 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Universal Policies Universal
Feb 20, 2025


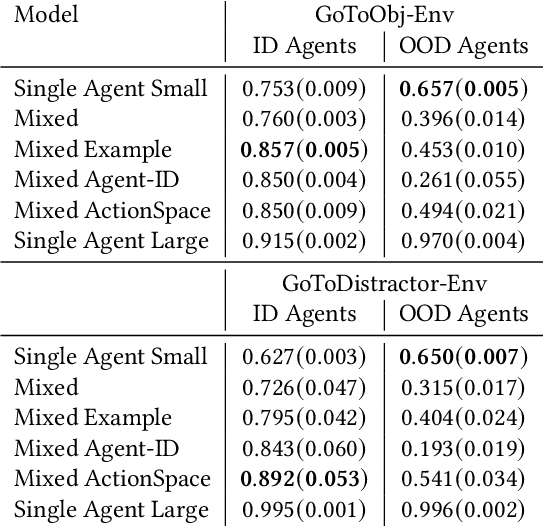
The development of a generalist agent capable of solving a wide range of sequential decision-making tasks remains a significant challenge. We address this problem in a cross-agent setup where agents share the same observation space but differ in their action spaces. Our approach builds on the universal policy framework, which decouples policy learning into two stages: a diffusion-based planner that generates observation sequences and an inverse dynamics model that assigns actions to these plans. We propose a method for training the planner on a joint dataset composed of trajectories from all agents. This method offers the benefit of positive transfer by pooling data from different agents, while the primary challenge lies in adapting shared plans to each agent's unique constraints. We evaluate our approach on the BabyAI environment, covering tasks of varying complexity, and demonstrate positive transfer across agents. Additionally, we examine the planner's generalisation ability to unseen agents and compare our method to traditional imitation learning approaches. By training on a pooled dataset from multiple agents, our universal policy achieves an improvement of up to $42.20\%$ in task completion accuracy compared to a policy trained on a dataset from a single agent.
Planning with a Learned Policy Basis to Optimally Solve Complex Tasks
Mar 22, 2024
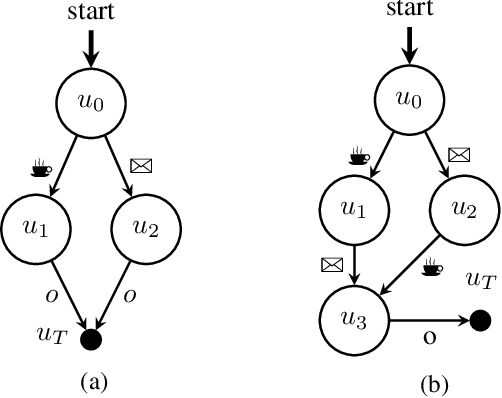
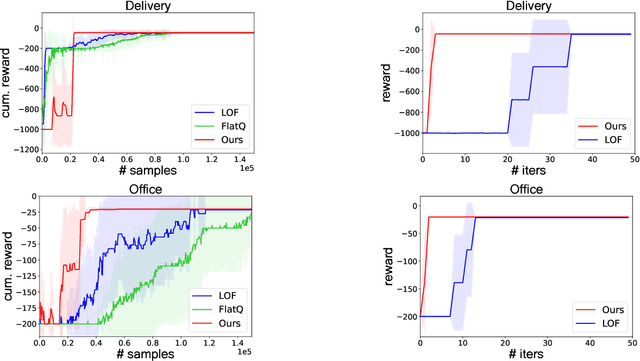
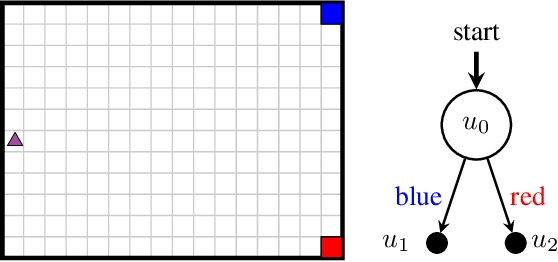
Conventional reinforcement learning (RL) methods can successfully solve a wide range of sequential decision problems. However, learning policies that can generalize predictably across multiple tasks in a setting with non-Markovian reward specifications is a challenging problem. We propose to use successor features to learn a policy basis so that each (sub)policy in it solves a well-defined subproblem. In a task described by a finite state automaton (FSA) that involves the same set of subproblems, the combination of these (sub)policies can then be used to generate an optimal solution without additional learning. In contrast to other methods that combine (sub)policies via planning, our method asymptotically attains global optimality, even in stochastic environments.
Reusable Options through Gradient-based Meta Learning
Dec 22, 2022
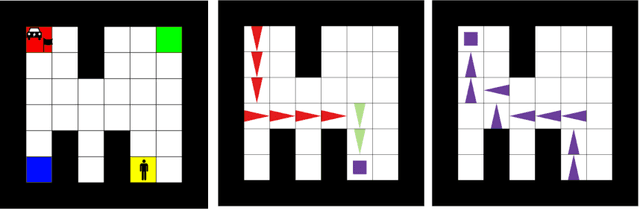
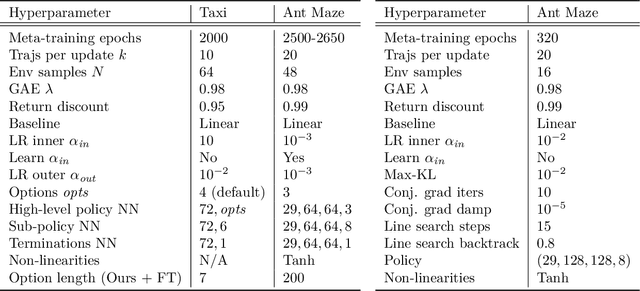
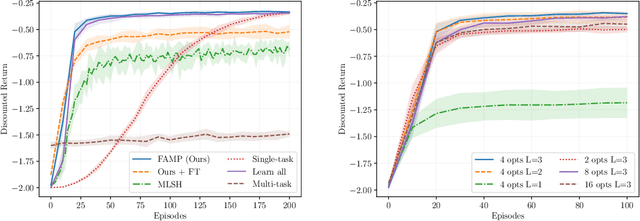
Hierarchical methods in reinforcement learning have the potential to reduce the amount of decisions that the agent needs to perform when learning new tasks. However, finding a reusable useful temporal abstractions that facilitate fast learning remains a challenging problem. Recently, several deep learning approaches were proposed to learn such temporal abstractions in the form of options in an end-to-end manner. In this work, we point out several shortcomings of these methods and discuss their potential negative consequences. Subsequently, we formulate the desiderata for reusable options and use these to frame the problem of learning options as a gradient-based meta-learning problem. This allows us to formulate an objective that explicitly incentivizes options which allow a higher-level decision maker to adjust in few steps to different tasks. Experimentally, we show that our method is able to learn transferable components which accelerate learning and performs better than existing prior methods developed for this setting. Additionally, we perform ablations to quantify the impact of using gradient-based meta-learning as well as other proposed changes.