 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairness in Algorithmic Recourse Through the Lens of Substantive Equality of Opportunity
Jan 29, 2024
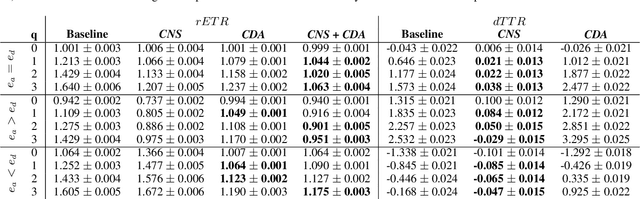
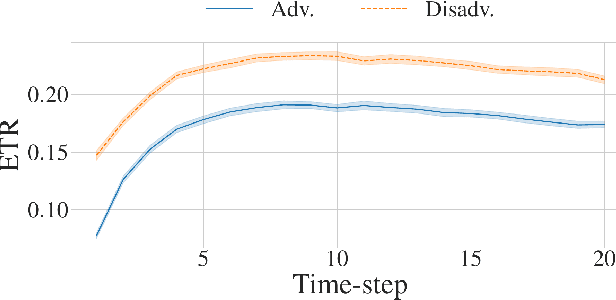
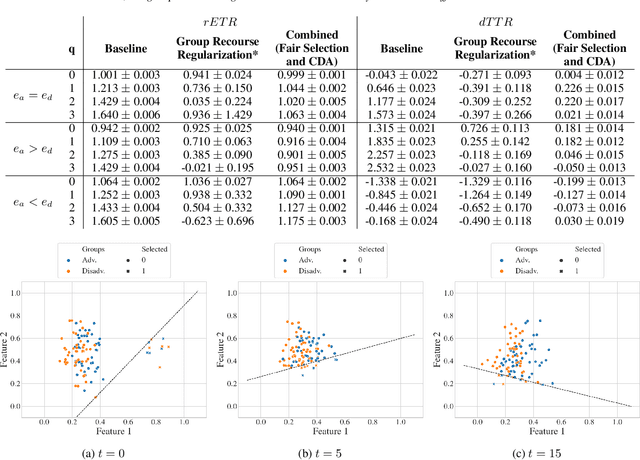
Algorithmic recourse -- providing recommendations to those affected negatively by the outcome of an algorithmic system on how they can take action and change that outcome -- has gained attention as a means of giving persons agency in their interactions with artificial intelligence (AI) systems. Recent work has shown that even if an AI decision-making classifier is ``fair'' (according to some reasonable criteria), recourse itself may be unfair due to differences in the initial circumstances of individuals, compounding disparities for marginalized populations and requiring them to exert more effort than others. There is a need to define more methods and metrics for evaluating fairness in recourse that span a range of normative views of the world, and specifically those that take into account time. Time is a critical element in recourse because the longer it takes an individual to act, the more the setting may change due to model or data drift. This paper seeks to close this research gap by proposing two notions of fairness in recourse that are in normative alignment with substantive equality of opportunity, and that consider time. The first considers the (often repeated) effort individuals exert per successful recourse event, and the second considers time per successful recourse event. Building upon an agent-based framework for simulating recourse, this paper demonstrates how much effort is needed to overcome disparities in initial circumstances. We then proposes an intervention to improve the fairness of recourse by rewarding effort, and compare it to existing strategies.
Setting the Right Expectations: Algorithmic Recourse Over Time
Sep 13, 2023


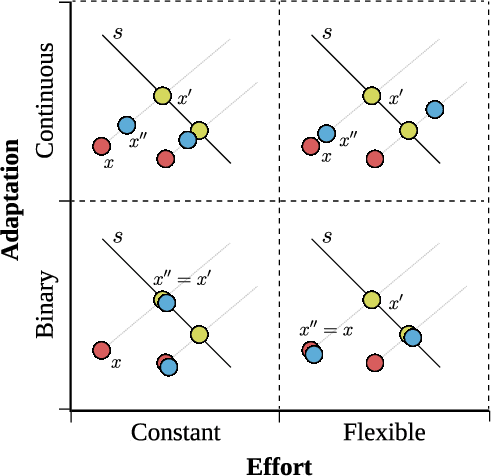
Algorithmic systems are often called upon to assist in high-stakes decision making. In light of this, algorithmic recourse, the principle wherein individuals should be able to take action against an undesirable outcome made by an algorithmic system, is receiving growing attention. The bulk of the literature on algorithmic recourse to-date focuses primarily on how to provide recourse to a single individual, overlooking a critical element: the effects of a continuously changing context. Disregarding these effects on recourse is a significant oversight, since, in almost all cases, recourse consists of an individual making a first, unfavorable attempt, and then being given an opportunity to make one or several attempts at a later date - when the context might have changed. This can create false expectations, as initial recourse recommendations may become less reliable over time due to model drift and competition for access to the favorable outcome between individuals. In this work we propose an agent-based simulation framework for studying the effects of a continuously changing environment on algorithmic recourse. In particular, we identify two main effects that can alter the reliability of recourse for individuals represented by the agents: (1) competition with other agents acting upon recourse, and (2) competition with new agents entering the environment. Our findings highlight that only a small set of specific parameterizations result in algorithmic recourse that is reliable for agents over time. Consequently, we argue that substantial additional work is needed to understand recourse reliability over time, and to develop recourse methods that reward agents' effort.
