 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatchwise Joint Sparse Tracking with Occlusion Detection
Feb 05, 2014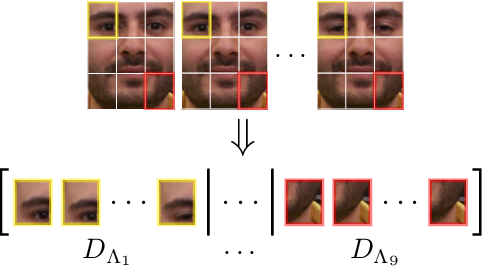
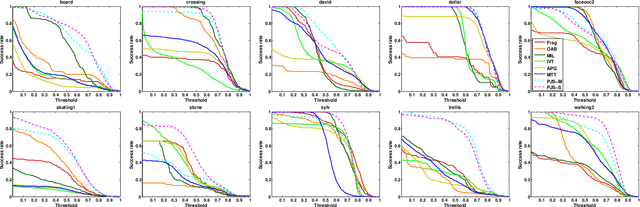
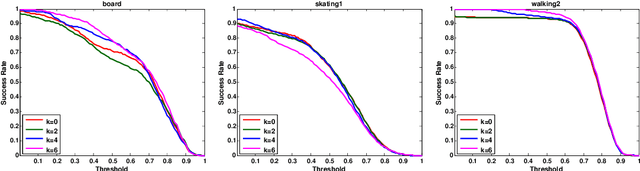
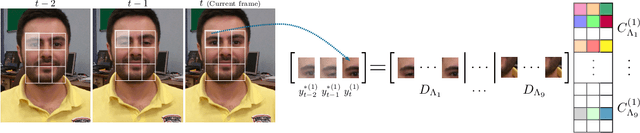
This paper presents a robust tracking approach to handle challenges such as occlusion and appearance change. Here, the target is partitioned into a number of patches. Then, the appearance of each patch is modeled using a dictionary composed of corresponding target patches in previous frames. In each frame, the target is found among a set of candidates generated by a particle filter, via a likelihood measure that is shown to be proportional to the sum of patch-reconstruction errors of each candidate. Since the target's appearance often changes slowly in a video sequence, it is assumed that the target in the current frame and the best candidates of a small number of previous frames, belong to a common subspace. This is imposed using joint sparse representation to enforce the target and previous best candidates to have a common sparsity pattern. Moreover, an occlusion detection scheme is proposed that uses patch-reconstruction errors and a prior probability of occlusion, extracted from an adaptive Markov chain, to calculate the probability of occlusion per patch. In each frame, occluded patches are excluded when updating the dictionary. Extensive experimental results on several challenging sequences shows that the proposed method outperforms state-of-the-art trackers.
Spatial-Aware Dictionary Learning for Hyperspectral Image Classification
Aug 06, 2013


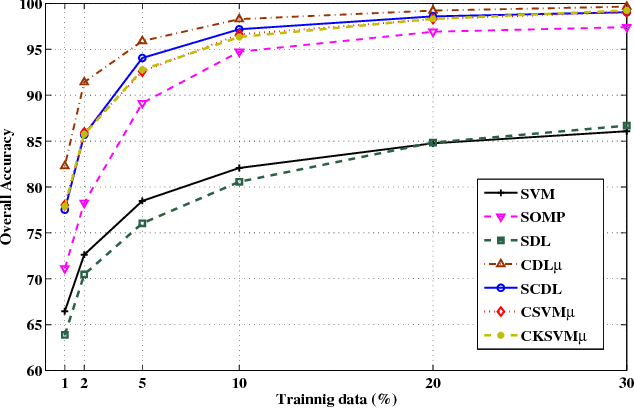
This paper presents a structured dictionary-based model for hyperspectral data that incorporates both spectral and contextual characteristics of a spectral sample, with the goal of hyperspectral image classification. The idea is to partition the pixels of a hyperspectral image into a number of spatial neighborhoods called contextual groups and to model each pixel with a linear combination of a few dictionary elements learned from the data. Since pixels inside a contextual group are often made up of the same materials, their linear combinations are constrained to use common elements from the dictionary. To this end, dictionary learning is carried out with a joint sparse regularizer to induce a common sparsity pattern in the sparse coefficients of each contextual group. The sparse coefficients are then used for classification using a linear SVM. Experimental results on a number of real hyperspectral images confirm the effectiveness of the proposed representation for hyperspectral image classification. Moreover, experiments with simulated multispectral data show that the proposed model is capable of finding representations that may effectively be used for classification of multispectral-resolution samples.