 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHST-MRF: Heterogeneous Swin Transformer with Multi-Receptive Field for Medical Image Segmentation
Apr 10, 2023The Transformer has been successfully used in medical image segmentation due to its excellent long-range modeling capabilities. However, patch segmentation is necessary when building a Transformer class model. This process may disrupt the tissue structure in medical images, resulting in the loss of relevant information. In this study, we proposed a Heterogeneous Swin Transformer with Multi-Receptive Field (HST-MRF) model based on U-shaped networks for medical image segmentation. The main purpose is to solve the problem of loss of structural information caused by patch segmentation using transformer by fusing patch information under different receptive fields. The heterogeneous Swin Transformer (HST) is the core module, which achieves the interaction of multi-receptive field patch information through heterogeneous attention and passes it to the next stage for progressive learning. We also designed a two-stage fusion module, multimodal bilinear pooling (MBP), to assist HST in further fusing multi-receptive field information and combining low-level and high-level semantic information for accurate localization of lesion regions. In addition, we developed adaptive patch embedding (APE) and soft channel attention (SCA) modules to retain more valuable information when acquiring patch embedding and filtering channel features, respectively, thereby improving model segmentation quality. We evaluated HST-MRF on multiple datasets for polyp and skin lesion segmentation tasks. Experimental results show that our proposed method outperforms state-of-the-art models and can achieve superior performance. Furthermore, we verified the effectiveness of each module and the benefits of multi-receptive field segmentation in reducing the loss of structural information through ablation experiments.
A Dual-Attention Learning Network with Word and Sentence Embedding for Medical Visual Question Answering
Oct 01, 2022
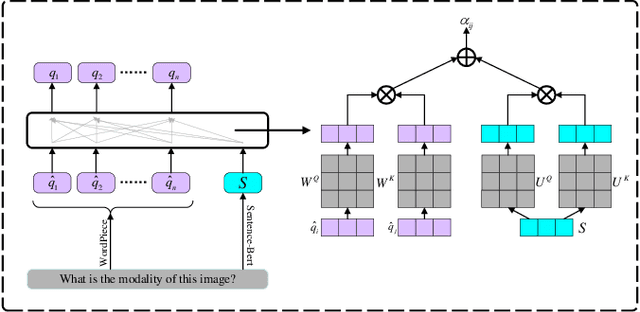

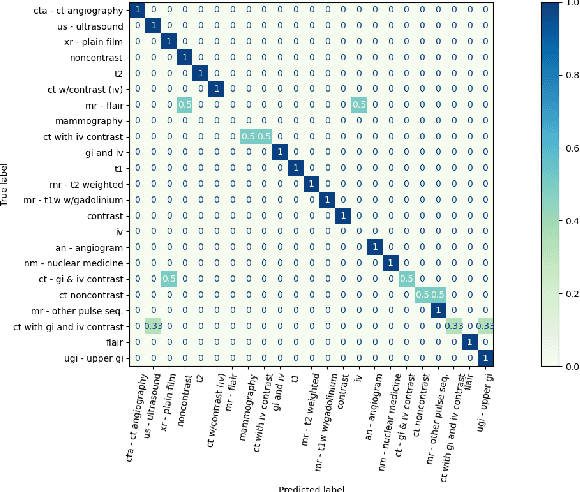
Research in medical visual question answering (MVQA) can contribute to the development of computeraided diagnosis. MVQA is a task that aims to predict accurate and convincing answers based on given medical images and associated natural language questions. This task requires extracting medical knowledge-rich feature content and making fine-grained understandings of them. Therefore, constructing an effective feature extraction and understanding scheme are keys to modeling. Existing MVQA question extraction schemes mainly focus on word information, ignoring medical information in the text. Meanwhile, some visual and textual feature understanding schemes cannot effectively capture the correlation between regions and keywords for reasonable visual reasoning. In this study, a dual-attention learning network with word and sentence embedding (WSDAN) is proposed. We design a module, transformer with sentence embedding (TSE), to extract a double embedding representation of questions containing keywords and medical information. A dualattention learning (DAL) module consisting of self-attention and guided attention is proposed to model intensive intramodal and intermodal interactions. With multiple DAL modules (DALs), learning visual and textual co-attention can increase the granularity of understanding and improve visual reasoning. Experimental results on the ImageCLEF 2019 VQA-MED (VQA-MED 2019) and VQA-RAD datasets demonstrate that our proposed method outperforms previous state-of-the-art methods. According to the ablation studies and Grad-CAM maps, WSDAN can extract rich textual information and has strong visual reasoning ability.