 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization and Membership Inference Attack a Practical Perspective
Apr 21, 2026With the emergence of new evaluation metrics and attack methodologies for Membership Inference Attacks (MIA), it becomes essential to reevaluate previously accepted assumptions. In this paper, we revisit the longstanding debate regarding the correlation between MIA success rates and model generalization using an empirical approach. We focused on employing augmentation techniques and early stopping to enhance model generalization and examined their impact on MIA success rates. We found that utilizing advanced generalization techniques can significantly decrease attack performance, potentially by up to 100 times. Moreover, combining these methods not only improves model generalization but also reduces attack effectiveness by introducing randomness during training. Additionally, our study confirmed the direct impact of generalization on MIA performance through an analysis of over 1K models in a controlled environment.
Wiring the 'Why': A Unified Taxonomy and Survey of Abductive Reasoning in LLMs
Apr 09, 2026Regardless of its foundational role in human discovery and sense-making, abductive reasoning--the inference of the most plausible explanation for an observation--has been relatively underexplored in Large Language Models (LLMs). Despite the rapid advancement of LLMs, the exploration of abductive reasoning and its diverse facets has thus far been disjointed rather than cohesive. This paper presents the first survey of abductive reasoning in LLMs, tracing its trajectory from philosophical foundations to contemporary AI implementations. To address the widespread conceptual confusion and disjointed task definitions prevalent in the field, we establish a unified two-stage definition that formally categorizes prior work. This definition disentangles abduction into \textit{Hypothesis Generation}, where models bridge epistemic gaps to produce candidate explanations, and \textit{Hypothesis Selection}, where the generated candidates are evaluated and the most plausible explanation is chosen. Building upon this foundation, we present a comprehensive taxonomy of the literature, categorizing prior work based on their abductive tasks, datasets, underlying methodologies, and evaluation strategies. In order to ground our framework empirically, we conduct a compact benchmark study of current LLMs on abductive tasks, together with targeted comparative analyses across model sizes, model families, evaluation styles, and the distinct generation-versus-selection task typologies. Moreover, by synthesizing recent empirical results, we examine how LLM performance on abductive reasoning relates to deductive and inductive tasks, providing insights into their broader reasoning capabilities. Our analysis reveals critical gaps in current approaches--from static benchmark design and narrow domain coverage to narrow training frameworks and limited mechanistic understanding of abductive processes...
A Hybrid TGN-SEAL Model for Dynamic Graph Link Prediction
Feb 15, 2026Predicting links in sparse, continuously evolving networks is a central challenge in network science. Conventional heuristic methods and deep learning models, including Graph Neural Networks (GNNs), are typically designed for static graphs and thus struggle to capture temporal dependencies. Snapshot-based techniques partially address this issue but often encounter data sparsity and class imbalance, particularly in networks with transient interactions such as telecommunication call detail records (CDRs). Temporal Graph Networks (TGNs) model dynamic graphs by updating node embeddings over time; however, their predictive accuracy under sparse conditions remains limited. In this study, we improve the TGN framework by extracting enclosing subgraphs around candidate links, enabling the model to jointly learn structural and temporal information. Experiments on a sparse CDR dataset show that our approach increases average precision by 2.6% over standard TGNs, demonstrating the advantages of integrating local topology for robust link prediction in dynamic networks.
