 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Average-Reward Linearly-solvable Markov Decision Processes
Jul 09, 2024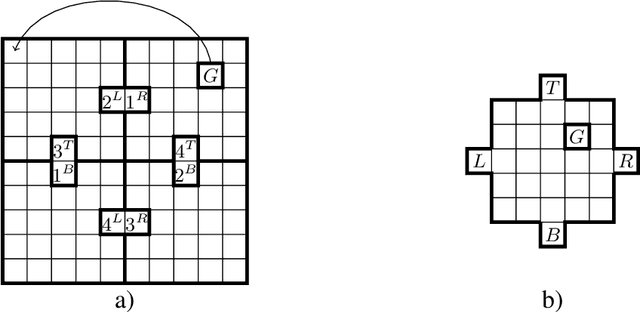
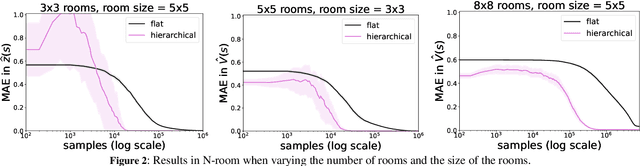
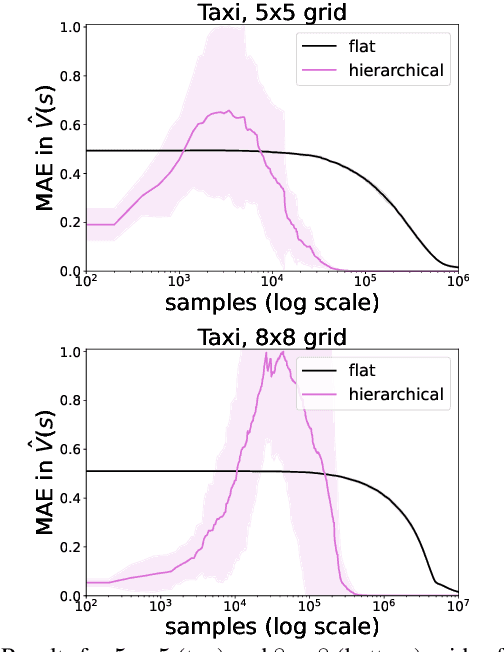
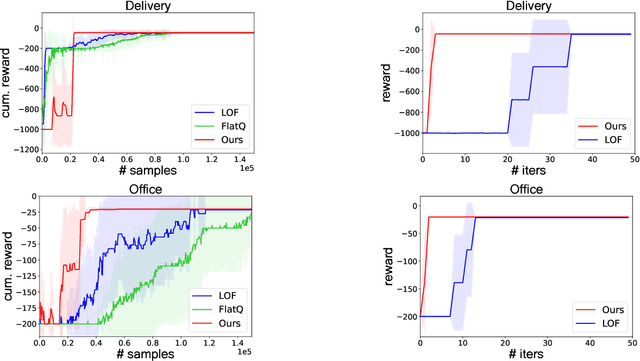
We introduce a novel approach to hierarchical reinforcement learning for Linearly-solvable Markov Decision Processes (LMDPs) in the infinite-horizon average-reward setting. Unlike previous work, our approach allows learning low-level and high-level tasks simultaneously, without imposing limiting restrictions on the low-level tasks. Our method relies on partitions of the state space that create smaller subtasks that are easier to solve, and the equivalence between such partitions to learn more efficiently. We then exploit the compositionality of low-level tasks to exactly represent the value function of the high-level task. Experiments show that our approach can outperform flat average-reward reinforcement learning by one or several orders of magnitude.
Combined Task and Motion Planning Via Sketch Decompositions
Mar 24, 2024



The challenge in combined task and motion planning (TAMP) is the effective integration of a search over a combinatorial space, usually carried out by a task planner, and a search over a continuous configuration space, carried out by a motion planner. Using motion planners for testing the feasibility of task plans and filling out the details is not effective because it makes the geometrical constraints play a passive role. This work introduces a new interleaved approach for integrating the two dimensions of TAMP that makes use of sketches, a recent simple but powerful language for expressing the decomposition of problems into subproblems. A sketch has width 1 if it decomposes the problem into subproblems that can be solved greedily in linear time. In the paper, a general sketch is introduced for several classes of TAMP problems which has width 1 under suitable assumptions. While sketch decompositions have been developed for classical planning, they offer two important benefits in the context of TAMP. First, when a task plan is found to be unfeasible due to the geometric constraints, the combinatorial search resumes in a specific sub-problem. Second, the sampling of object configurations is not done once, globally, at the start of the search, but locally, at the start of each subproblem. Optimizations of this basic setting are also considered and experimental results over existing and new pick-and-place benchmarks are reported.
