 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGransformer: Transformer-based Graph Generation
Mar 25, 2022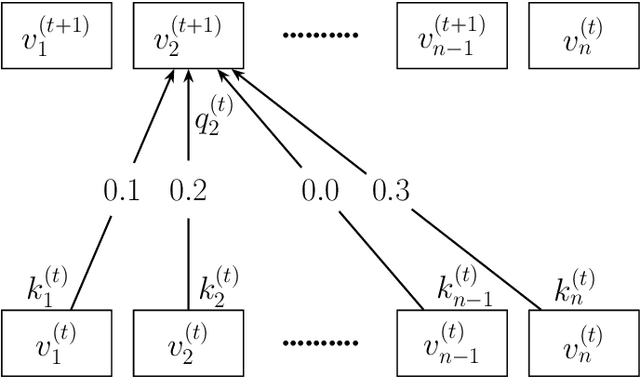
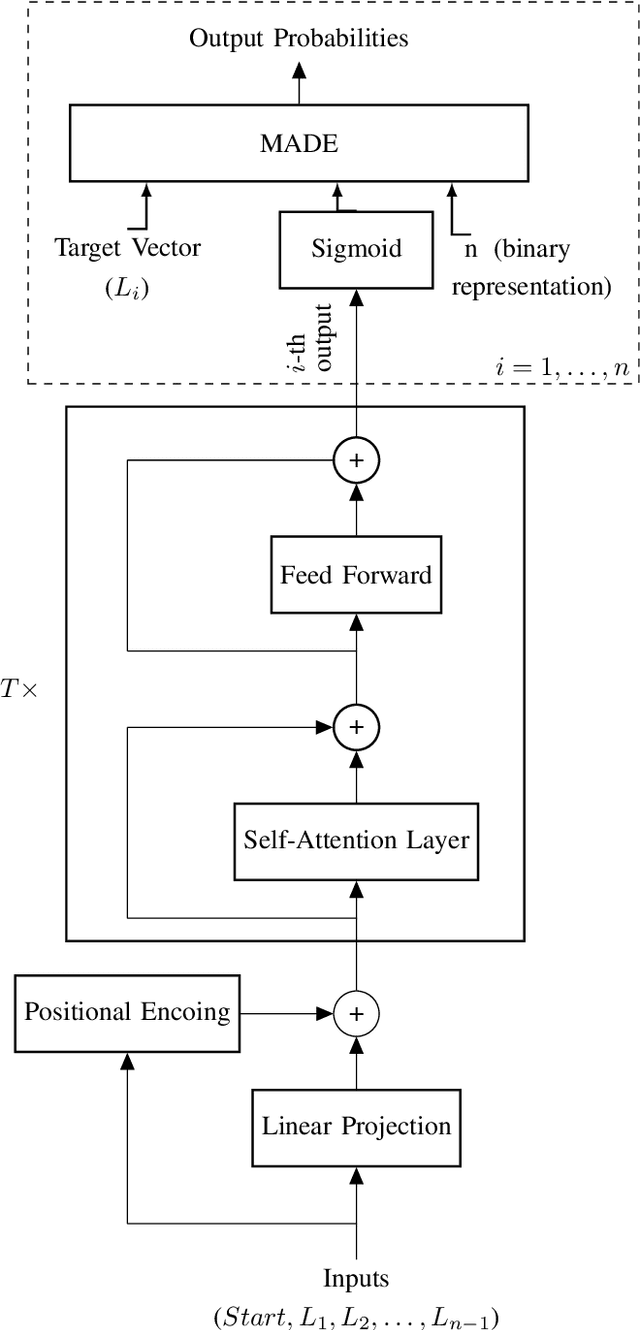
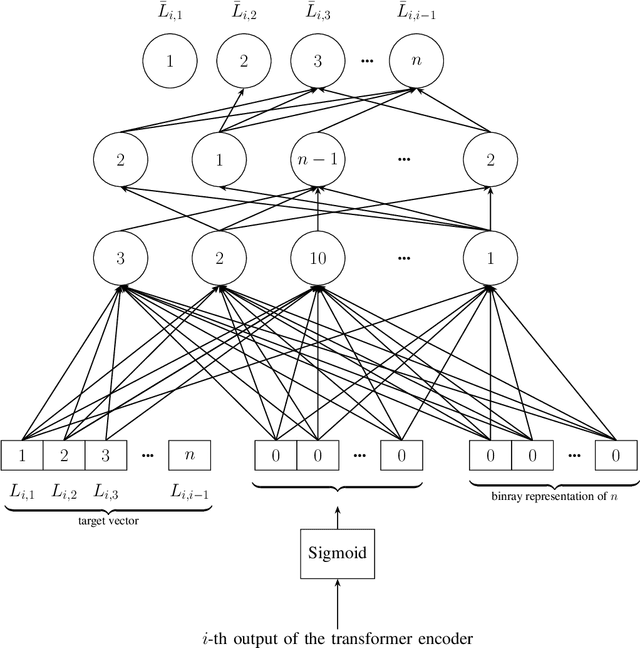

Transformers have become widely used in modern models for various tasks such as natural language processing and machine vision. This paper, proposes Gransformer, an algorithm for generating graphs that takes advantage of the transformer. We extend a simple autoregressive transformer encoder to exploit the structural information of the graph through efficient modifications. The attention mechanism is modified to consider the presence or absence of edges between each pair of nodes. We also introduce a graph-based familiarity measure that applies to both the attention and the positional coding. This autoregressive criterion, inspired by message passing algorithms, contains structural information about the graph. In the output layer, we also use a masked autoencoder for density estimation to efficiently model the generation of dependent edges. We also propose a technique to prevent the model from generating isolated nodes. We evaluate this method on two real-world datasets and compare it with some state-of-the-art autoregressive graph generation methods. Experimental results have shown that the proposed method performs comparative to these methods, including recurrent models and graph convolutional networks.