Extended Deep Submodular Functions
Sep 18, 2024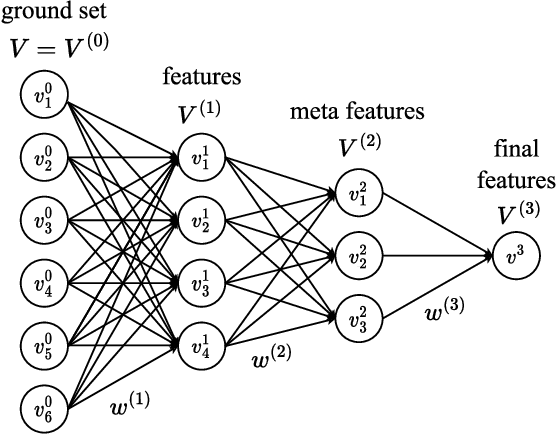
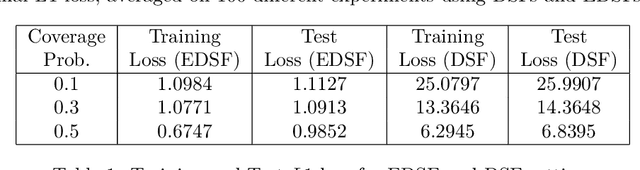
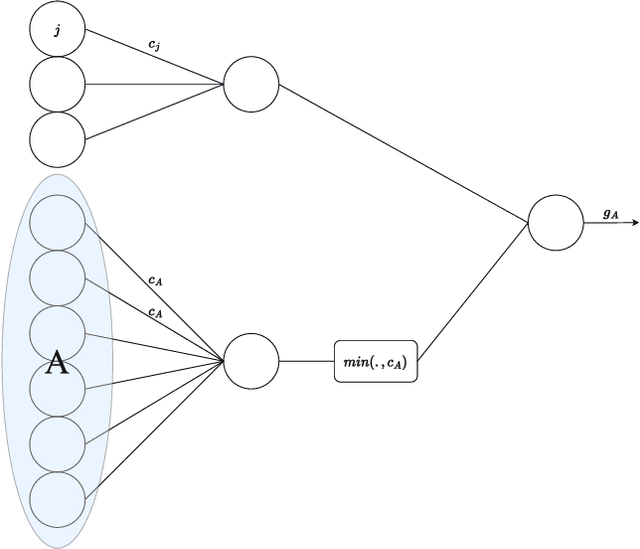
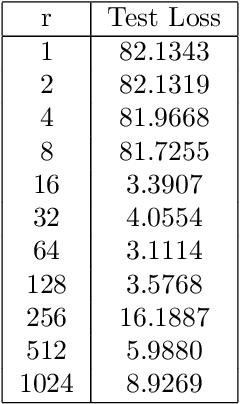
We introduce a novel category of set functions called Extended Deep Submodular functions (EDSFs), which are neural network-representable. EDSFs serve as an extension of Deep Submodular Functions (DSFs), inheriting crucial properties from DSFs while addressing innate limitations. It is known that DSFs can represent a limiting subset of submodular functions. In contrast, through an analysis of polymatroid properties, we establish that EDSFs possess the capability to represent all monotone submodular functions, a notable enhancement compared to DSFs. Furthermore, our findings demonstrate that EDSFs can represent any monotone set function, indicating the family of EDSFs is equivalent to the family of all monotone set functions. Additionally, we prove that EDSFs maintain the concavity inherent in DSFs when the components of the input vector are non-negative real numbers-an essential feature in certain combinatorial optimization problems. Through extensive experiments, we illustrate that EDSFs exhibit significantly lower empirical generalization error than DSFs in the learning of coverage functions. This suggests that EDSFs present a promising advancement in the representation and learning of set functions with improved generalization capabilities.