Planning with a Learned Policy Basis to Optimally Solve Complex Tasks
Mar 22, 2024
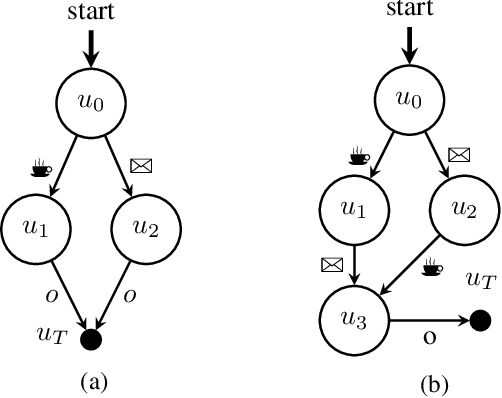
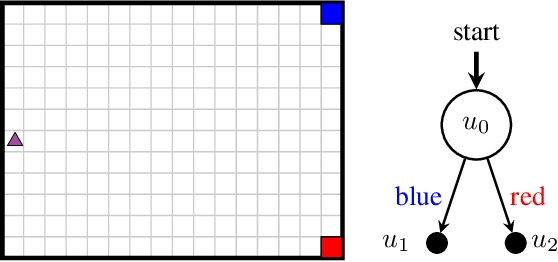
Conventional reinforcement learning (RL) methods can successfully solve a wide range of sequential decision problems. However, learning policies that can generalize predictably across multiple tasks in a setting with non-Markovian reward specifications is a challenging problem. We propose to use successor features to learn a policy basis so that each (sub)policy in it solves a well-defined subproblem. In a task described by a finite state automaton (FSA) that involves the same set of subproblems, the combination of these (sub)policies can then be used to generate an optimal solution without additional learning. In contrast to other methods that combine (sub)policies via planning, our method asymptotically attains global optimality, even in stochastic environments.
Improving Subgraph-GNNs via Edge-Level Ego-Network Encodings
Dec 10, 2023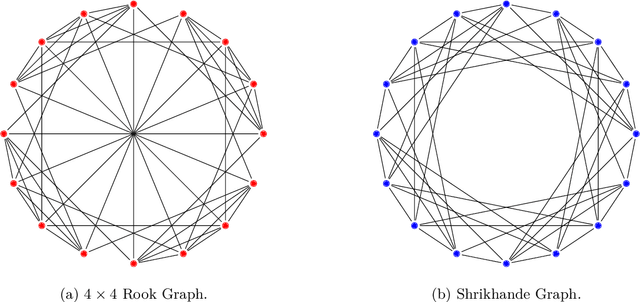
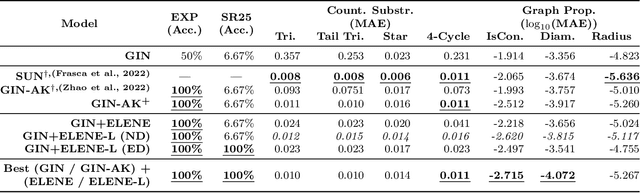
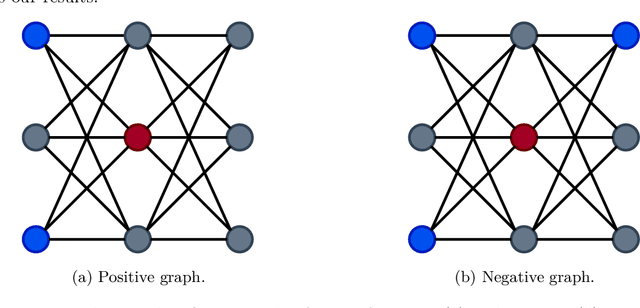
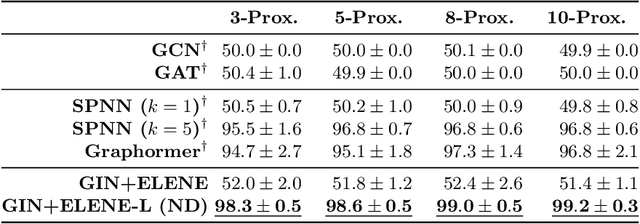
We present a novel edge-level ego-network encoding for learning on graphs that can boost Message Passing Graph Neural Networks (MP-GNNs) by providing additional node and edge features or extending message-passing formats. The proposed encoding is sufficient to distinguish Strongly Regular Graphs, a family of challenging 3-WL equivalent graphs. We show theoretically that such encoding is more expressive than node-based sub-graph MP-GNNs. In an empirical evaluation on four benchmarks with 10 graph datasets, our results match or improve previous baselines on expressivity, graph classification, graph regression, and proximity tasks -- while reducing memory usage by 18.1x in certain real-world settings.