Disentangling Dynamics and Content for Control and Planning
Nov 24, 2017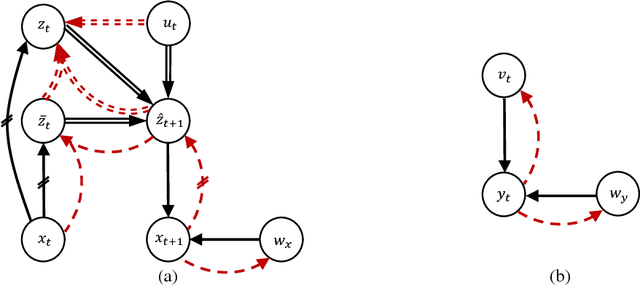
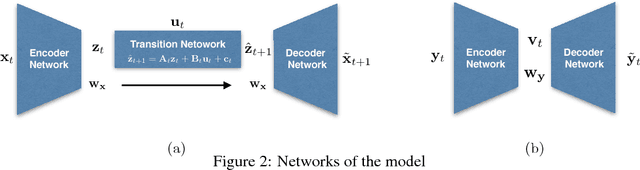
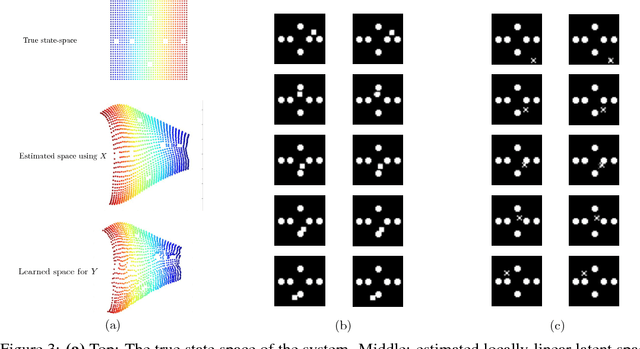
In this paper, We study the problem of learning a controllable representation for high-dimensional observations of dynamical systems. Specifically, we consider a situation where there are multiple sets of observations of dynamical systems with identical underlying dynamics. Only one of these sets has information about the effect of actions on the observation and the rest are just some random observations of the system. Our goal is to utilize the information in that one set and find a representation for the other sets that can be used for planning and ling-term prediction.
Patchwise Joint Sparse Tracking with Occlusion Detection
Feb 05, 2014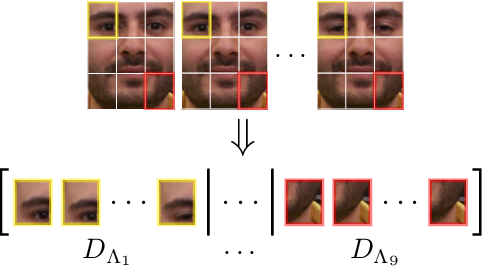
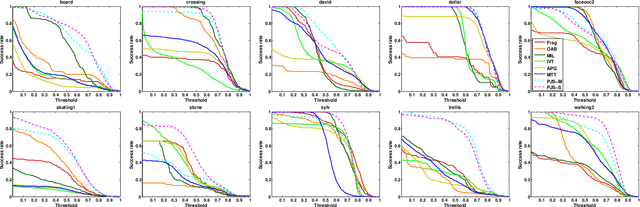
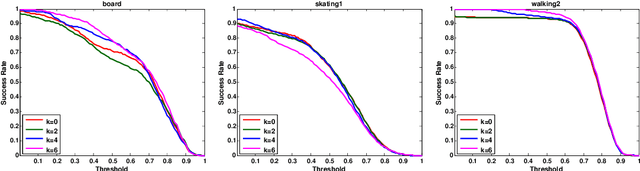
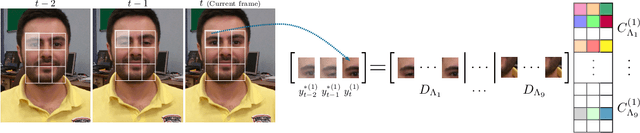
This paper presents a robust tracking approach to handle challenges such as occlusion and appearance change. Here, the target is partitioned into a number of patches. Then, the appearance of each patch is modeled using a dictionary composed of corresponding target patches in previous frames. In each frame, the target is found among a set of candidates generated by a particle filter, via a likelihood measure that is shown to be proportional to the sum of patch-reconstruction errors of each candidate. Since the target's appearance often changes slowly in a video sequence, it is assumed that the target in the current frame and the best candidates of a small number of previous frames, belong to a common subspace. This is imposed using joint sparse representation to enforce the target and previous best candidates to have a common sparsity pattern. Moreover, an occlusion detection scheme is proposed that uses patch-reconstruction errors and a prior probability of occlusion, extracted from an adaptive Markov chain, to calculate the probability of occlusion per patch. In each frame, occluded patches are excluded when updating the dictionary. Extensive experimental results on several challenging sequences shows that the proposed method outperforms state-of-the-art trackers.