Counterfactual Explanations for Graph Classification Through the Lenses of Density
Jul 27, 2023



Counterfactual examples have emerged as an effective approach to produce simple and understandable post-hoc explanations. In the context of graph classification, previous work has focused on generating counterfactual explanations by manipulating the most elementary units of a graph, i.e., removing an existing edge, or adding a non-existing one. In this paper, we claim that such language of explanation might be too fine-grained, and turn our attention to some of the main characterizing features of real-world complex networks, such as the tendency to close triangles, the existence of recurring motifs, and the organization into dense modules. We thus define a general density-based counterfactual search framework to generate instance-level counterfactual explanations for graph classifiers, which can be instantiated with different notions of dense substructures. In particular, we show two specific instantiations of this general framework: a method that searches for counterfactual graphs by opening or closing triangles, and a method driven by maximal cliques. We also discuss how the general method can be instantiated to exploit any other notion of dense substructures, including, for instance, a given taxonomy of nodes. We evaluate the effectiveness of our approaches in 7 brain network datasets and compare the counterfactual statements generated according to several widely-used metrics. Results confirm that adopting a semantic-relevant unit of change like density is essential to define versatile and interpretable counterfactual explanation methods.
Large scale analysis of gender bias and sexism in song lyrics
Aug 03, 2022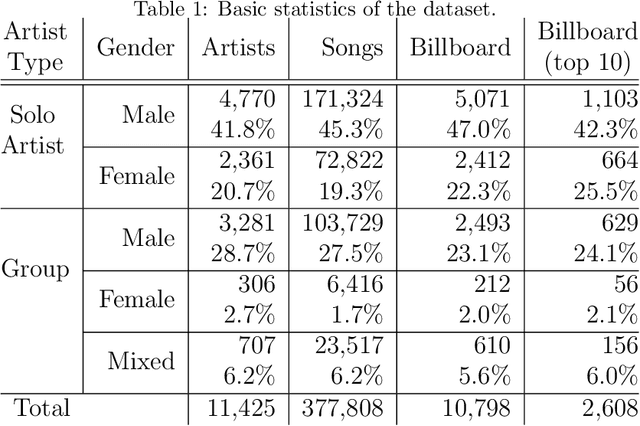
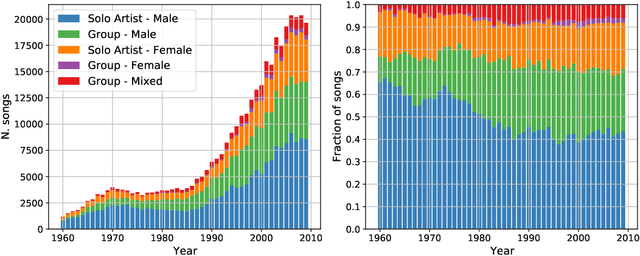
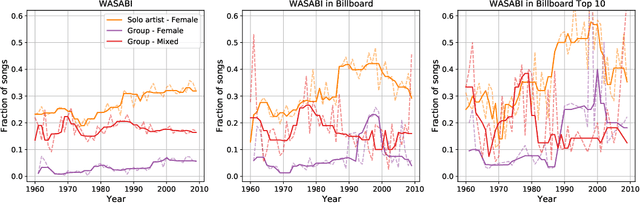
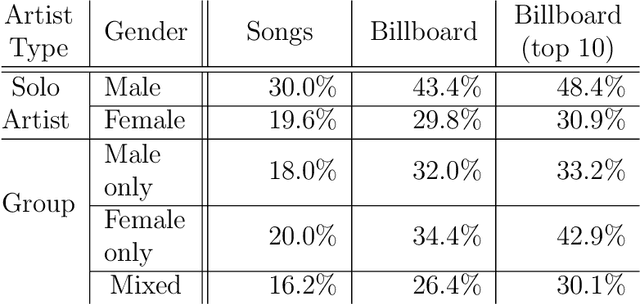
We employ Natural Language Processing techniques to analyse 377808 English song lyrics from the "Two Million Song Database" corpus, focusing on the expression of sexism across five decades (1960-2010) and the measurement of gender biases. Using a sexism classifier, we identify sexist lyrics at a larger scale than previous studies using small samples of manually annotated popular songs. Furthermore, we reveal gender biases by measuring associations in word embeddings learned on song lyrics. We find sexist content to increase across time, especially from male artists and for popular songs appearing in Billboard charts. Songs are also shown to contain different language biases depending on the gender of the performer, with male solo artist songs containing more and stronger biases. This is the first large scale analysis of this type, giving insights into language usage in such an influential part of popular culture.
