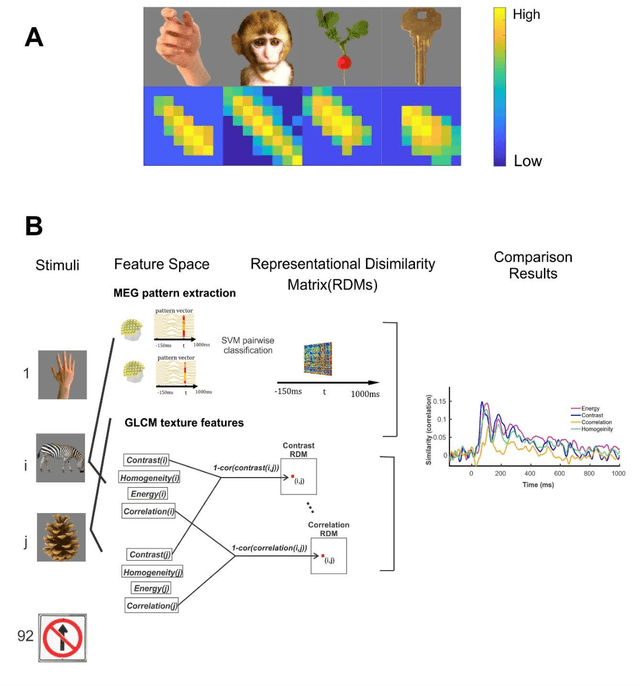
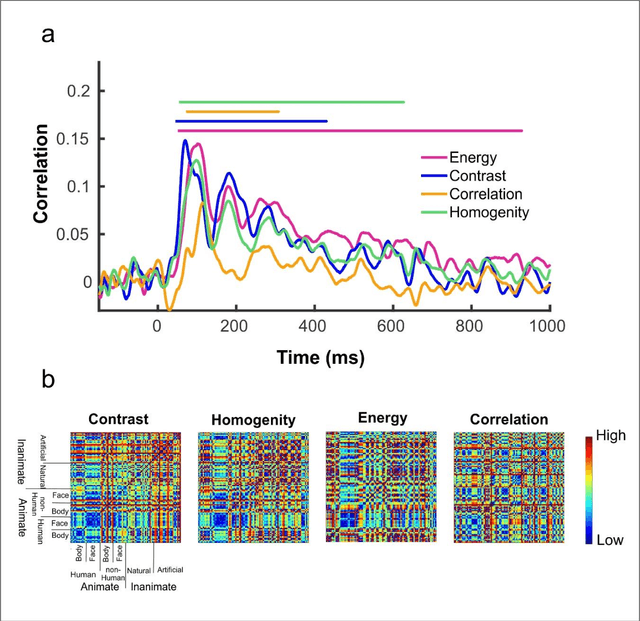
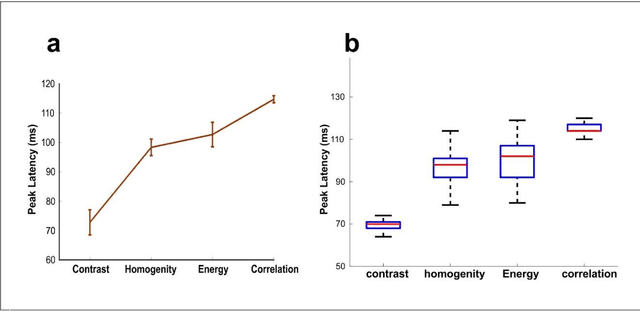
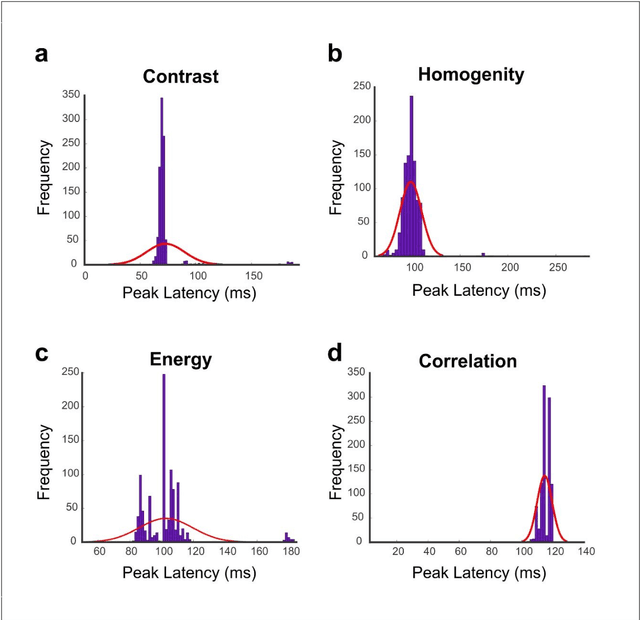
Undoubtedly, textural property of an image is one of the most important features in object recognition task in both human and computer vision applications. Here, we investigated the neural signatures of four well-known statistical texture features including contrast, homogeneity, energy, and correlation computed from the gray level co-occurrence matrix (GLCM) of the images viewed by the participants in the process of magnetoencephalography (MEG) data collection. To trace these features in the human visual system, we used multivariate pattern analysis (MVPA) and trained a linear support vector machine (SVM) classifier on every timepoint of MEG data representing the brain activity and compared it with the textural descriptors of images using the Spearman correlation. The result of this study demonstrates that hierarchical structure in the processing of these four texture descriptors in the human brain with the order of contrast, homogeneity, energy, and correlation. Additionally, we found that energy, which carries broad texture property of the images, shows a more sustained statistically meaningful correlation with the brain activity in the course of time.