 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-Agnostic Modeling of Source Reliability on Wikipedia
Paper and Code
Oct 24, 2024
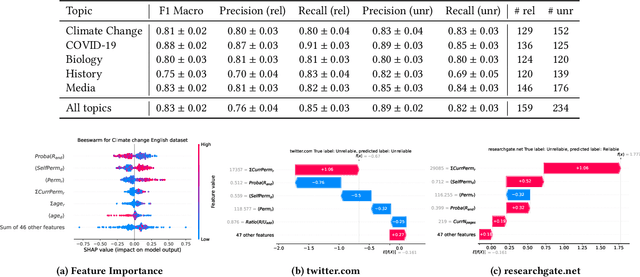
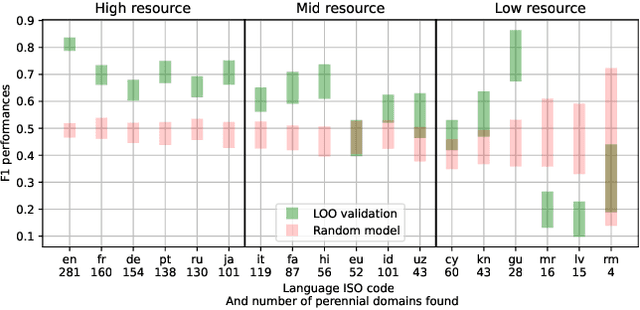
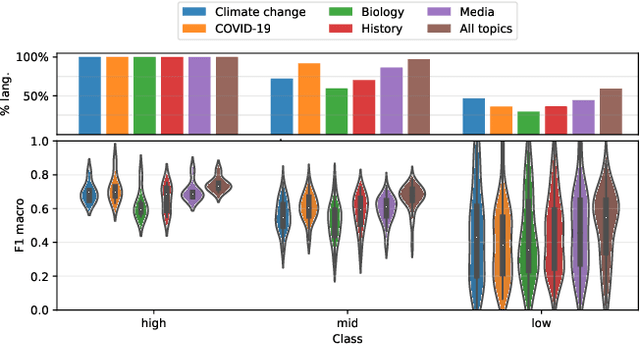
Over the last few years, content verification through reliable sources has become a fundamental need to combat disinformation. Here, we present a language-agnostic model designed to assess the reliability of sources across multiple language editions of Wikipedia. Utilizing editorial activity data, the model evaluates source reliability within different articles of varying controversiality such as Climate Change, COVID-19, History, Media, and Biology topics. Crafting features that express domain usage across articles, the model effectively predicts source reliability, achieving an F1 Macro score of approximately 0.80 for English and other high-resource languages. For mid-resource languages, we achieve 0.65 while the performance of low-resource languages varies; in all cases, the time the domain remains present in the articles (which we dub as permanence) is one of the most predictive features. We highlight the challenge of maintaining consistent model performance across languages of varying resource levels and demonstrate that adapting models from higher-resource languages can improve performance. This work contributes not only to Wikipedia's efforts in ensuring content verifiability but in ensuring reliability across diverse user-generated content in various language communities.