An Adaptable Deep Learning-Based Intrusion Detection System to Zero-Day Attacks
Aug 20, 2021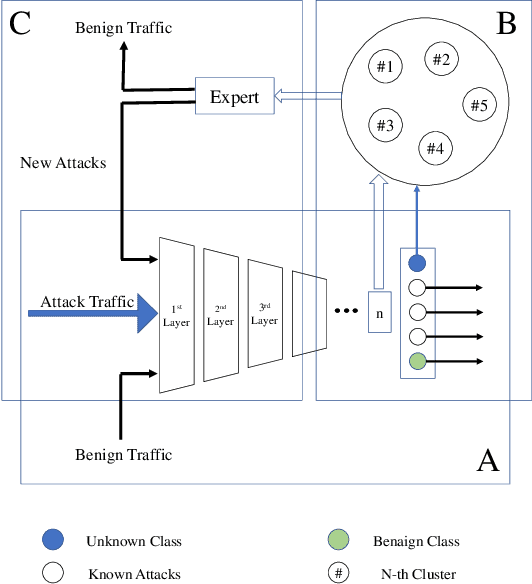
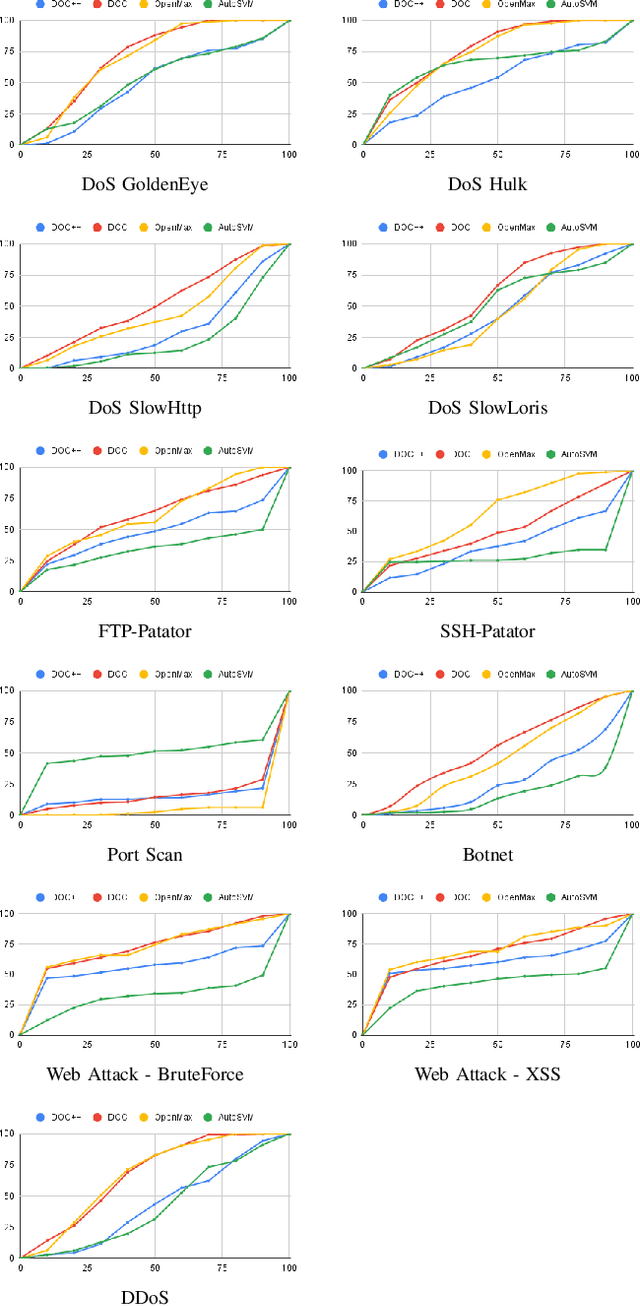
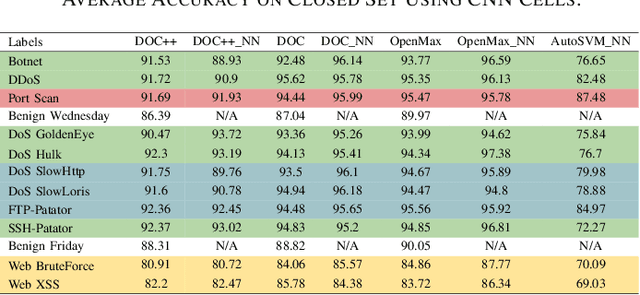
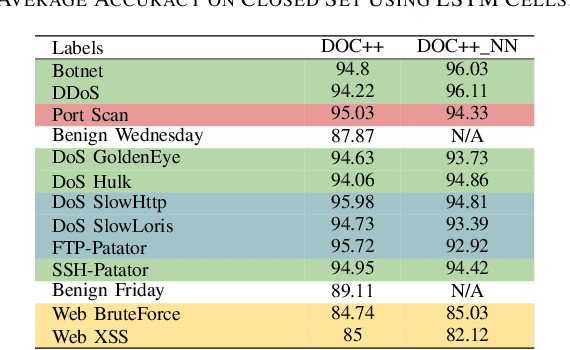
The intrusion detection system (IDS) is an essential element of security monitoring in computer networks. An IDS distinguishes the malicious traffic from the benign one and determines the attack types targeting the assets of the organization. The main challenge of an IDS is facing new (i.e., zero-day) attacks and separating them from benign traffic and existing types of attacks. Along with the power of the deep learning-based IDSes in auto-extracting high-level features and its independence from the time-consuming and costly signature extraction process, the mentioned challenge still exists in this new generation of IDSes. In this paper, we propose a framework for deep learning-based IDSes addressing new attacks. This framework is the first approach using both deep novelty-based classifiers besides the traditional clustering based on the specialized layer of deep structures, in the security scope. Additionally, we introduce DOC++ as a newer version of DOC as a deep novelty-based classifier. We also employ the Deep Intrusion Detection (DID) framework for the preprocessing phase, which improves the ability of deep learning algorithms to detect content-based attacks. We compare four different algorithms (including DOC, DOC++, OpenMax, and AutoSVM) as the novelty classifier of the framework and use both