Beyond 1-WL with Local Ego-Network Encodings
Dec 07, 2022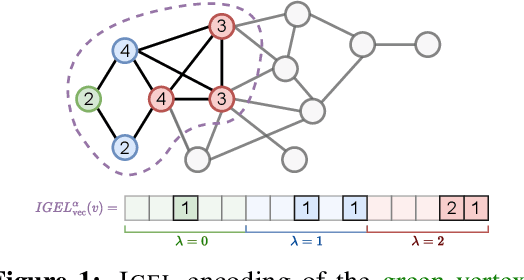
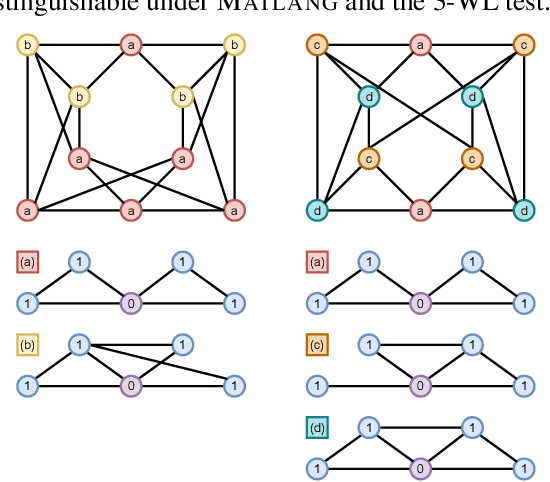
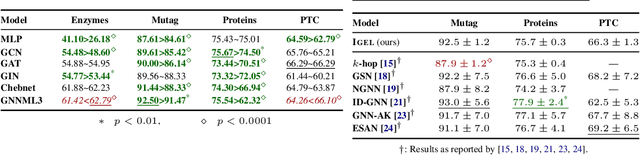
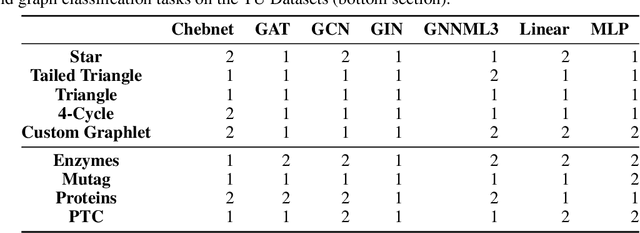
Identifying similar network structures is key to capture graph isomorphisms and learn representations that exploit structural information encoded in graph data. This work shows that ego-networks can produce a structural encoding scheme for arbitrary graphs with greater expressivity than the Weisfeiler-Lehman (1-WL) test. We introduce IGEL, a preprocessing step to produce features that augment node representations by encoding ego-networks into sparse vectors that enrich Message Passing (MP) Graph Neural Networks (GNNs) beyond 1-WL expressivity. We describe formally the relation between IGEL and 1-WL, and characterize its expressive power and limitations. Experiments show that IGEL matches the empirical expressivity of state-of-the-art methods on isomorphism detection while improving performance on seven GNN architectures.