Counterfactual Graphs for Explainable Classification of Brain Networks
Jun 18, 2021
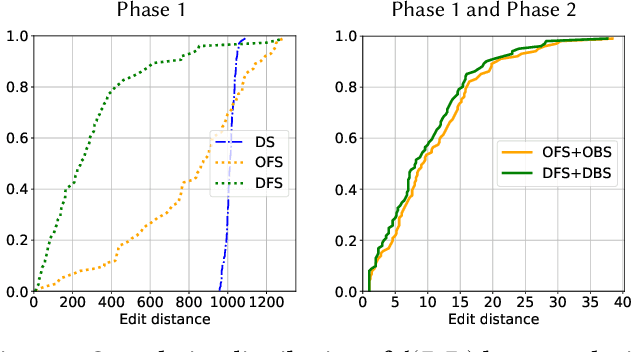
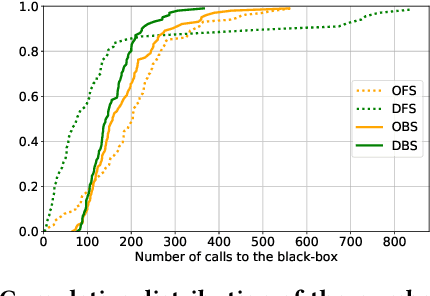
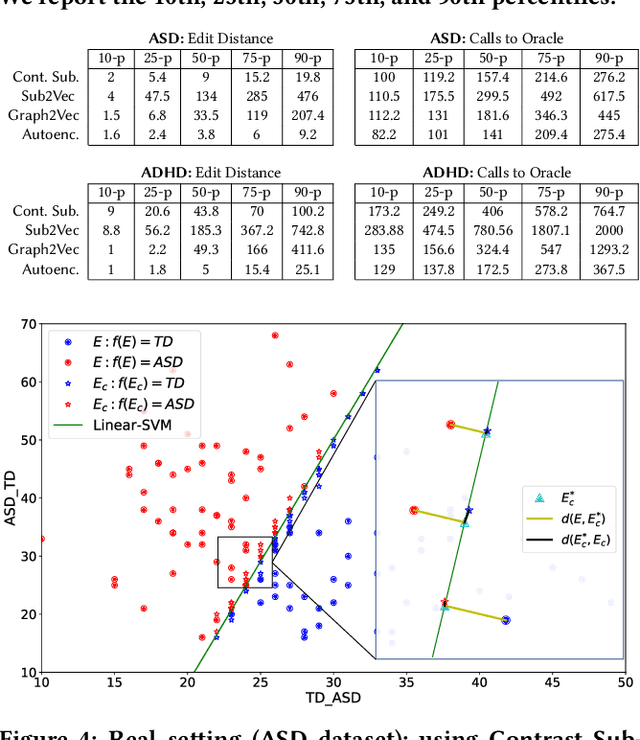
Training graph classifiers able to distinguish between healthy brains and dysfunctional ones, can help identifying substructures associated to specific cognitive phenotypes. However, the mere predictive power of the graph classifier is of limited interest to the neuroscientists, which have plenty of tools for the diagnosis of specific mental disorders. What matters is the interpretation of the model, as it can provide novel insights and new hypotheses. In this paper we propose \emph{counterfactual graphs} as a way to produce local post-hoc explanations of any black-box graph classifier. Given a graph and a black-box, a counterfactual is a graph which, while having high structural similarity with the original graph, is classified by the black-box in a different class. We propose and empirically compare several strategies for counterfactual graph search. Our experiments against a white-box classifier with known optimal counterfactual, show that our methods, although heuristic, can produce counterfactuals very close to the optimal one. Finally, we show how to use counterfactual graphs to build global explanations correctly capturing the behaviour of different black-box classifiers and providing interesting insights for the neuroscientists.