 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-Agnostic Modeling of Source Reliability on Wikipedia
Oct 24, 2024
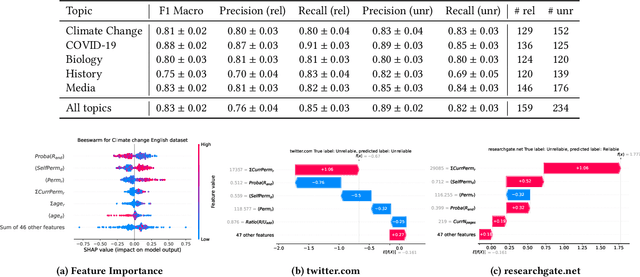
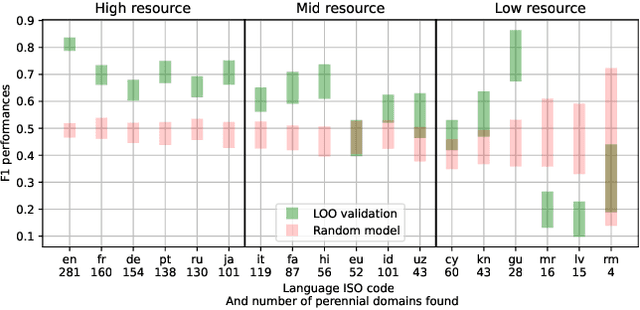
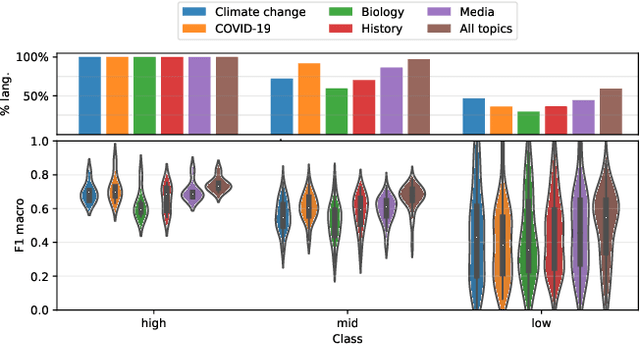
Over the last few years, content verification through reliable sources has become a fundamental need to combat disinformation. Here, we present a language-agnostic model designed to assess the reliability of sources across multiple language editions of Wikipedia. Utilizing editorial activity data, the model evaluates source reliability within different articles of varying controversiality such as Climate Change, COVID-19, History, Media, and Biology topics. Crafting features that express domain usage across articles, the model effectively predicts source reliability, achieving an F1 Macro score of approximately 0.80 for English and other high-resource languages. For mid-resource languages, we achieve 0.65 while the performance of low-resource languages varies; in all cases, the time the domain remains present in the articles (which we dub as permanence) is one of the most predictive features. We highlight the challenge of maintaining consistent model performance across languages of varying resource levels and demonstrate that adapting models from higher-resource languages can improve performance. This work contributes not only to Wikipedia's efforts in ensuring content verifiability but in ensuring reliability across diverse user-generated content in various language communities.
Improving Subgraph-GNNs via Edge-Level Ego-Network Encodings
Dec 10, 2023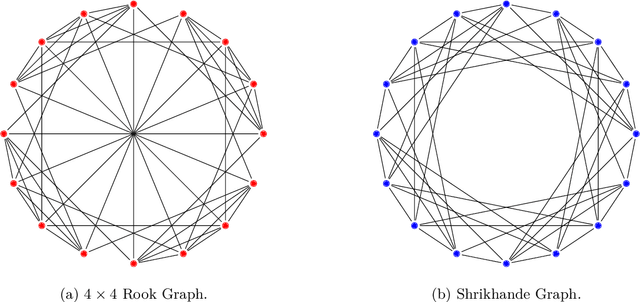
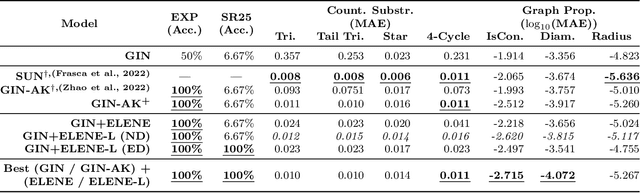
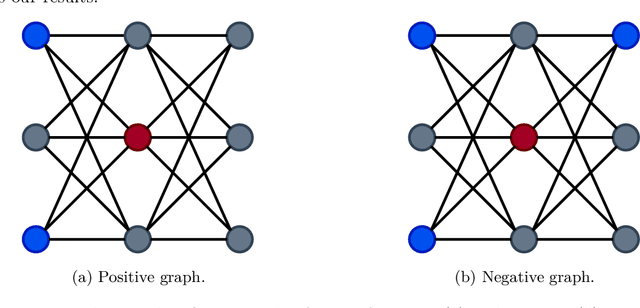
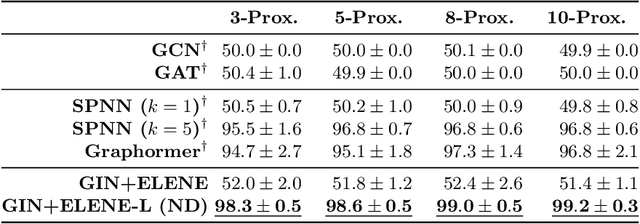