Uncovering the Limits of Text-based Emotion Detection
Sep 04, 2021
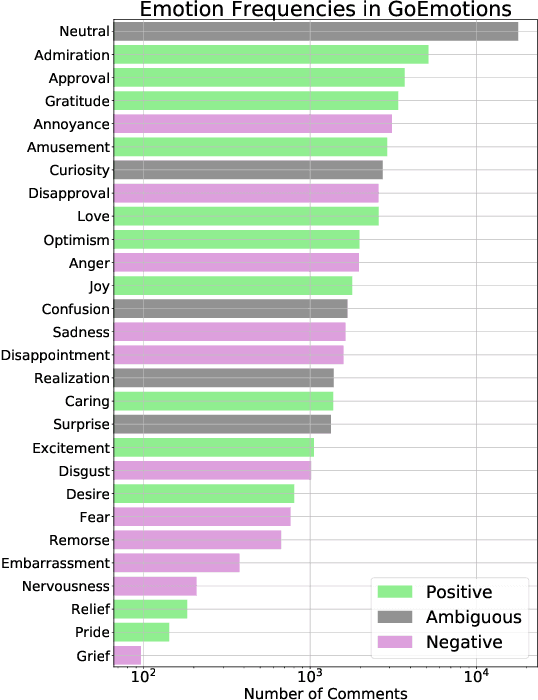
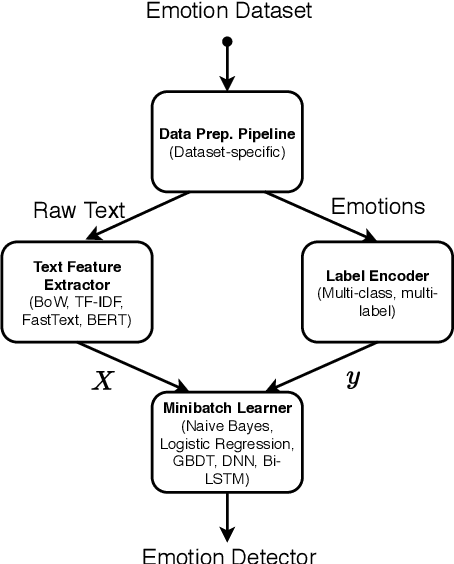
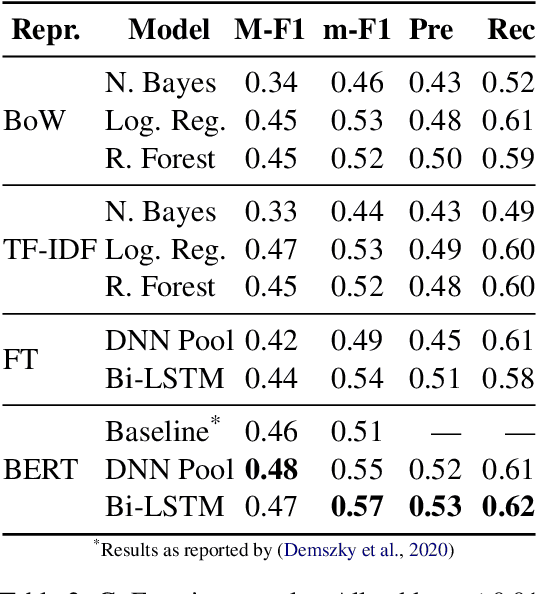
Identifying emotions from text is crucial for a variety of real world tasks. We consider the two largest now-available corpora for emotion classification: GoEmotions, with 58k messages labelled by readers, and Vent, with 33M writer-labelled messages. We design a benchmark and evaluate several feature spaces and learning algorithms, including two simple yet novel models on top of BERT that outperform previous strong baselines on GoEmotions. Through an experiment with human participants, we also analyze the differences between how writers express emotions and how readers perceive them. Our results suggest that emotions expressed by writers are harder to identify than emotions that readers perceive. We share a public web interface for researchers to explore our models.