the CIC-IDS2017 and CSE-CIC-IDS2018 datasets for the evaluation. Our results show that DOC++ is the best implementation of the open set recognition module. Besides, the completeness and homogeneity of the clustering and post-training phase prove that this model is good enough for the supervised labeling and updating phase.
Machine Learning Interpretability Meets TLS Fingerprinting
Nov 12, 2020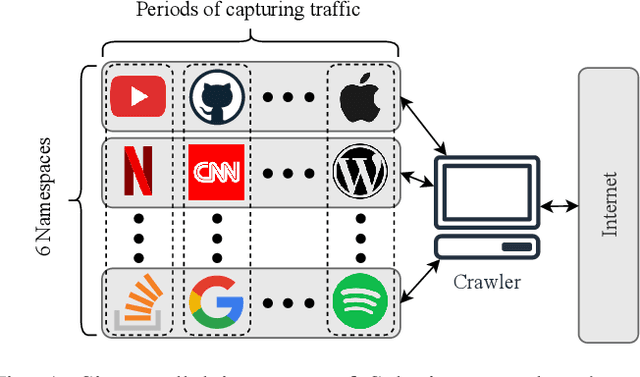
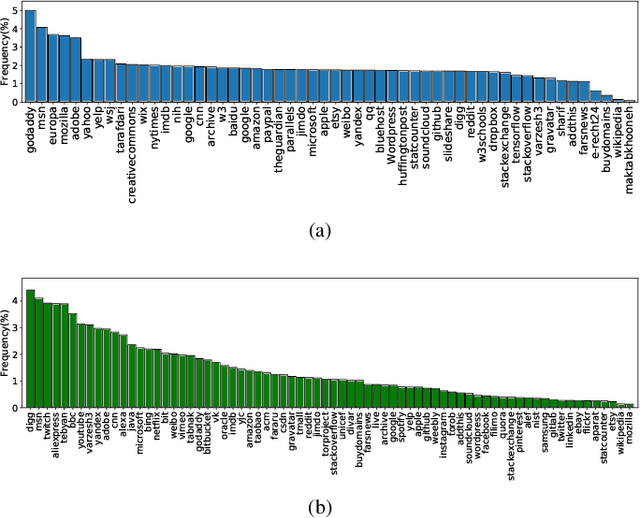
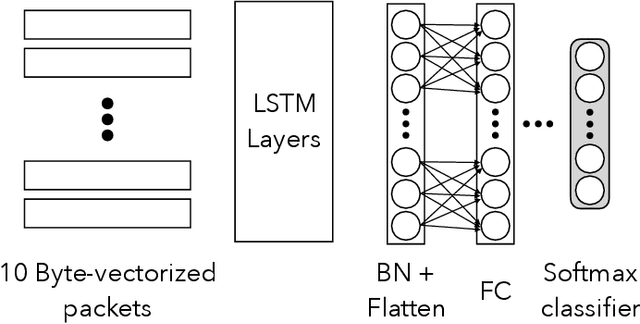
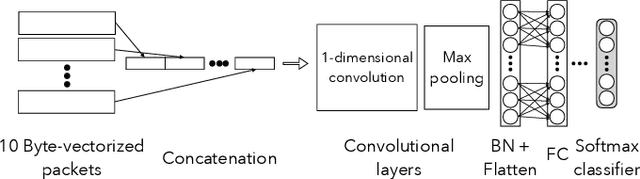
Protecting users' privacy over the Internet is of great importance. However, due to the increasing complexity of network protocols and components, it becomes harder and harder to maintain. Therefore, investigating and understanding how data is leaked from the information transport platform/protocols can lead us to a more secure environment. In this paper, we propose an iterative framework to find the most vulnerable information fields in a network protocol systematically. To this end, focusing on the Transport Layer Security (TLS) protocol, we perform different machine-learning-based fingerprinting attacks by collecting data from more than 70 domains (websites) to understand how and where this information leakage occurs in the TLS protocol. Then, by employing the interpretation techniques developed in the machine learning community, and using our framework, we find the most vulnerable information fields in the TLS protocol. Our findings demonstrate that the TLS handshake (which is mainly unencrypted), the TLS record length appears in the TLS application data header, and the initialization vector (IV) field are among the most critical leaker parts in this protocol, respectively.
