 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfidence Matters: Uncertainty Quantification and Precision Assessment of Deep Learning-based CMR Biomarker Estimates Using Scan-rescan Data
Mar 25, 2026The performance of deep learning (DL) methods for the analysis of cine cardiovascular magnetic resonance (CMR) is typically assessed in terms of accuracy, overlooking precision. In this work, uncertainty estimation techniques, namely deep ensemble, test-time augmentation, and Monte Carlo dropout, are applied to a state-of-the-art DL pipeline for cardiac functional biomarker estimation, and new distribution-based metrics are proposed for the assessment of biomarker precision. The model achieved high accuracy (average Dice 87%) and point estimate precision on two external validation scan-rescan CMR datasets. However, distribution-based metrics showed that the overlap between scan/rescan confidence intervals was >50% in less than 45% of the cases. Statistical similarity tests between scan and rescan biomarkers also resulted in significant differences for over 65% of the cases. We conclude that, while point estimate metrics might suggest good performance, distributional analyses reveal lower precision, highlighting the need to use more representative metrics to assess scan-rescan agreement.
Implicit Neural Representations of Intramyocardial Motion and Strain
Sep 10, 2025Automatic quantification of intramyocardial motion and strain from tagging MRI remains an important but challenging task. We propose a method using implicit neural representations (INRs), conditioned on learned latent codes, to predict continuous left ventricular (LV) displacement -- without requiring inference-time optimisation. Evaluated on 452 UK Biobank test cases, our method achieved the best tracking accuracy (2.14 mm RMSE) and the lowest combined error in global circumferential (2.86%) and radial (6.42%) strain compared to three deep learning baselines. In addition, our method is $\sim$380$\times$ faster than the most accurate baseline. These results highlight the suitability of INR-based models for accurate and scalable analysis of myocardial strain in large CMR datasets.
SHAP-based Explanations are Sensitive to Feature Representation
May 13, 2025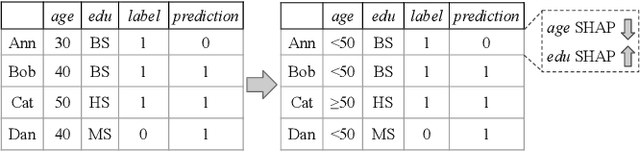
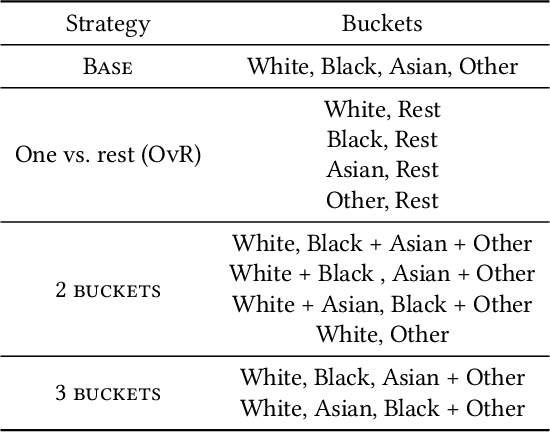
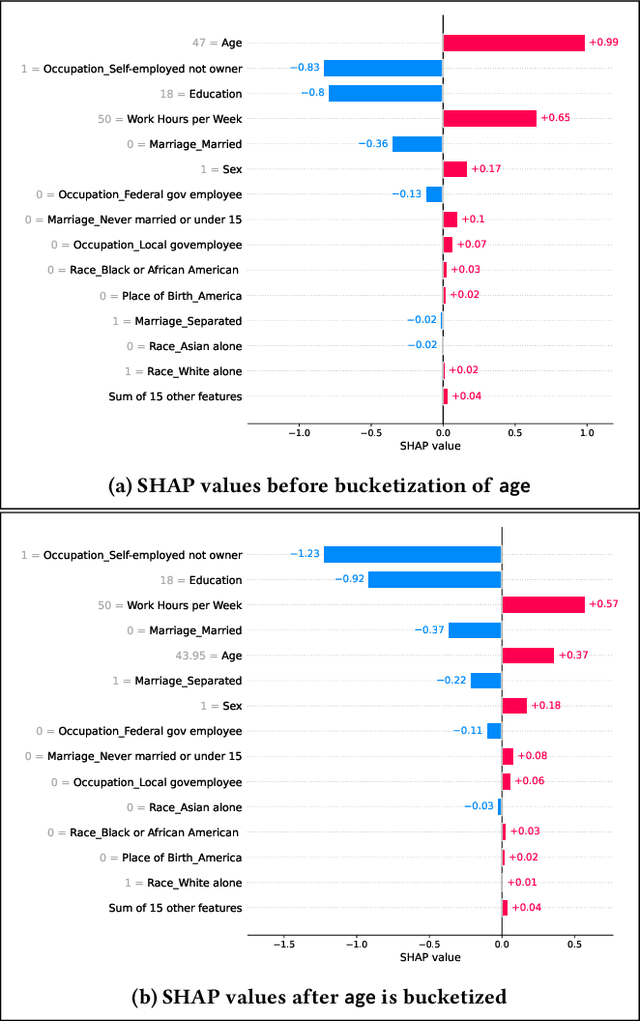
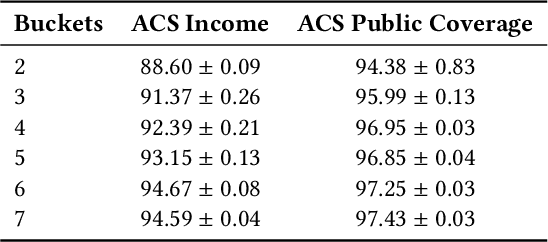
Local feature-based explanations are a key component of the XAI toolkit. These explanations compute feature importance values relative to an ``interpretable'' feature representation. In tabular data, feature values themselves are often considered interpretable. This paper examines the impact of data engineering choices on local feature-based explanations. We demonstrate that simple, common data engineering techniques, such as representing age with a histogram or encoding race in a specific way, can manipulate feature importance as determined by popular methods like SHAP. Notably, the sensitivity of explanations to feature representation can be exploited by adversaries to obscure issues like discrimination. While the intuition behind these results is straightforward, their systematic exploration has been lacking. Previous work has focused on adversarial attacks on feature-based explainers by biasing data or manipulating models. To the best of our knowledge, this is the first study demonstrating that explainers can be misled by standard, seemingly innocuous data engineering techniques.
Faster, Cheaper, Better: Multi-Objective Hyperparameter Optimization for LLM and RAG Systems
Feb 25, 2025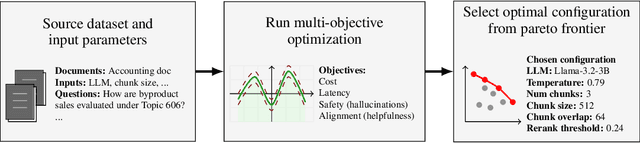