Globally Optimal Hierarchical Reinforcement Learning for Linearly-Solvable Markov Decision Processes
Jun 29, 2021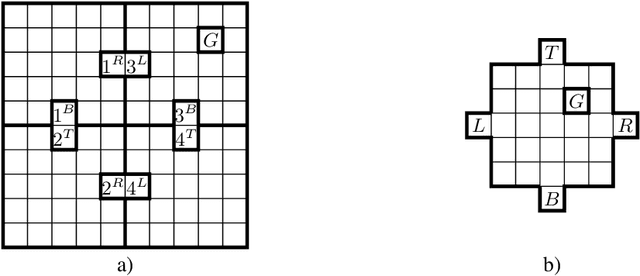
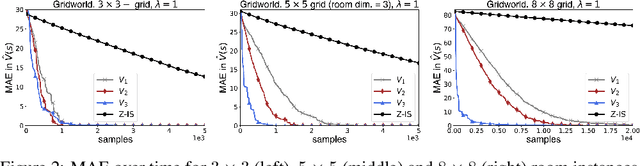
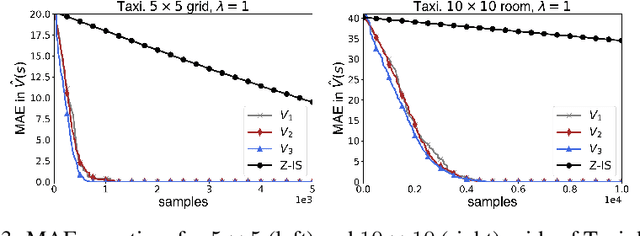
In this work we present a novel approach to hierarchical reinforcement learning for linearly-solvable Markov decision processes. Our approach assumes that the state space is partitioned, and the subtasks consist in moving between the partitions. We represent value functions on several levels of abstraction, and use the compositionality of subtasks to estimate the optimal values of the states in each partition. The policy is implicitly defined on these optimal value estimates, rather than being decomposed among the subtasks. As a consequence, our approach can learn the globally optimal policy, and does not suffer from the non-stationarity of high-level decisions. If several partitions have equivalent dynamics, the subtasks of those partitions can be shared. If the set of boundary states is smaller than the entire state space, our approach can have significantly smaller sample complexity than that of a flat learner, and we validate this empirically in several experiments.
