 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGransformer: Transformer-based Graph Generation
Mar 25, 2022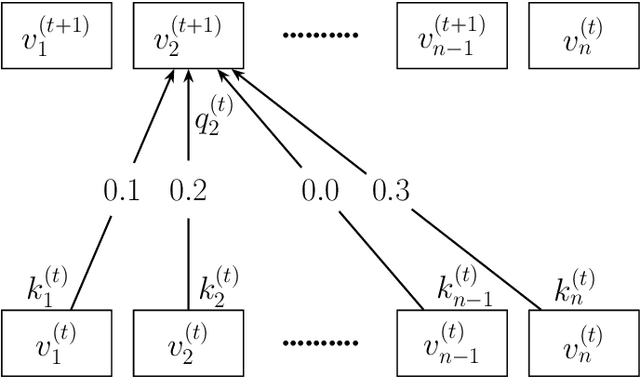
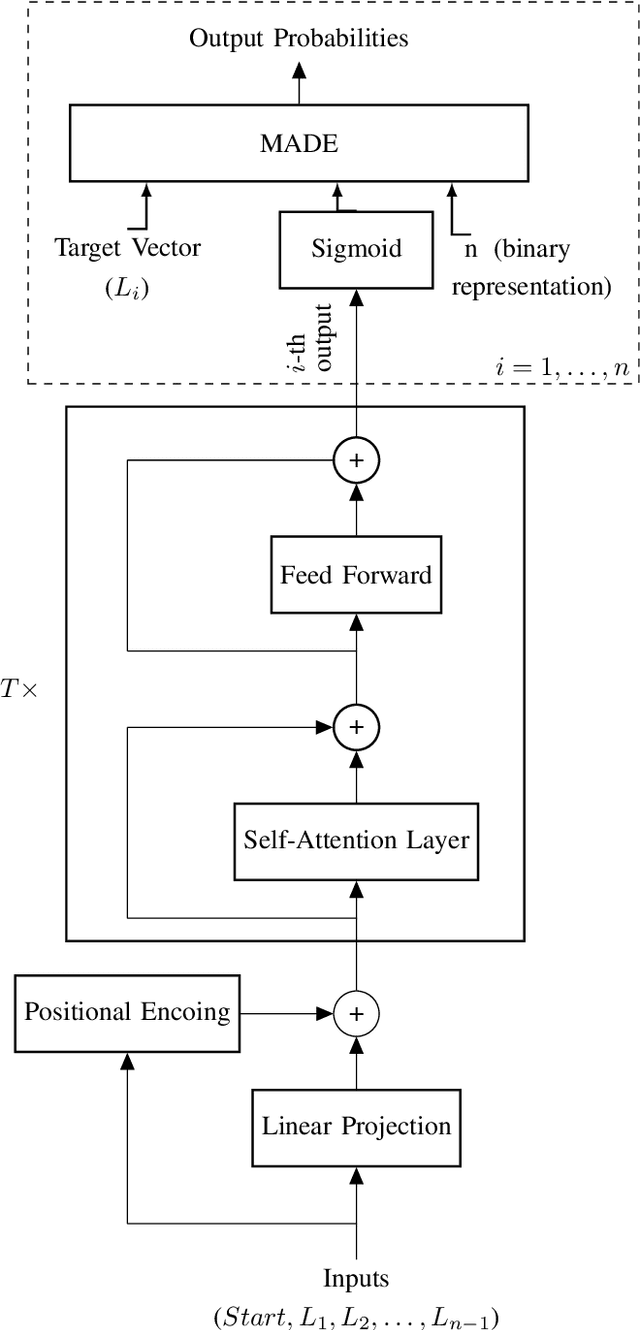
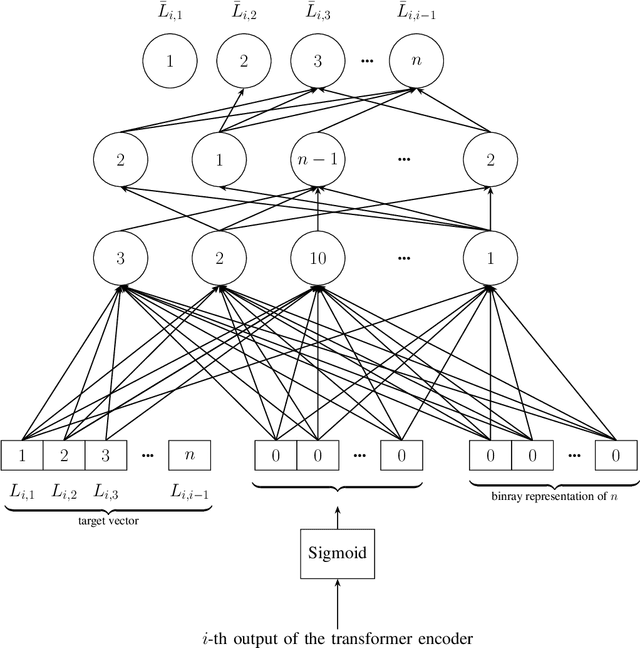

Transformers have become widely used in modern models for various tasks such as natural language processing and machine vision. This paper, proposes Gransformer, an algorithm for generating graphs that takes advantage of the transformer. We extend a simple autoregressive transformer encoder to exploit the structural information of the graph through efficient modifications. The attention mechanism is modified to consider the presence or absence of edges between each pair of nodes. We also introduce a graph-based familiarity measure that applies to both the attention and the positional coding. This autoregressive criterion, inspired by message passing algorithms, contains structural information about the graph. In the output layer, we also use a masked autoencoder for density estimation to efficiently model the generation of dependent edges. We also propose a technique to prevent the model from generating isolated nodes. We evaluate this method on two real-world datasets and compare it with some state-of-the-art autoregressive graph generation methods. Experimental results have shown that the proposed method performs comparative to these methods, including recurrent models and graph convolutional networks.
