 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Universal Policies Universal
Feb 20, 2025


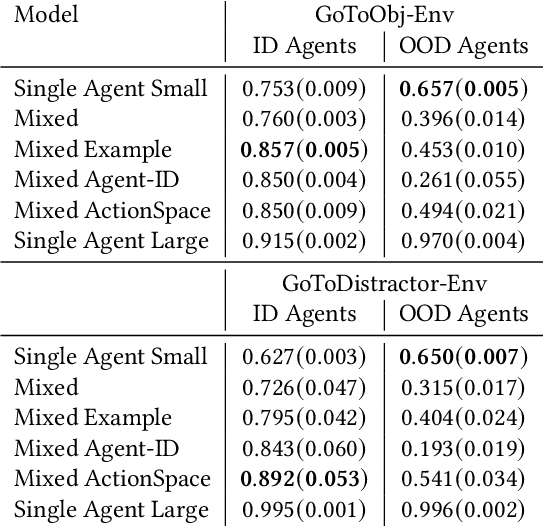
The development of a generalist agent capable of solving a wide range of sequential decision-making tasks remains a significant challenge. We address this problem in a cross-agent setup where agents share the same observation space but differ in their action spaces. Our approach builds on the universal policy framework, which decouples policy learning into two stages: a diffusion-based planner that generates observation sequences and an inverse dynamics model that assigns actions to these plans. We propose a method for training the planner on a joint dataset composed of trajectories from all agents. This method offers the benefit of positive transfer by pooling data from different agents, while the primary challenge lies in adapting shared plans to each agent's unique constraints. We evaluate our approach on the BabyAI environment, covering tasks of varying complexity, and demonstrate positive transfer across agents. Additionally, we examine the planner's generalisation ability to unseen agents and compare our method to traditional imitation learning approaches. By training on a pooled dataset from multiple agents, our universal policy achieves an improvement of up to $42.20\%$ in task completion accuracy compared to a policy trained on a dataset from a single agent.
A General Learning Framework for Open Ad Hoc Teamwork Using Graph-based Policy Learning
Oct 11, 2022



Open ad hoc teamwork is the problem of training a single agent to efficiently collaborate with an unknown group of teammates whose composition may change over time. A variable team composition creates challenges for the agent, such as the requirement to adapt to new team dynamics and dealing with changing state vector sizes. These challenges are aggravated in real-world applications where the controlled agent has no access to the full state of the environment. In this work, we develop a class of solutions for open ad hoc teamwork under full and partial observability. We start by developing a solution for the fully observable case that leverages graph neural network architectures to obtain an optimal policy based on reinforcement learning. We then extend this solution to partially observable scenarios by proposing different methodologies that maintain belief estimates over the latent environment states and team composition. These belief estimates are combined with our solution for the fully observable case to compute an agent's optimal policy under partial observability in open ad hoc teamwork. Empirical results demonstrate that our approach can learn efficient policies in open ad hoc teamwork in full and partially observable cases. Further analysis demonstrates that our methods' success is a result of effectively learning the effects of teammates' actions while also inferring the inherent state of the environment under partial observability
Leveraging class abstraction for commonsense reinforcement learning via residual policy gradient methods
Jan 28, 2022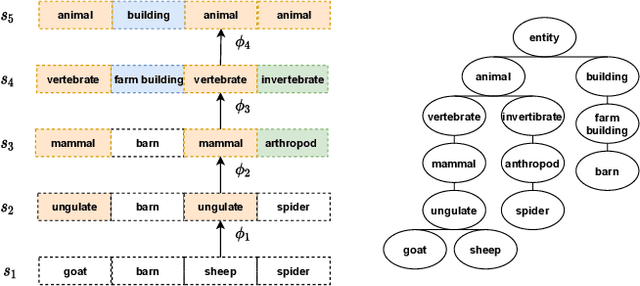
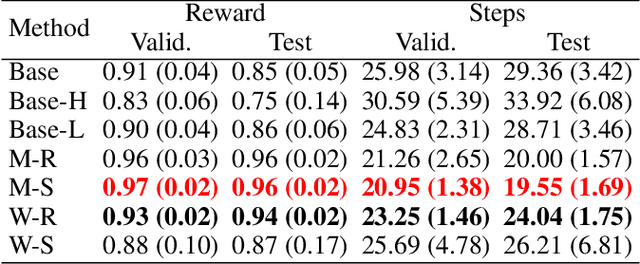
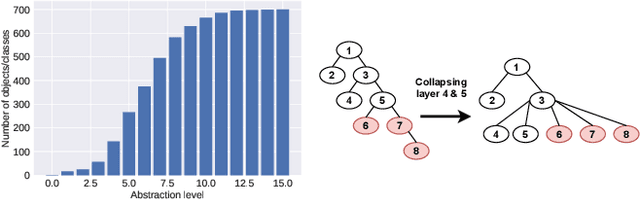

Enabling reinforcement learning (RL) agents to leverage a knowledge base while learning from experience promises to advance RL in knowledge intensive domains. However, it has proven difficult to leverage knowledge that is not manually tailored to the environment. We propose to use the subclass relationships present in open-source knowledge graphs to abstract away from specific objects. We develop a residual policy gradient method that is able to integrate knowledge across different abstraction levels in the class hierarchy. Our method results in improved sample efficiency and generalisation to unseen objects in commonsense games, but we also investigate failure modes, such as excessive noise in the extracted class knowledge or environments with little class structure.