A Variational Auto-Encoder Approach for Image Transmission in Wireless Channel
Oct 08, 2020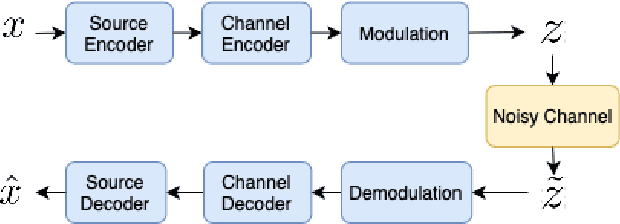
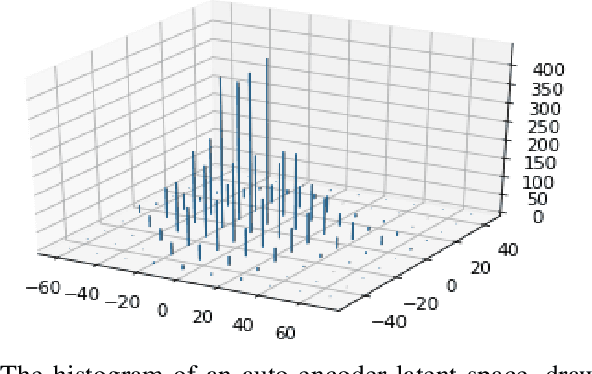
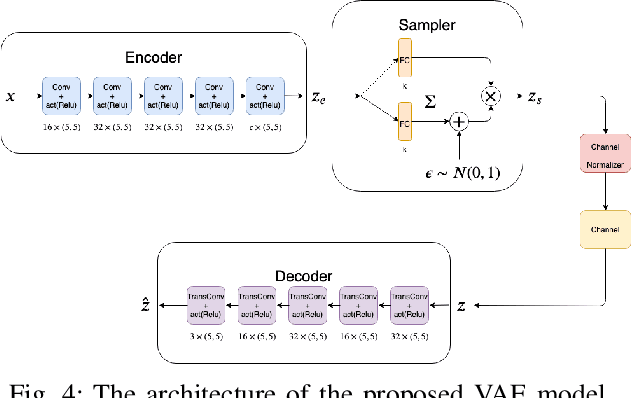
Recent advancements in information technology and the widespread use of the Internet have led to easier access to data worldwide. As a result, transmitting data through noisy channels is inevitable. Reducing the size of data and protecting it during transmission from corruption due to channel noises are two classical problems in communication and information theory. Recently, inspired by deep neural networks' success in different tasks, many works have been done to address these two problems using deep learning techniques. In this paper, we investigate the performance of variational auto-encoders and compare the results with standard auto-encoders. Our findings suggest that variational auto-encoders are more robust to channel degradation than auto-encoders. Furthermore, we have tried to excel in the human perceptual quality of reconstructed images by using perception-based error metrics as our network's loss function. To this end, we use the structural similarity index (SSIM) as a perception-based metric to optimize the proposed neural network. Our experiments demonstrate that the SSIM metric visually improves the quality of the reconstructed images at the receiver.