A Hybrid Deep Learning Architecture for Privacy-Preserving Mobile Analytics
Apr 18, 2018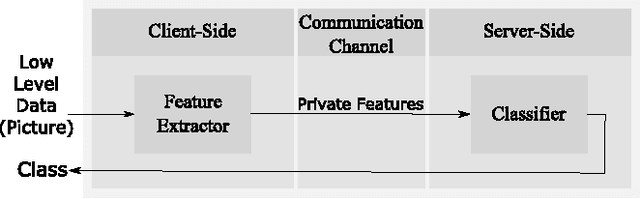
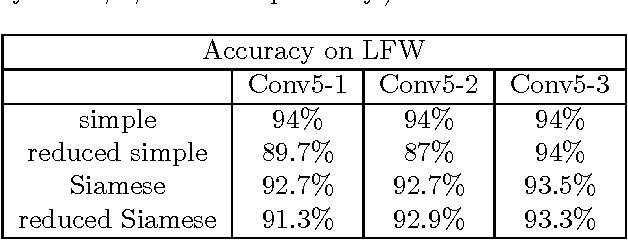
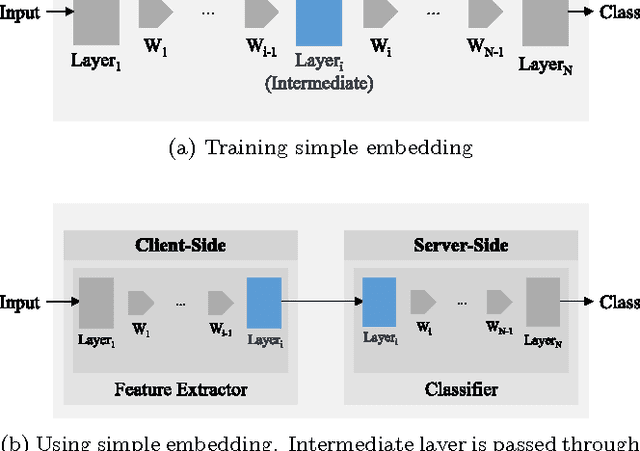
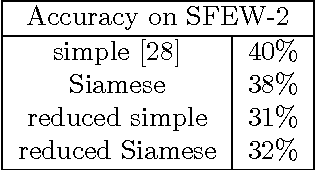
Deep Neural Networks are increasingly being used in a variety of machine learning applications applied to user data on the cloud. However, this approach introduces a number of privacy and efficiency challenges, as the cloud operator can perform secondary inferences on the available data. Recently, advances in edge processing have paved the way for more efficient, and private, data processing at the source for simple tasks and lighter models, though they remain a challenge for larger, and more complicated models. In this paper, we present a hybrid approach for breaking down large, complex deep models for cooperative, privacy-preserving analytics. We do this by breaking down the popular deep architectures and fine-tune them in a suitable way. We then evaluate the privacy benefits of this approach based on the information exposed to the cloud service. We also assess the local inference cost of different layers on a modern handset for mobile applications. Our evaluations show that by using certain kind of fine-tuning and embedding techniques and at a small processing cost, we can greatly reduce the level of information available to unintended tasks applied to the data features on the cloud, and hence achieving the desired tradeoff between privacy and performance.
