 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAMPER: A Dual-Stage Medical Report Generation Framework with Coarse-Grained MeSH Alignment and Fine-Grained Hypergraph Matching
Dec 19, 2024



Medical report generation is crucial for clinical diagnosis and patient management, summarizing diagnoses and recommendations based on medical imaging. However, existing work often overlook the clinical pipeline involved in report writing, where physicians typically conduct an initial quick review followed by a detailed examination. Moreover, current alignment methods may lead to misaligned relationships. To address these issues, we propose DAMPER, a dual-stage framework for medical report generation that mimics the clinical pipeline of report writing in two stages. In the first stage, a MeSH-Guided Coarse-Grained Alignment (MCG) stage that aligns chest X-ray (CXR) image features with medical subject headings (MeSH) features to generate a rough keyphrase representation of the overall impression. In the second stage, a Hypergraph-Enhanced Fine-Grained Alignment (HFG) stage that constructs hypergraphs for image patches and report annotations, modeling high-order relationships within each modality and performing hypergraph matching to capture semantic correlations between image regions and textual phrases. Finally,the coarse-grained visual features, generated MeSH representations, and visual hypergraph features are fed into a report decoder to produce the final medical report. Extensive experiments on public datasets demonstrate the effectiveness of DAMPER in generating comprehensive and accurate medical reports, outperforming state-of-the-art methods across various evaluation metrics.
Challenges in Video-Based Infant Action Recognition: A Critical Examination of the State of the Art
Nov 21, 2023


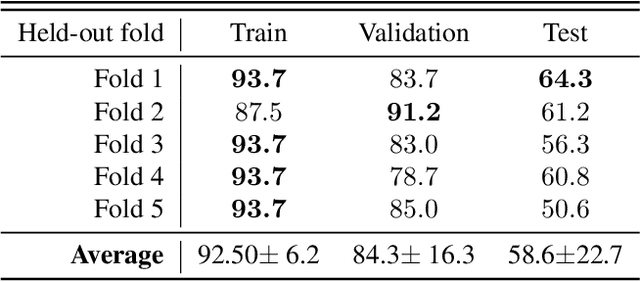
Automated human action recognition, a burgeoning field within computer vision, boasts diverse applications spanning surveillance, security, human-computer interaction, tele-health, and sports analysis. Precise action recognition in infants serves a multitude of pivotal purposes, encompassing safety monitoring, developmental milestone tracking, early intervention for developmental delays, fostering parent-infant bonds, advancing computer-aided diagnostics, and contributing to the scientific comprehension of child development. This paper delves into the intricacies of infant action recognition, a domain that has remained relatively uncharted despite the accomplishments in adult action recognition. In this study, we introduce a groundbreaking dataset called ``InfActPrimitive'', encompassing five significant infant milestone action categories, and we incorporate specialized preprocessing for infant data. We conducted an extensive comparative analysis employing cutting-edge skeleton-based action recognition models using this dataset. Our findings reveal that, although the PoseC3D model achieves the highest accuracy at approximately 71%, the remaining models struggle to accurately capture the dynamics of infant actions. This highlights a substantial knowledge gap between infant and adult action recognition domains and the urgent need for data-efficient pipeline models.
HST-MRF: Heterogeneous Swin Transformer with Multi-Receptive Field for Medical Image Segmentation
Apr 10, 2023The Transformer has been successfully used in medical image segmentation due to its excellent long-range modeling capabilities. However, patch segmentation is necessary when building a Transformer class model. This process may disrupt the tissue structure in medical images, resulting in the loss of relevant information. In this study, we proposed a Heterogeneous Swin Transformer with Multi-Receptive Field (HST-MRF) model based on U-shaped networks for medical image segmentation. The main purpose is to solve the problem of loss of structural information caused by patch segmentation using transformer by fusing patch information under different receptive fields. The heterogeneous Swin Transformer (HST) is the core module, which achieves the interaction of multi-receptive field patch information through heterogeneous attention and passes it to the next stage for progressive learning. We also designed a two-stage fusion module, multimodal bilinear pooling (MBP), to assist HST in further fusing multi-receptive field information and combining low-level and high-level semantic information for accurate localization of lesion regions. In addition, we developed adaptive patch embedding (APE) and soft channel attention (SCA) modules to retain more valuable information when acquiring patch embedding and filtering channel features, respectively, thereby improving model segmentation quality. We evaluated HST-MRF on multiple datasets for polyp and skin lesion segmentation tasks. Experimental results show that our proposed method outperforms state-of-the-art models and can achieve superior performance. Furthermore, we verified the effectiveness of each module and the benefits of multi-receptive field segmentation in reducing the loss of structural information through ablation experiments.