Hierarchical Width-Based Planning and Learning
Jan 15, 2021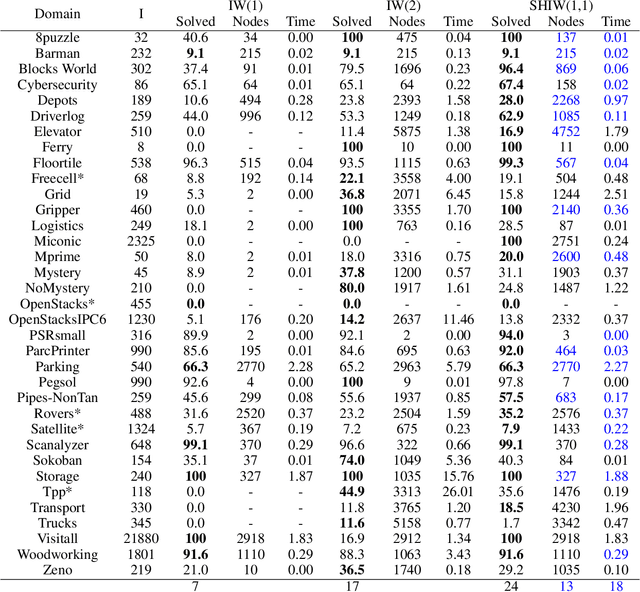
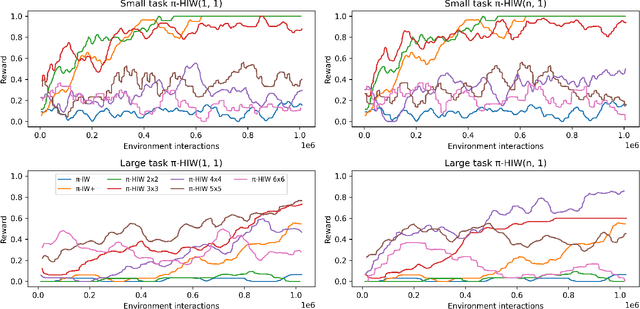
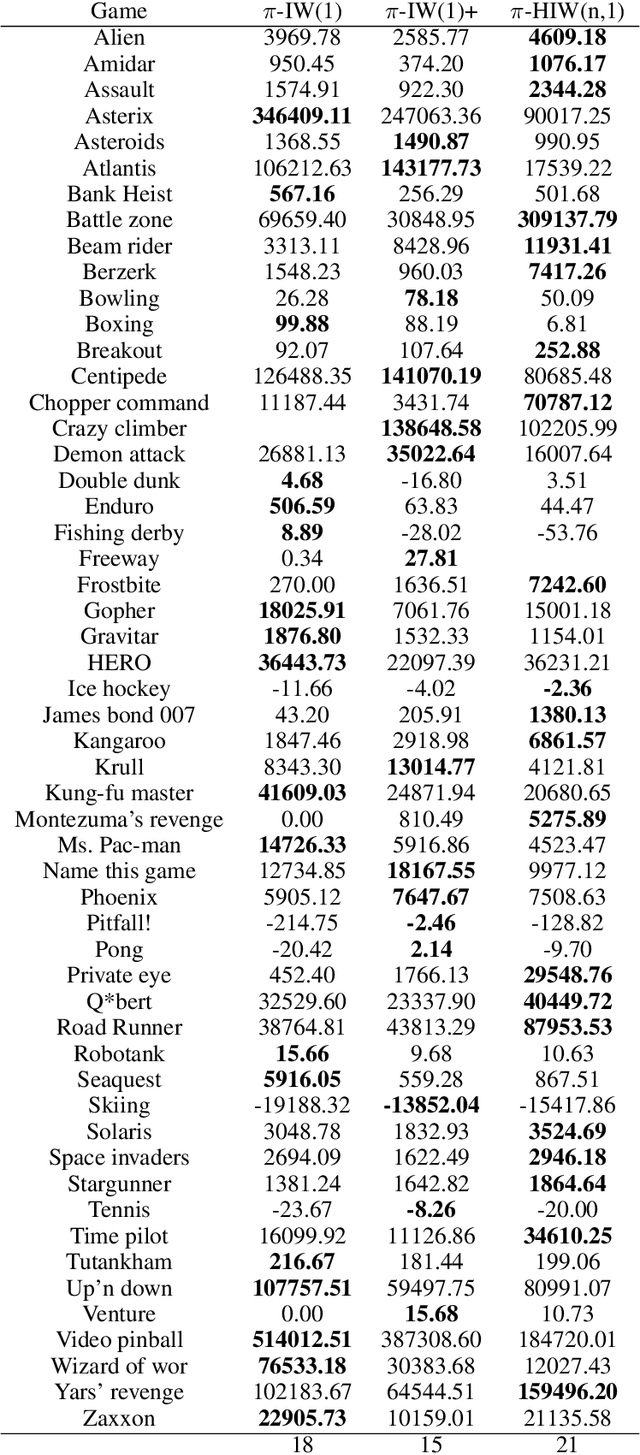
Width-based search methods have demonstrated state-of-the-art performance in a wide range of testbeds, from classical planning problems to image-based simulators such as Atari games. These methods scale independently of the size of the state-space, but exponentially in the problem width. In practice, running the algorithm with a width larger than 1 is computationally intractable, prohibiting IW from solving higher width problems. In this paper, we present a hierarchical algorithm that plans at two levels of abstraction. A high-level planner uses abstract features that are incrementally discovered from low-level pruning decisions. We illustrate this algorithm in classical planning PDDL domains as well as in pixel-based simulator domains. In classical planning, we show how IW(1) at two levels of abstraction can solve problems of width 2. For pixel-based domains, we show how in combination with a learned policy and a learned value function, the proposed hierarchical IW can outperform current flat IW-based planners in Atari games with sparse rewards.