Deep Private-Feature Extraction
Feb 28, 2018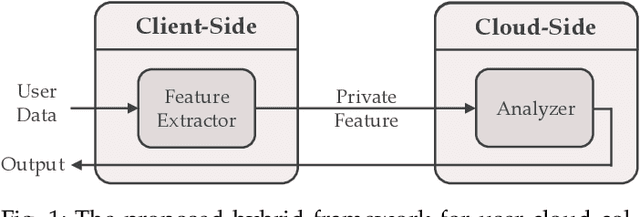

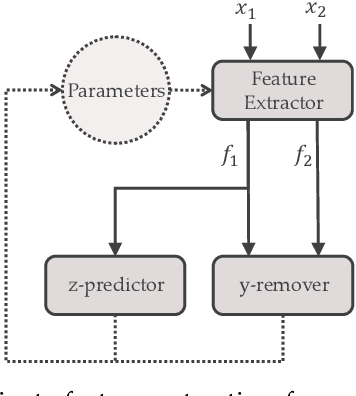
We present and evaluate Deep Private-Feature Extractor (DPFE), a deep model which is trained and evaluated based on information theoretic constraints. Using the selective exchange of information between a user's device and a service provider, DPFE enables the user to prevent certain sensitive information from being shared with a service provider, while allowing them to extract approved information using their model. We introduce and utilize the log-rank privacy, a novel measure to assess the effectiveness of DPFE in removing sensitive information and compare different models based on their accuracy-privacy tradeoff. We then implement and evaluate the performance of DPFE on smartphones to understand its complexity, resource demands, and efficiency tradeoffs. Our results on benchmark image datasets demonstrate that under moderate resource utilization, DPFE can achieve high accuracy for primary tasks while preserving the privacy of sensitive features.
Privacy-Preserving Deep Inference for Rich User Data on The Cloud
Oct 11, 2017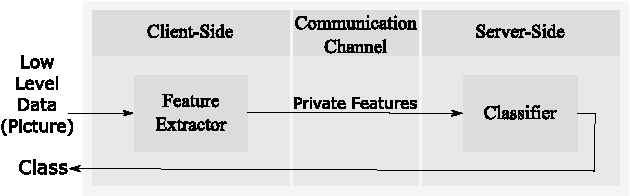

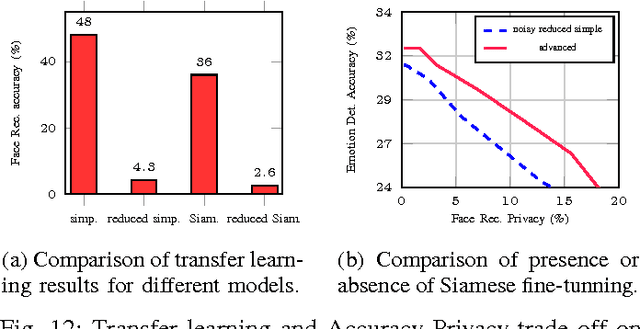
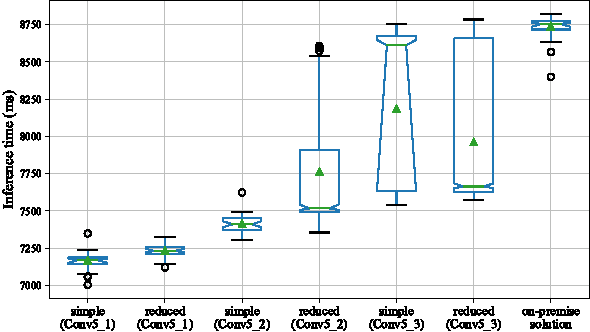
Deep neural networks are increasingly being used in a variety of machine learning applications applied to rich user data on the cloud. However, this approach introduces a number of privacy and efficiency challenges, as the cloud operator can perform secondary inferences on the available data. Recently, advances in edge processing have paved the way for more efficient, and private, data processing at the source for simple tasks and lighter models, though they remain a challenge for larger, and more complicated models. In this paper, we present a hybrid approach for breaking down large, complex deep models for cooperative, privacy-preserving analytics. We do this by breaking down the popular deep architectures and fine-tune them in a particular way. We then evaluate the privacy benefits of this approach based on the information exposed to the cloud service. We also asses the local inference cost of different layers on a modern handset for mobile applications. Our evaluations show that by using certain kind of fine-tuning and embedding techniques and at a small processing costs, we can greatly reduce the level of information available to unintended tasks applied to the data feature on the cloud, and hence achieving the desired tradeoff between privacy and performance.