On Multi-Session Website Fingerprinting over TLS Handshake
Sep 19, 2020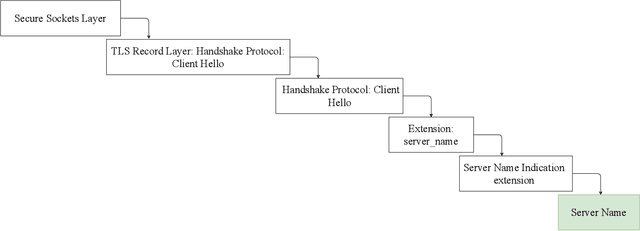


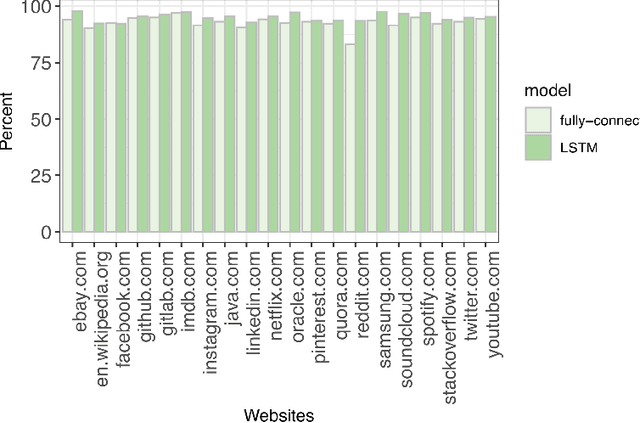
Analyzing users' Internet traffic data and activities has a certain impact on users' experiences in different ways, from maintaining the quality of service on the Internet and providing users with high-quality recommendation systems to anomaly detection and secure connection. Considering that the Internet is a complex network, we cannot disintegrate the packets for each activity. Therefore we have to have a model that can identify all the activities an Internet user does in a given period of time. In this paper, we propose a deep learning approach to generate a multi-label classifier that can predict the websites visited by a user in a certain period. This model works by extracting the server names appearing in chronological order in the TLSv1.2 and TLSv1.3 Client Hello packets. We compare the results on the test data with a simple fully-connected neural network developed for the same purpose to prove that using the time-sequential information improves the performance. For further evaluations, we test the model on a human-made dataset and a modified dataset to check the model's accuracy under different circumstances. Finally, our proposed model achieved an accuracy of 95% on the test dataset and above 90% on both the modified dataset and the human-made dataset.