We present a novel edge-level ego-network encoding for learning on graphs that can boost Message Passing Graph Neural Networks (MP-GNNs) by providing additional node and edge features or extending message-passing formats. The proposed encoding is sufficient to distinguish Strongly Regular Graphs, a family of challenging 3-WL equivalent graphs. We show theoretically that such encoding is more expressive than node-based sub-graph MP-GNNs. In an empirical evaluation on four benchmarks with 10 graph datasets, our results match or improve previous baselines on expressivity, graph classification, graph regression, and proximity tasks -- while reducing memory usage by 18.1x in certain real-world settings.
Beyond 1-WL with Local Ego-Network Encodings
Dec 07, 2022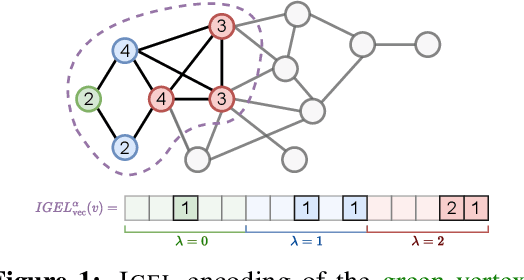
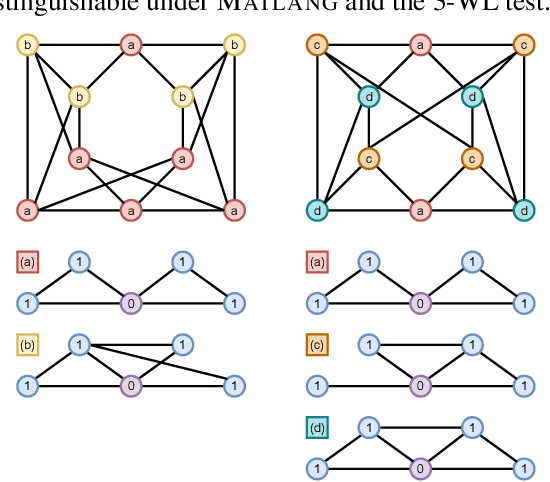
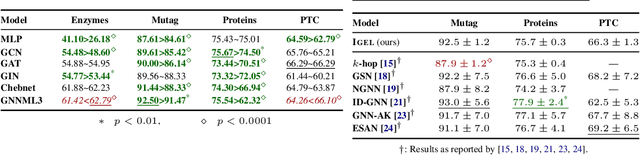
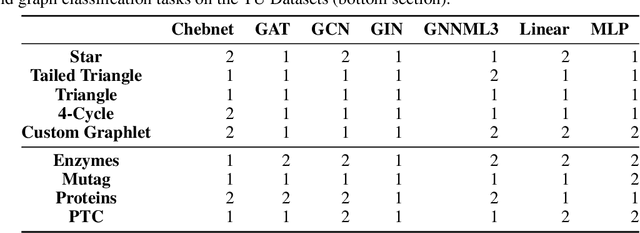
Identifying similar network structures is key to capture graph isomorphisms and learn representations that exploit structural information encoded in graph data. This work shows that ego-networks can produce a structural encoding scheme for arbitrary graphs with greater expressivity than the Weisfeiler-Lehman (1-WL) test. We introduce IGEL, a preprocessing step to produce features that augment node representations by encoding ego-networks into sparse vectors that enrich Message Passing (MP) Graph Neural Networks (GNNs) beyond 1-WL expressivity. We describe formally the relation between IGEL and 1-WL, and characterize its expressive power and limitations. Experiments show that IGEL matches the empirical expressivity of state-of-the-art methods on isomorphism detection while improving performance on seven GNN architectures.
