 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBarrierBench : Evaluating Large Language Models for Safety Verification in Dynamical Systems
Nov 12, 2025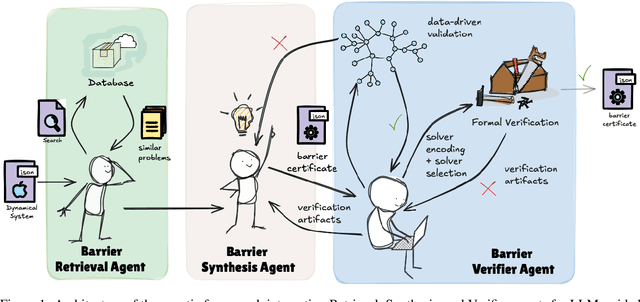



Safety verification of dynamical systems via barrier certificates is essential for ensuring correctness in autonomous applications. Synthesizing these certificates involves discovering mathematical functions with current methods suffering from poor scalability, dependence on carefully designed templates, and exhaustive or incremental function-space searches. They also demand substantial manual expertise--selecting templates, solvers, and hyperparameters, and designing sampling strategies--requiring both theoretical and practical knowledge traditionally shared through linguistic reasoning rather than formalized methods. This motivates a key question: can such expert reasoning be captured and operationalized by language models? We address this by introducing an LLM-based agentic framework for barrier certificate synthesis. The framework uses natural language reasoning to propose, refine, and validate candidate certificates, integrating LLM-driven template discovery with SMT-based verification, and supporting barrier-controller co-synthesis to ensure consistency between safety certificates and controllers. To evaluate this capability, we introduce BarrierBench, a benchmark of 100 dynamical systems spanning linear, nonlinear, discrete-time, and continuous-time settings. Our experiments assess not only the effectiveness of LLM-guided barrier synthesis but also the utility of retrieval-augmented generation and agentic coordination strategies in improving its reliability and performance. Across these tasks, the framework achieves more than 90% success in generating valid certificates. By releasing BarrierBench and the accompanying toolchain, we aim to establish a community testbed for advancing the integration of language-based reasoning with formal verification in dynamical systems. The benchmark is publicly available at https://hycodev.com/dataset/barrierbench
Machine Learning Interpretability Meets TLS Fingerprinting
Nov 12, 2020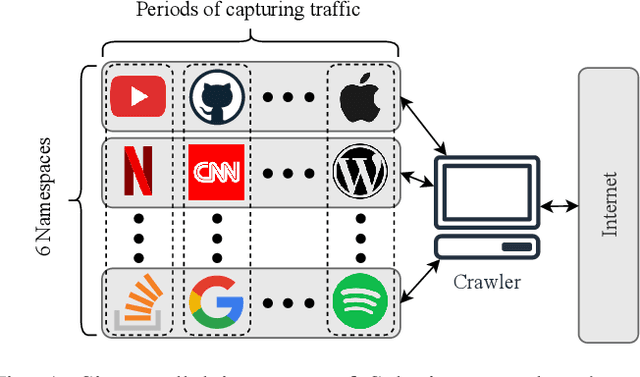
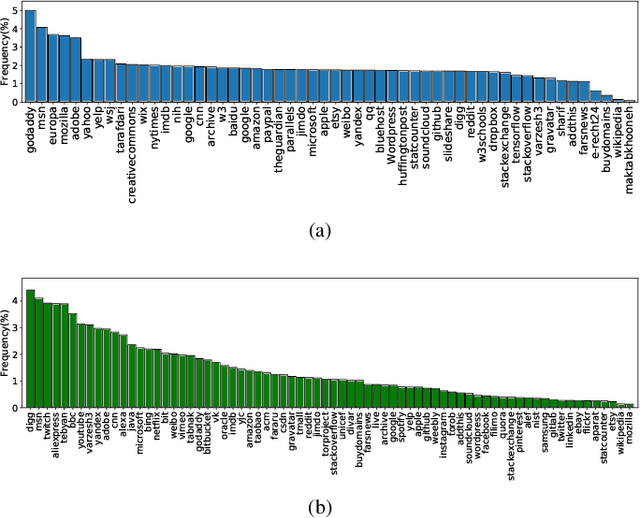
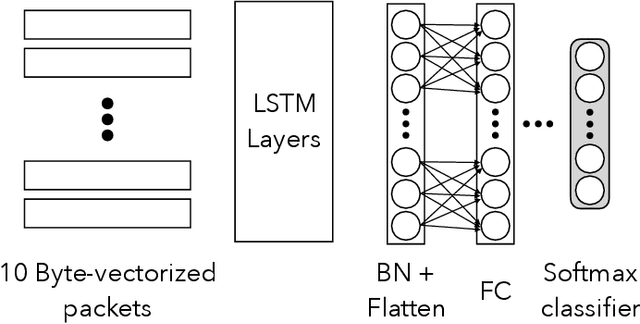
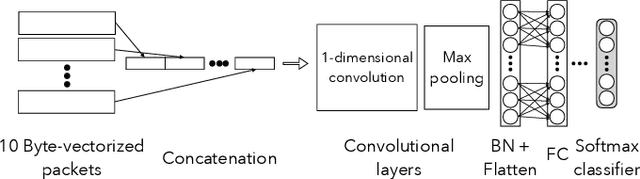