A Content-Based Deep Intrusion Detection System
Jan 14, 2020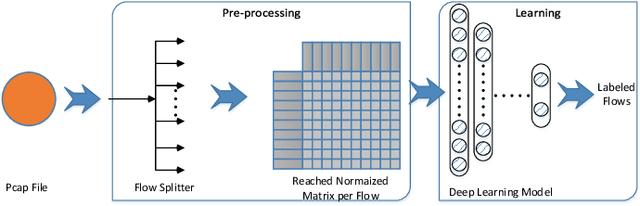

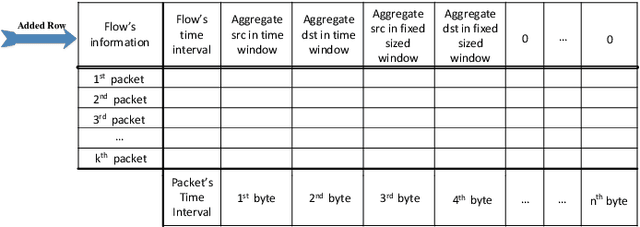
By growing the number of Internet users and the prevalence of web applications, we have to deal with very complex software and applications in the network. This results in an increasing number of new vulnerabilities in the systems, which consequently leads to an increase in the cyber and, in particular, zero-day attacks. The cost of generating appropriate signatures for these attacks is a potential motive for using machine learning-based methodologies. Although there exist many studies on the use of learning-based methods for attack detection, they generally use extracted features and overlook raw contents. This approach can lessen the performance of detection systems against content-based attacks like SQL injection, Cross-site Scripting (XSS), and various viruses. As a new paradigm, in this work, we propose a scheme, called deep intrusion detection (DID) system that uses the pure content of traffic flows in addition to traffic metadata in the learning and detection phases. To this end, we employ deep learning techniques recently developed in the machine learning community. Due to the inherent nature of deep learning, it can process high dimensional data content and, accordingly, discover the sophisticated relations between the auto extracted features of the traffic. To evaluate the proposed DID system, we use the ISCX IDS 2017 dataset. The evaluation metrics, such as precision and recall, reach $0.992$ and $0.998$, respectively, which show the high performance of the proposed DID method.
Adaptive Online Learning for Gradient-Based Optimizers
Jun 01, 2019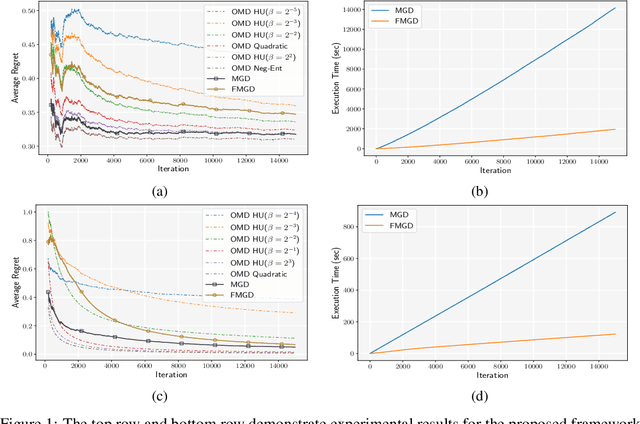
As application demands for online convex optimization accelerate, the need for designing new methods that simultaneously cover a large class of convex functions and impose the lowest possible regret is highly rising. Known online optimization methods usually perform well only in specific settings, and their performance depends highly on the geometry of the decision space and cost functions. However, in practice, lack of such geometric information leads to confusion in using the appropriate algorithm. To address this issue, some adaptive methods have been proposed that focus on adaptively learning parameters such as step size, Lipschitz constant, and strong convexity coefficient, or on specific parametric families such as quadratic regularizers. In this work, we generalize these methods and propose a framework that competes with the best algorithm in a family of expert algorithms. Our framework includes many of the well-known adaptive methods including MetaGrad, MetaGrad+C, and Ader. We also introduce a second algorithm that computationally outperforms our first algorithm with at most a constant factor increase in regret. Finally, as a representative application of our proposed algorithm, we study the problem of learning the best regularizer from a family of regularizers for Online Mirror Descent. Empirically, we support our theoretical findings in the problem of learning the best regularizer on the simplex and $l_2$-ball in a multiclass learning problem.