Large scale analysis of gender bias and sexism in song lyrics
Aug 03, 2022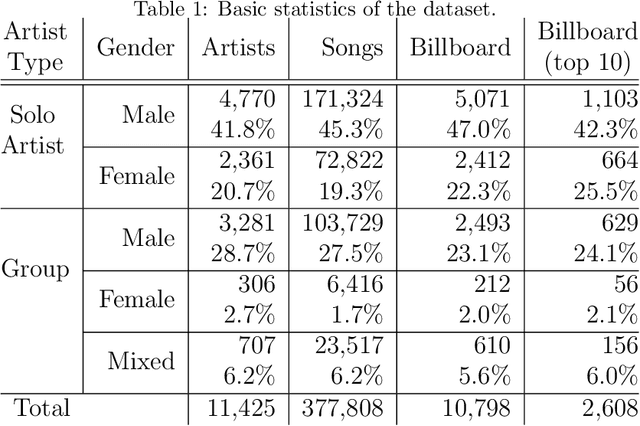
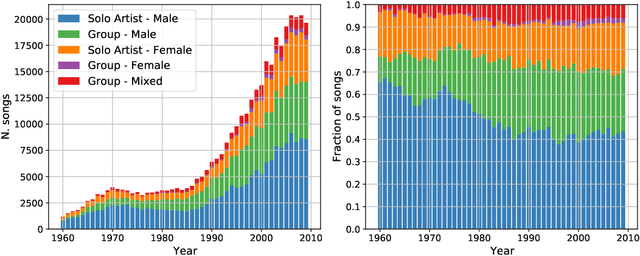
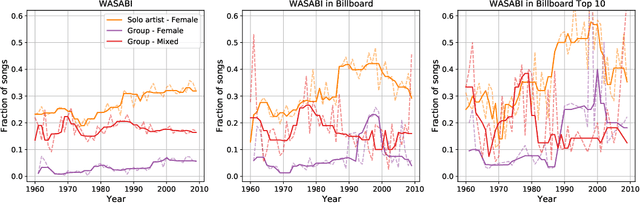
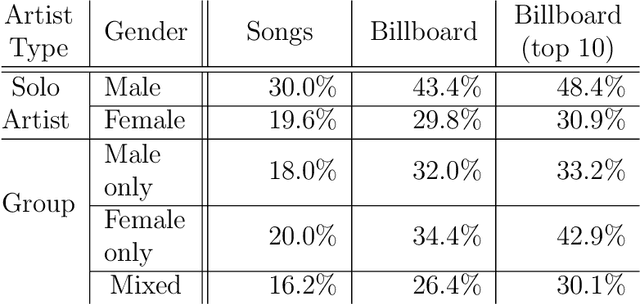
We employ Natural Language Processing techniques to analyse 377808 English song lyrics from the "Two Million Song Database" corpus, focusing on the expression of sexism across five decades (1960-2010) and the measurement of gender biases. Using a sexism classifier, we identify sexist lyrics at a larger scale than previous studies using small samples of manually annotated popular songs. Furthermore, we reveal gender biases by measuring associations in word embeddings learned on song lyrics. We find sexist content to increase across time, especially from male artists and for popular songs appearing in Billboard charts. Songs are also shown to contain different language biases depending on the gender of the performer, with male solo artist songs containing more and stronger biases. This is the first large scale analysis of this type, giving insights into language usage in such an influential part of popular culture.