Automatic Assessment of Infant Face and Upper-Body Symmetry as Early Signs of Torticollis
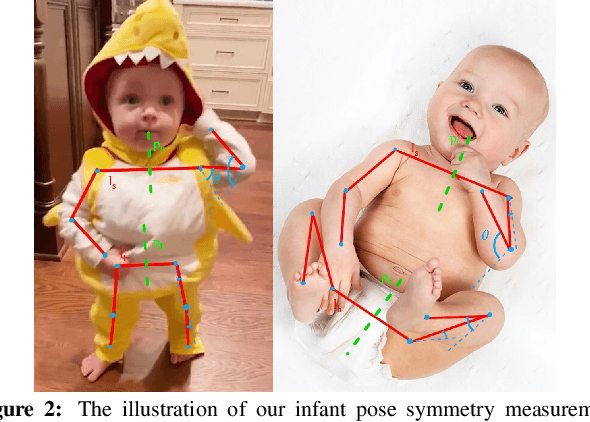
Nov 07, 2022We apply computer vision pose estimation techniques developed expressly for the data-scarce infant domain to the study of torticollis, a common condition in infants for which early identification and treatment is critical. Specifically, we use a combination of facial landmark and body joint estimation techniques designed for infants to estimate a range of geometric measures pertaining to face and upper body symmetry, drawn from an array of sources in the physical therapy and ophthalmology research literature in torticollis. We gauge performance with a range of metrics and show that the estimates of most these geometric measures are successful, yielding strong to very strong Spearman's $\rho$ correlation with ground truth values. Furthermore, we show that these estimates, derived from pose estimation neural networks designed for the infant domain, cleanly outperform estimates derived from more widely known networks designed for the adult domain
A Dual-Attention Learning Network with Word and Sentence Embedding for Medical Visual Question Answering
Oct 01, 2022
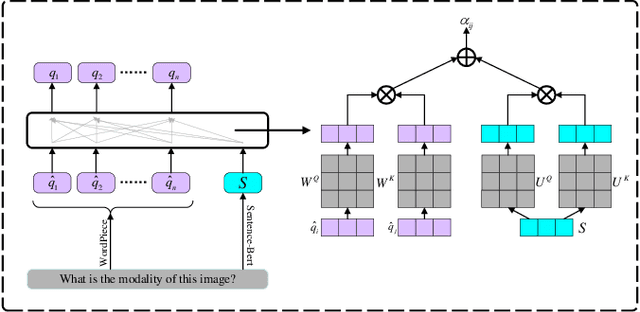

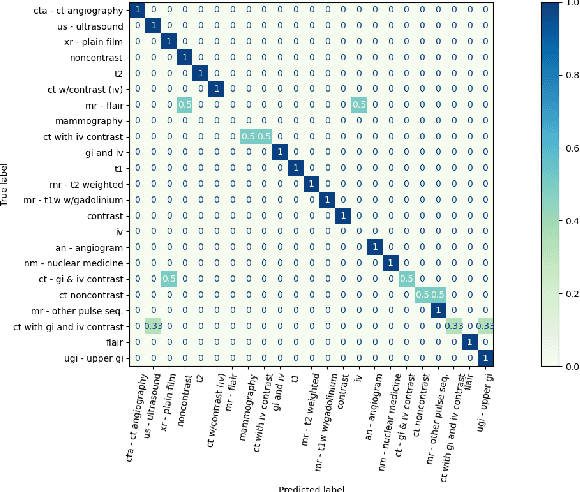
Research in medical visual question answering (MVQA) can contribute to the development of computeraided diagnosis. MVQA is a task that aims to predict accurate and convincing answers based on given medical images and associated natural language questions. This task requires extracting medical knowledge-rich feature content and making fine-grained understandings of them. Therefore, constructing an effective feature extraction and understanding scheme are keys to modeling. Existing MVQA question extraction schemes mainly focus on word information, ignoring medical information in the text. Meanwhile, some visual and textual feature understanding schemes cannot effectively capture the correlation between regions and keywords for reasonable visual reasoning. In this study, a dual-attention learning network with word and sentence embedding (WSDAN) is proposed. We design a module, transformer with sentence embedding (TSE), to extract a double embedding representation of questions containing keywords and medical information. A dualattention learning (DAL) module consisting of self-attention and guided attention is proposed to model intensive intramodal and intermodal interactions. With multiple DAL modules (DALs), learning visual and textual co-attention can increase the granularity of understanding and improve visual reasoning. Experimental results on the ImageCLEF 2019 VQA-MED (VQA-MED 2019) and VQA-RAD datasets demonstrate that our proposed method outperforms previous state-of-the-art methods. According to the ablation studies and Grad-CAM maps, WSDAN can extract rich textual information and has strong visual reasoning ability.
