 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounterfactual Graphs for Explainable Classification of Brain Networks
Paper and Code

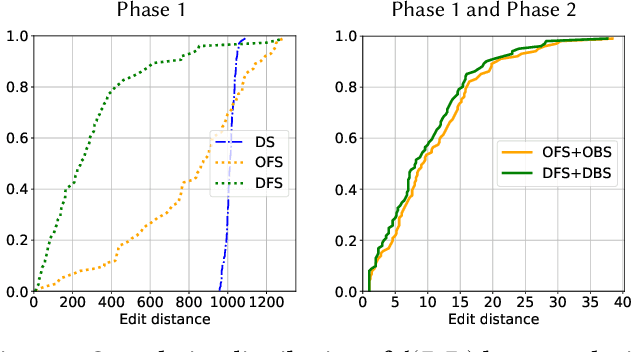
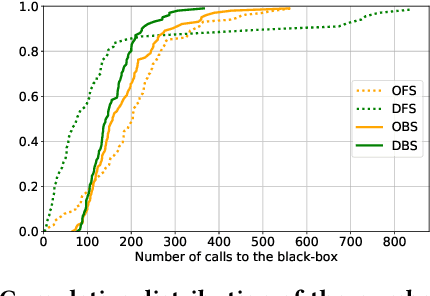
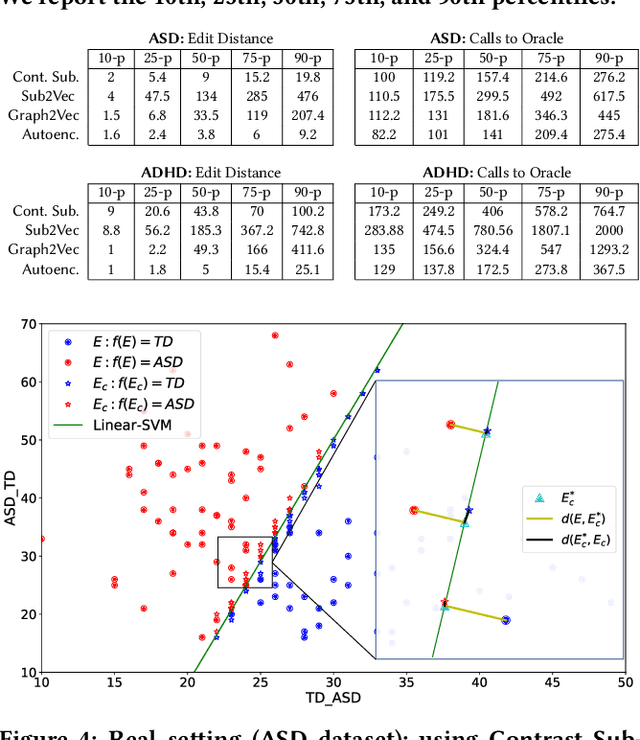
Training graph classifiers able to distinguish between healthy brains and dysfunctional ones, can help identifying substructures associated to specific cognitive phenotypes. However, the mere predictive power of the graph classifier is of limited interest to the neuroscientists, which have plenty of tools for the diagnosis of specific mental disorders. What matters is the interpretation of the model, as it can provide novel insights and new hypotheses. In this paper we propose \emph{counterfactual graphs} as a way to produce local post-hoc explanations of any black-box graph classifier. Given a graph and a black-box, a counterfactual is a graph which, while having high structural similarity with the original graph, is classified by the black-box in a different class. We propose and empirically compare several strategies for counterfactual graph search. Our experiments against a white-box classifier with known optimal counterfactual, show that our methods, although heuristic, can produce counterfactuals very close to the optimal one. Finally, we show how to use counterfactual graphs to build global explanations correctly capturing the behaviour of different black-box classifiers and providing interesting insights for the neuroscientists.