 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanning with a Learned Policy Basis to Optimally Solve Complex Tasks
Paper and Code
Mar 22, 2024
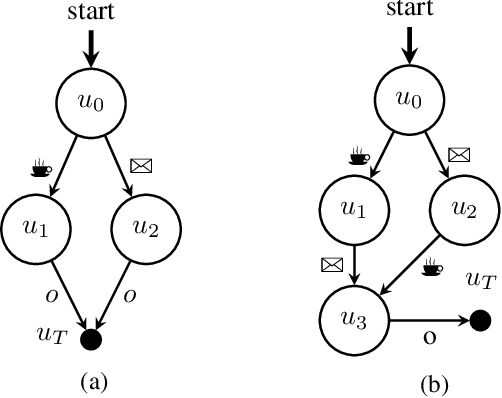
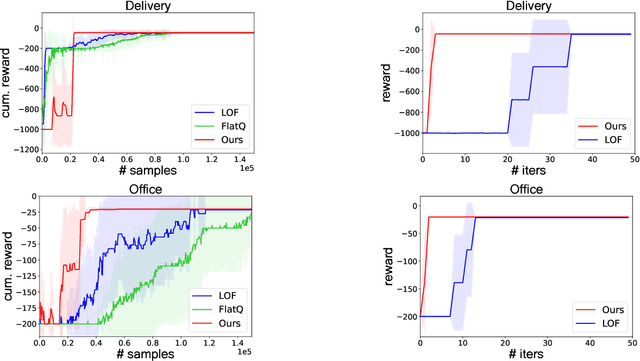
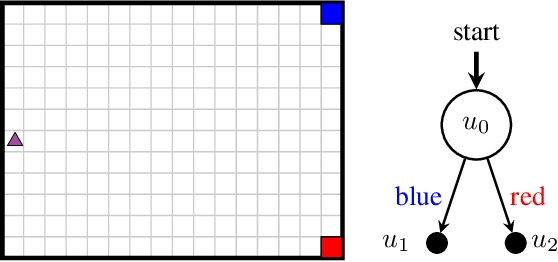
Conventional reinforcement learning (RL) methods can successfully solve a wide range of sequential decision problems. However, learning policies that can generalize predictably across multiple tasks in a setting with non-Markovian reward specifications is a challenging problem. We propose to use successor features to learn a policy basis so that each (sub)policy in it solves a well-defined subproblem. In a task described by a finite state automaton (FSA) that involves the same set of subproblems, the combination of these (sub)policies can then be used to generate an optimal solution without additional learning. In contrast to other methods that combine (sub)policies via planning, our method asymptotically attains global optimality, even in stochastic environments.