Computer Vision to the Rescue: Infant Postural Symmetry Estimation from Incongruent Annotations
Jul 19, 2022


Bilateral postural symmetry plays a key role as a potential risk marker for autism spectrum disorder (ASD) and as a symptom of congenital muscular torticollis (CMT) in infants, but current methods of assessing symmetry require laborious clinical expert assessments. In this paper, we develop a computer vision based infant symmetry assessment system, leveraging 3D human pose estimation for infants. Evaluation and calibration of our system against ground truth assessments is complicated by our findings from a survey of human ratings of angle and symmetry, that such ratings exhibit low inter-rater reliability. To rectify this, we develop a Bayesian estimator of the ground truth derived from a probabilistic graphical model of fallible human raters. We show that the 3D infant pose estimation model can achieve 68% area under the receiver operating characteristic curve performance in predicting the Bayesian aggregate labels, compared to only 61% from a 2D infant pose estimation model and 60% from a 3D adult pose estimation model, highlighting the importance of 3D poses and infant domain knowledge in assessing infant body symmetry. Our survey analysis also suggests that human ratings are susceptible to higher levels of bias and inconsistency, and hence our final 3D pose-based symmetry assessment system is calibrated but not directly supervised by Bayesian aggregate human ratings, yielding higher levels of consistency and lower levels of inter-limb assessment bias.
Heuristic Weakly Supervised 3D Human Pose Estimation in Novel Contexts without Any 3D Pose Ground Truth
May 23, 2021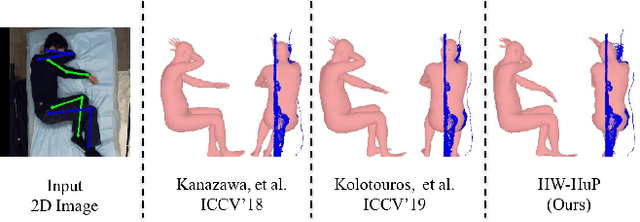
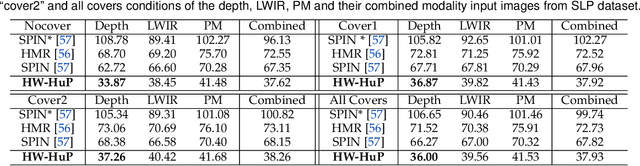
Monocular 3D human pose estimation from a single RGB image has received a lot attentions in the past few year. Pose inference models with competitive performance however require supervision with 3D pose ground truth data or at least known pose priors in their target domain. Yet, these data requirements in many real-world applications with data collection constraints may not be achievable. In this paper, we present a heuristic weakly supervised solution, called HW-HuP to estimate 3D human pose in contexts that no ground truth 3D data is accessible, even for fine-tuning. HW-HuP learns partial pose priors from public 3D human pose datasets and uses easy-to-access observations from the target domain to iteratively estimate 3D human pose and shape in an optimization and regression hybrid cycle. In our design, depth data as an auxiliary information is employed as weak supervision during training, yet it is not needed for the inference. We evaluate HW-HuP performance qualitatively on datasets of both in-bed human and infant poses, where no ground truth 3D pose is provided neither any target prior. We also test HW-HuP performance quantitatively on a publicly available motion capture dataset against the 3D ground truth. HW-HuP is also able to be extended to other input modalities for pose estimation tasks especially under adverse vision conditions, such as occlusion or full darkness. On the Human3.6M benchmark, HW-HuP shows 104.1mm in MPJPE and 50.4mm in PA MPJPE, comparable to the existing state-of-the-art approaches that benefit from full 3D pose supervision.
