 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Average-Reward Linearly-solvable Markov Decision Processes
Paper and Code
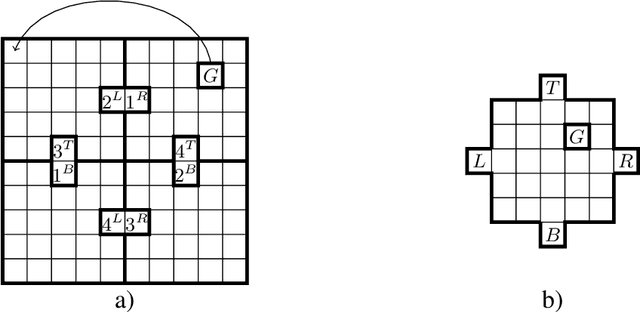
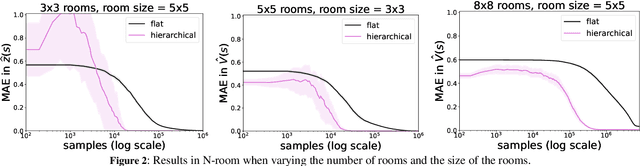
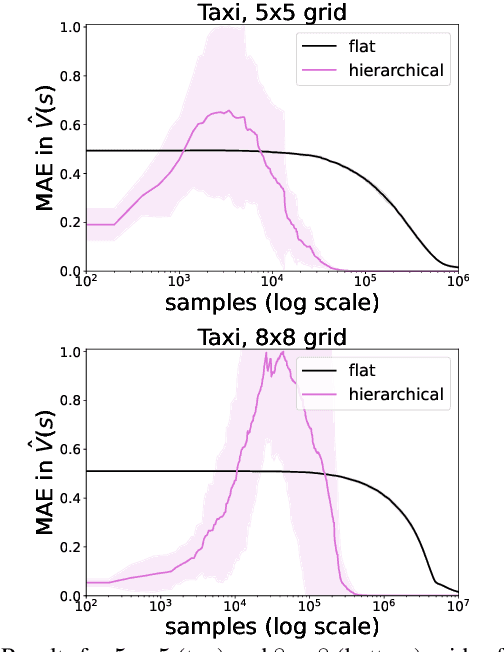
We introduce a novel approach to hierarchical reinforcement learning for Linearly-solvable Markov Decision Processes (LMDPs) in the infinite-horizon average-reward setting. Unlike previous work, our approach allows learning low-level and high-level tasks simultaneously, without imposing limiting restrictions on the low-level tasks. Our method relies on partitions of the state space that create smaller subtasks that are easier to solve, and the equivalence between such partitions to learn more efficiently. We then exploit the compositionality of low-level tasks to exactly represent the value function of the high-level task. Experiments show that our approach can outperform flat average-reward reinforcement learning by one or several orders of magnitude.