Kissing Cuisines: Exploring Worldwide Culinary Habits on the Web
Apr 25, 2017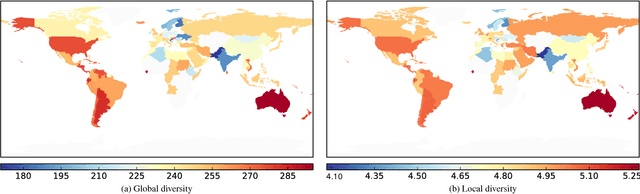
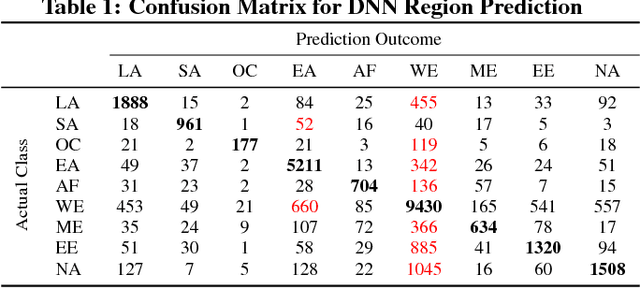
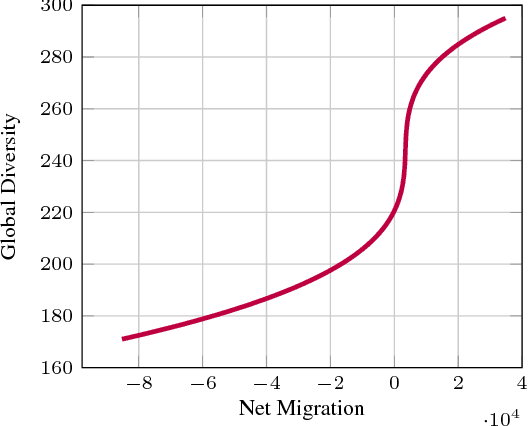
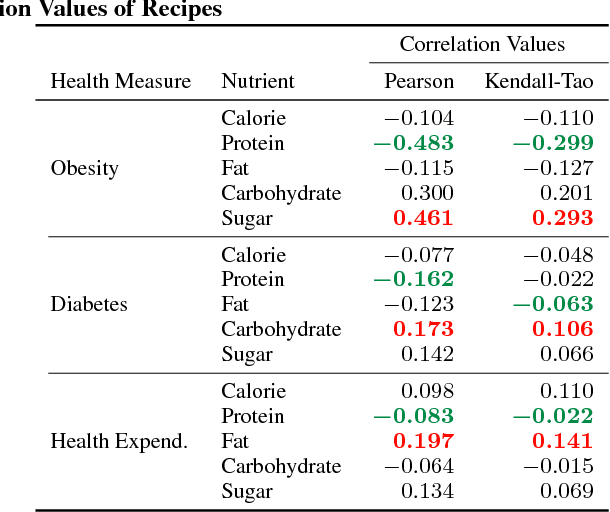
Food and nutrition occupy an increasingly prevalent space on the web, and dishes and recipes shared online provide an invaluable mirror into culinary cultures and attitudes around the world. More specifically, ingredients, flavors, and nutrition information become strong signals of the taste preferences of individuals and civilizations. However, there is little understanding of these palate varieties. In this paper, we present a large-scale study of recipes published on the web and their content, aiming to understand cuisines and culinary habits around the world. Using a database of more than 157K recipes from over 200 different cuisines, we analyze ingredients, flavors, and nutritional values which distinguish dishes from different regions, and use this knowledge to assess the predictability of recipes from different cuisines. We then use country health statistics to understand the relation between these factors and health indicators of different nations, such as obesity, diabetes, migration, and health expenditure. Our results confirm the strong effects of geographical and cultural similarities on recipes, health indicators, and culinary preferences across the globe.