Infant Pose Learning with Small Data
Oct 13, 2020



With the increasing maturity of the human pose estimation domain, its applications have become more and more broaden. Yet, the state-of-the-art pose estimation models performance degrades significantly in the applications that include novel subjects or poses, such as infants with their unique movements. Infant motion analysis is a topic with critical importance in child health and developmental studies. However, models trained on large-scale adult pose datasets are barely successful in estimating infant poses due to significant differences in their body ratio and the versatility of poses they can take compared to adults. Moreover, the privacy and security considerations hinder the availability of enough infant images required for training a robust pose estimation model from scratch. Here, we propose a fine-tuned domain-adapted infant pose (FiDIP) estimation model, that transfers the knowledge of adult poses into estimating infant pose with the supervision of a domain adaptation technique on a mixed real and synthetic infant pose dataset. In developing FiDIP, we also built a synthetic and real infant pose (SyRIP) dataset with diverse and fully-annotated real infant images and generated synthetic infant images. We demonstrated that our FiDIP model outperforms other state-of-the-art human pose estimation model for the infant pose estimation, with the mean average precision (AP) as high as 92.2.
Simultaneously-Collected Multimodal Lying Pose Dataset: Towards In-Bed Human Pose Monitoring under Adverse Vision Conditions
Aug 20, 2020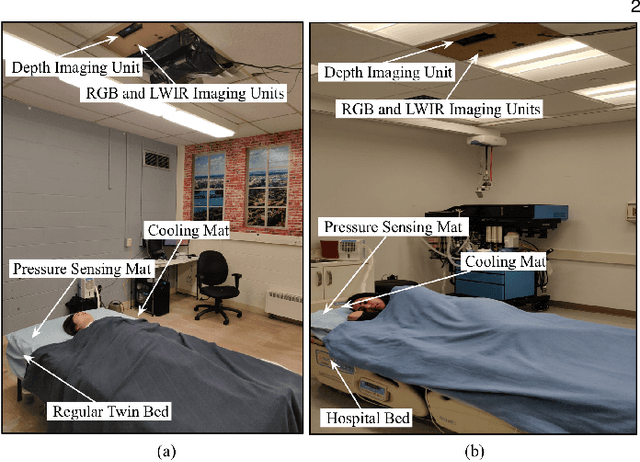
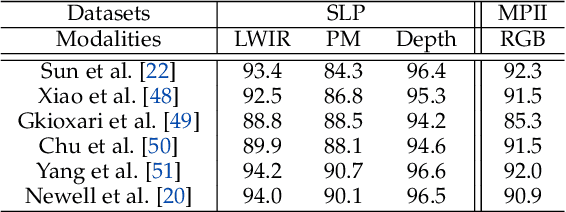
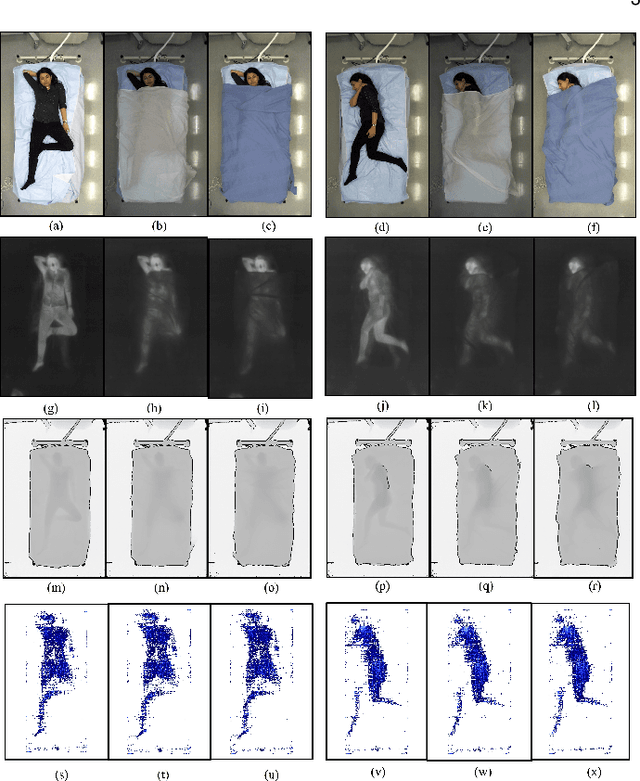
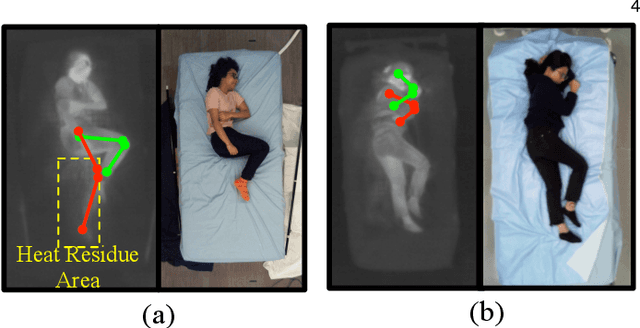
Computer vision (CV) has achieved great success in interpreting semantic meanings from images, yet CV algorithms can be brittle for tasks with adverse vision conditions and the ones suffering from data/label pair limitation. One of this tasks is in-bed human pose estimation, which has significant values in many healthcare applications. In-bed pose monitoring in natural settings could involve complete darkness or full occlusion. Furthermore, the lack of publicly available in-bed pose datasets hinders the use of many successful pose estimation algorithms for this task. In this paper, we introduce our Simultaneously-collected