Inductive Graph Embeddings through Locality Encodings
Sep 26, 2020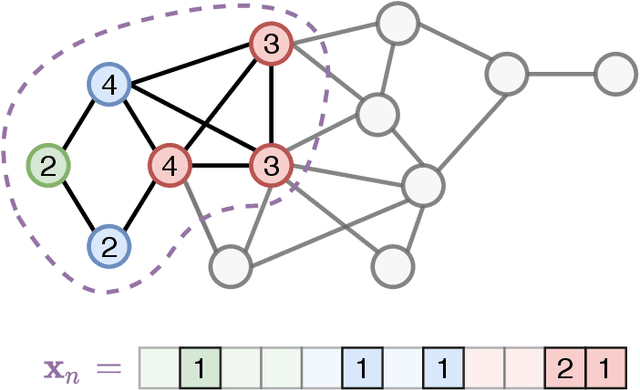



Learning embeddings from large-scale networks is an open challenge. Despite the overwhelming number of existing methods, is is unclear how to exploit network structure in a way that generalizes easily to unseen nodes, edges or graphs. In this work, we look at the problem of finding inductive network embeddings in large networks without domain-dependent node/edge attributes. We propose to use a set of basic predefined local encodings as the basis of a learning algorithm. In particular, we consider the degree frequencies at different distances from a node, which can be computed efficiently for relatively short distances and a large number of nodes. Interestingly, the resulting embeddings generalize well across unseen or distant regions in the network, both in unsupervised settings, when combined with language model learning, as well as in supervised tasks, when used as additional features in a neural network. Despite its simplicity, this method achieves state-of-the-art performance in tasks such as role detection, link prediction and node classification, and represents an inductive network embedding method directly applicable to large unattributed networks.
Adaptive Smoothing Path Integral Control
May 13, 2020
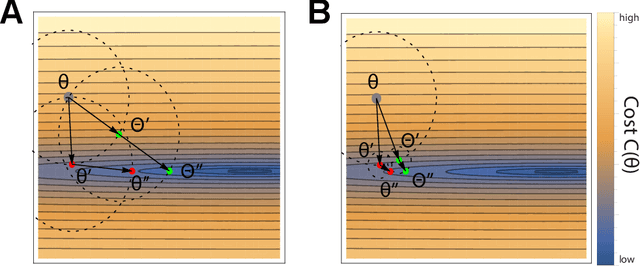
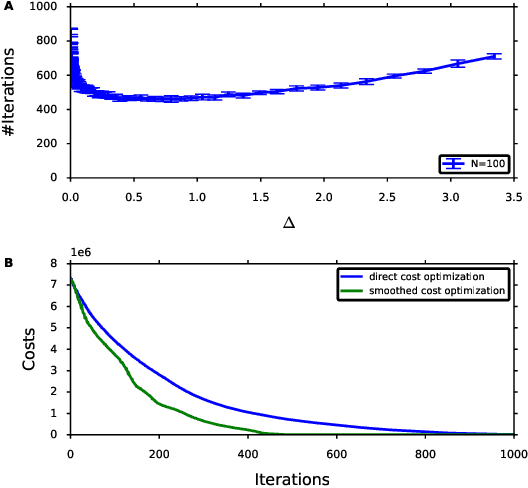
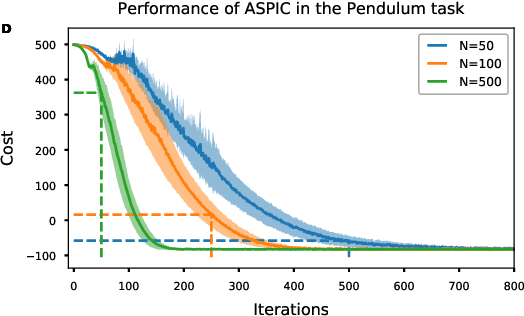
In Path Integral control problems a representation of an optimally controlled dynamical system can be formally computed and serve as a guidepost to learn a parametrized policy. The Path Integral Cross-Entropy (PICE) method tries to exploit this, but is hampered by poor sample efficiency. We propose a model-free algorithm called ASPIC (Adaptive Smoothing of Path Integral Control) that applies an inf-convolution to the cost function to speedup convergence of policy optimization. We identify PICE as the infinite smoothing limit of such technique and show that the sample efficiency problems that PICE suffers disappear for finite levels of smoothing. For zero smoothing this method becomes a greedy optimization of the cost, which is the standard approach in current reinforcement learning. We show analytically and empirically that intermediate levels of smoothing are optimal, which renders the new method superior to both PICE and direct cost-optimization.