Protecting users' privacy over the Internet is of great importance. However, due to the increasing complexity of network protocols and components, it becomes harder and harder to maintain. Therefore, investigating and understanding how data is leaked from the information transport platform/protocols can lead us to a more secure environment. In this paper, we propose an iterative framework to find the most vulnerable information fields in a network protocol systematically. To this end, focusing on the Transport Layer Security (TLS) protocol, we perform different machine-learning-based fingerprinting attacks by collecting data from more than 70 domains (websites) to understand how and where this information leakage occurs in the TLS protocol. Then, by employing the interpretation techniques developed in the machine learning community, and using our framework, we find the most vulnerable information fields in the TLS protocol. Our findings demonstrate that the TLS handshake (which is mainly unencrypted), the TLS record length appears in the TLS application data header, and the initialization vector (IV) field are among the most critical leaker parts in this protocol, respectively.
A Hybrid Deep Learning Architecture for Privacy-Preserving Mobile Analytics
Apr 18, 2018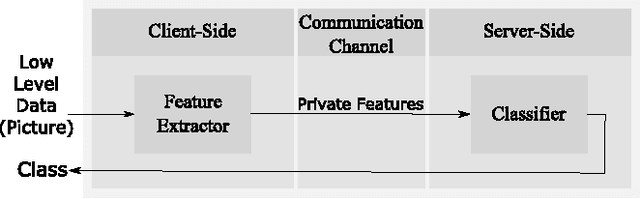
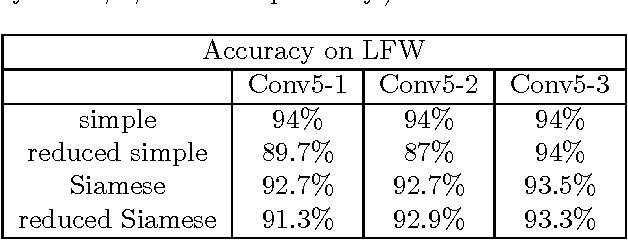
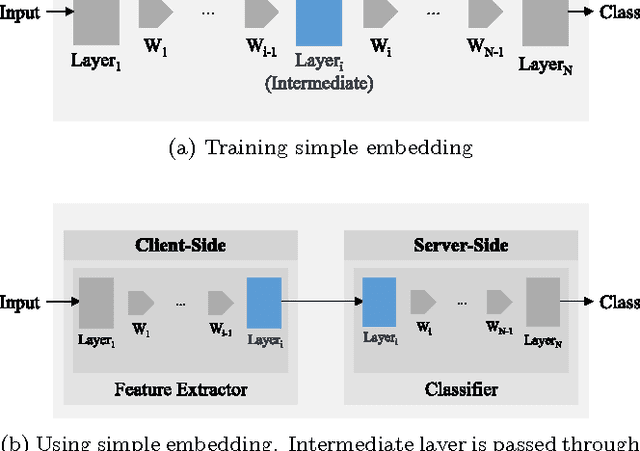
Deep Neural Networks are increasingly being used in a variety of machine learning applications applied to user data on the cloud. However, this approach introduces a number of privacy and efficiency challenges, as the cloud operator can perform secondary inferences on the available data. Recently, advances in edge processing have paved the way for more efficient, and private, data processing at the source for simple tasks and lighter models, though they remain a challenge for larger, and more complicated models. In this paper, we present a hybrid approach for breaking down large, complex deep models for cooperative, privacy-preserving analytics. We do this by breaking down the popular deep architectures and fine-tune them in a suitable way. We then evaluate the privacy benefits of this approach based on the information exposed to the cloud service. We also assess the local inference cost of different layers on a modern handset for mobile applications. Our evaluations show that by using certain kind of fine-tuning and embedding techniques and at a small processing cost, we can greatly reduce the level of information available to unintended tasks applied to the data features on the cloud, and hence achieving the desired tradeoff between privacy and performance.