multimodal Lying Pose (SLP) dataset, which includes in-bed pose images from 109 participants captured using multiple imaging modalities including RGB, long wave infrared, depth, and pressure map. We also present a physical hyper parameter tuning strategy for ground truth pose label generation under extreme conditions such as lights off and being fully covered by a sheet/blanket. SLP design is compatible with the mainstream human pose datasets, therefore, the state-of-the-art 2D pose estimation models can be trained effectively with SLP data with promising performance as high as 95% at PCKh@0.5 on a single modality. The pose estimation performance can be further improved by including additional modalities through collaboration.
Infant Contact-less Non-Nutritive Sucking Pattern Quantification via Facial Gesture Analysis
Jun 05, 2019


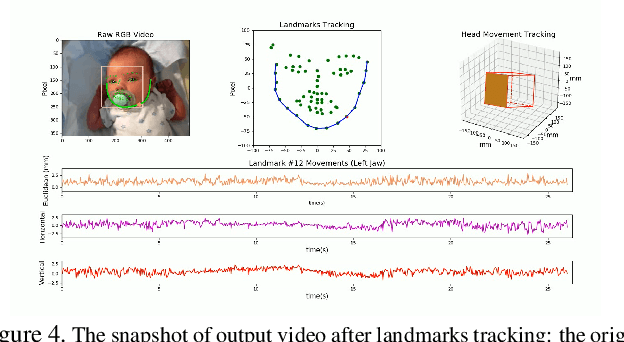
Non-nutritive sucking (NNS) is defined as the sucking action that occurs when a finger, pacifier, or other object is placed in the baby's mouth, but there is no nutrient delivered. In addition to providing a sense of safety, NNS even can be regarded as an indicator of infant's central nervous system development. The rich data, such as sucking frequency, the number of cycles, and their amplitude during baby's non-nutritive sucking is important clue for judging the brain development of infants or preterm infants. Nowadays most researchers are collecting NNS data by using some contact devices such as pressure transducers. However, such invasive contact will have a direct impact on the baby's natural sucking behavior, resulting in significant distortion in the collected data. Therefore, we propose a novel contact-less NNS data acquisition and quantification scheme, which leverages the facial landmarks tracking technology to extract the movement signals of baby's jaw from recorded baby's sucking video. Since completion of the sucking action requires a large amount of synchronous coordination and neural integration of the facial muscles and the cranial nerves, the facial muscle movement signals accompanying baby's sucking pacifier can indirectly replace the NNS signal. We have evaluated our method on videos collected from several infants during their NNS behaviors and we have achieved the quantified NNS patterns closely comparable to results from visual inspection as well as contact-based sensor readings.