Uncovering the Limits of Text-based Emotion Detection
Sep 04, 2021
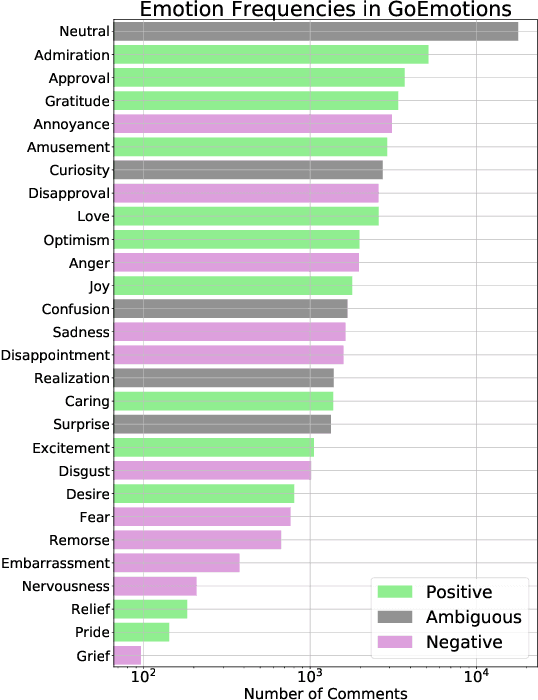
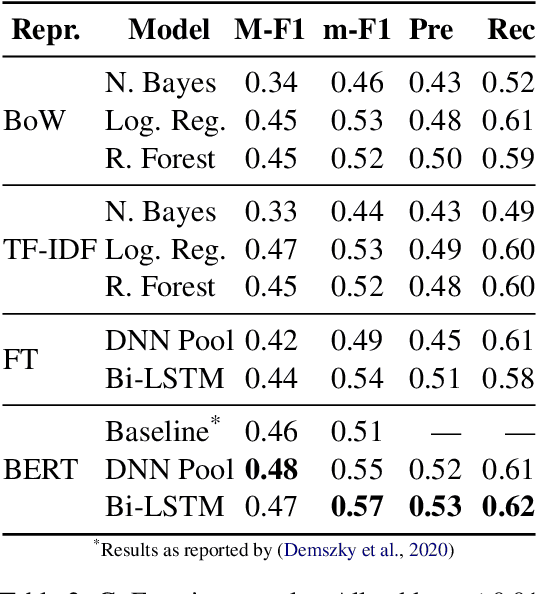
Identifying emotions from text is crucial for a variety of real world tasks. We consider the two largest now-available corpora for emotion classification: GoEmotions, with 58k messages labelled by readers, and Vent, with 33M writer-labelled messages. We design a benchmark and evaluate several feature spaces and learning algorithms, including two simple yet novel models on top of BERT that outperform previous strong baselines on GoEmotions. Through an experiment with human participants, we also analyze the differences between how writers express emotions and how readers perceive them. Our results suggest that emotions expressed by writers are harder to identify than emotions that readers perceive. We share a public web interface for researchers to explore our models.
Inductive Graph Embeddings through Locality Encodings
Sep 26, 2020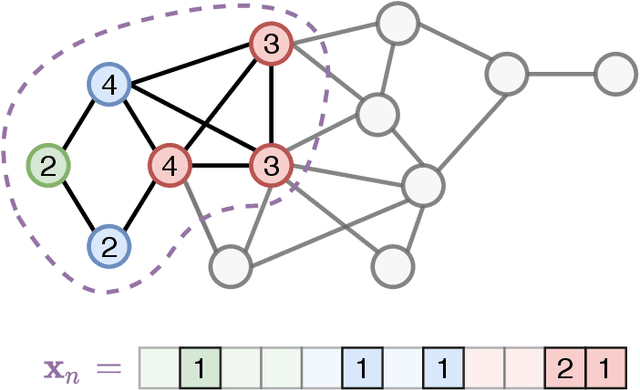



Learning embeddings from large-scale networks is an open challenge. Despite the overwhelming number of existing methods, is is unclear how to exploit network structure in a way that generalizes easily to unseen nodes, edges or graphs. In this work, we look at the problem of finding inductive network embeddings in large networks without domain-dependent node/edge attributes. We propose to use a set of basic predefined local encodings as the basis of a learning algorithm. In particular, we consider the degree frequencies at different distances from a node, which can be computed efficiently for relatively short distances and a large number of nodes. Interestingly, the resulting embeddings generalize well across unseen or distant regions in the network, both in unsupervised settings, when combined with language model learning, as well as in supervised tasks, when used as additional features in a neural network. Despite its simplicity, this method achieves state-of-the-art performance in tasks such as role detection, link prediction and node classification, and represents an inductive network embedding method directly applicable to large unattributed networks.
Societal Controversies in Wikipedia Articles
Apr 18, 2019
Collaborative content creation inevitably reaches situations where different points of view lead to conflict. We focus on Wikipedia, the free encyclopedia anyone may edit, where disputes about content in controversial articles often reflect larger societal debates. While Wikipedia has a public edit history and discussion section for every article, the substance of these sections is difficult to phantom for Wikipedia users interested in the development of an article and in locating which topics were most controversial. In this paper we present Contropedia, a tool that augments Wikipedia articles and gives insight into the development of controversial topics. Contropedia uses an efficient language agnostic measure based on the edit history that focuses on wiki links to easily identify which topics within a Wikipedia article have been most controversial and when.