Deep Private-Feature Extraction
Feb 28, 2018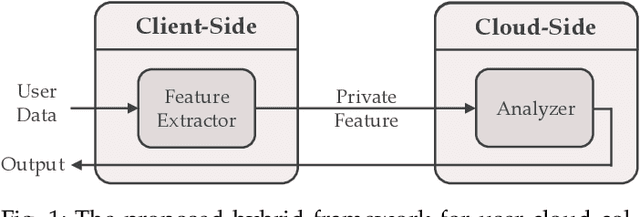

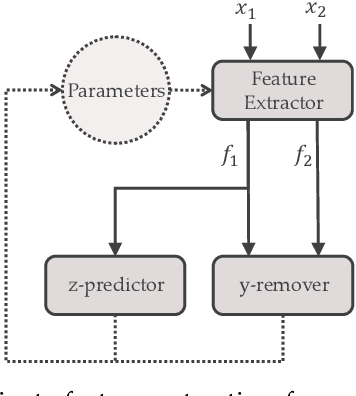
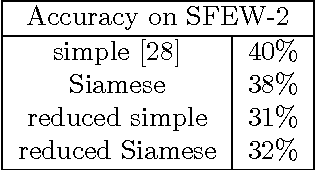
We present and evaluate Deep Private-Feature Extractor (DPFE), a deep model which is trained and evaluated based on information theoretic constraints. Using the selective exchange of information between a user's device and a service provider, DPFE enables the user to prevent certain sensitive information from being shared with a service provider, while allowing them to extract approved information using their model. We introduce and utilize the log-rank privacy, a novel measure to assess the effectiveness of DPFE in removing sensitive information and compare different models based on their accuracy-privacy tradeoff. We then implement and evaluate the performance of DPFE on smartphones to understand its complexity, resource demands, and efficiency tradeoffs. Our results on benchmark image datasets demonstrate that under moderate resource utilization, DPFE can achieve high accuracy for primary tasks while preserving the privacy of sensitive features.
Privacy-Preserving Deep Inference for Rich User Data on The Cloud
Oct 11, 2017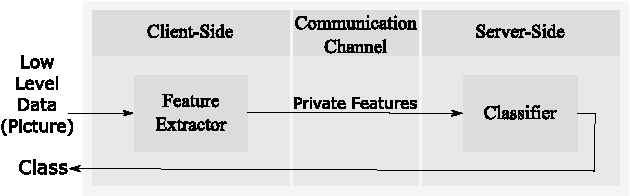

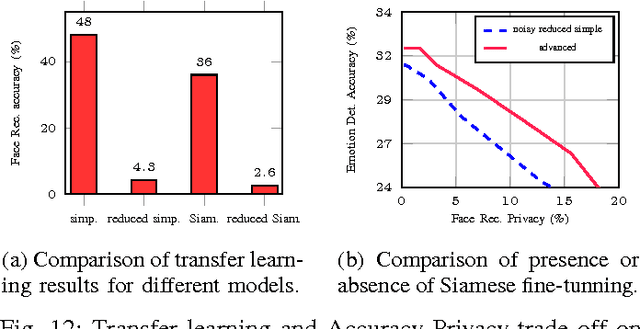
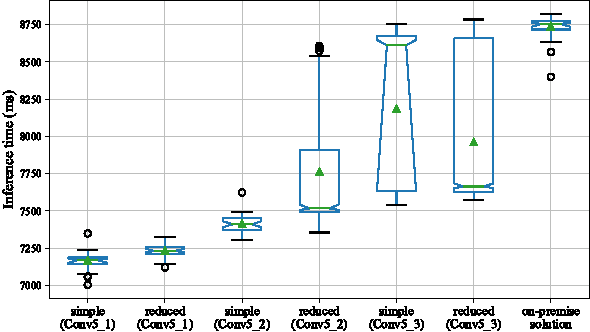
Deep neural networks are increasingly being used in a variety of machine learning applications applied to rich user data on the cloud. However, this approach introduces a number of privacy and efficiency challenges, as the cloud operator can perform secondary inferences on the available data. Recently, advances in edge processing have paved the way for more efficient, and private, data processing at the source for simple tasks and lighter models, though they remain a challenge for larger, and more complicated models. In this paper, we present a hybrid approach for breaking down large, complex deep models for cooperative, privacy-preserving analytics. We do this by breaking down the popular deep architectures and fine-tune them in a particular way. We then evaluate the privacy benefits of this approach based on the information exposed to the cloud service. We also asses the local inference cost of different layers on a modern handset for mobile applications. Our evaluations show that by using certain kind of fine-tuning and embedding techniques and at a small processing costs, we can greatly reduce the level of information available to unintended tasks applied to the data feature on the cloud, and hence achieving the desired tradeoff between privacy and performance.