While Retrieval Augmented Generation (RAG) has emerged as a popular technique for improving Large Language Model (LLM) systems, it introduces a large number of choices, parameters and hyperparameters that must be made or tuned. This includes the LLM, embedding, and ranker models themselves, as well as hyperparameters governing individual RAG components. Yet, collectively optimizing the entire configuration in a RAG or LLM system remains under-explored - especially in multi-objective settings - due to intractably large solution spaces, noisy objective evaluations, and the high cost of evaluations. In this work, we introduce the first approach for multi-objective parameter optimization of cost, latency, safety and alignment over entire LLM and RAG systems. We find that Bayesian optimization methods significantly outperform baseline approaches, obtaining a superior Pareto front on two new RAG benchmark tasks. We conclude our work with important considerations for practitioners who are designing multi-objective RAG systems, highlighting nuances such as how optimal configurations may not generalize across tasks and objectives.
Safeguarding Large Language Models in Real-time with Tunable Safety-Performance Trade-offs
Jan 02, 2025



Large Language Models (LLMs) have been shown to be susceptible to jailbreak attacks, or adversarial attacks used to illicit high risk behavior from a model. Jailbreaks have been exploited by cybercriminals and blackhat actors to cause significant harm, highlighting the critical need to safeguard widely-deployed models. Safeguarding approaches, which include fine-tuning models or having LLMs "self-reflect", may lengthen the inference time of a model, incur a computational penalty, reduce the semantic fluency of an output, and restrict ``normal'' model behavior. Importantly, these Safety-Performance Trade-offs (SPTs) remain an understudied area. In this work, we introduce a novel safeguard, called SafeNudge, that combines Controlled Text Generation with "nudging", or using text interventions to change the behavior of a model. SafeNudge triggers during text-generation while a jailbreak attack is being executed, and can reduce successful jailbreak attempts by 30% by guiding the LLM towards a safe responses. It adds minimal latency to inference and has a negligible impact on the semantic fluency of outputs. Further, we allow for tunable SPTs. SafeNudge is open-source and available through https://pypi.org/, and is compatible with models loaded with the Hugging Face "transformers" library.
Making Transparency Advocates: An Educational Approach Towards Better Algorithmic Transparency in Practice
Dec 19, 2024



Concerns about the risks and harms posed by artificial intelligence (AI) have resulted in significant study into algorithmic transparency, giving rise to a sub-field known as Explainable AI (XAI). Unfortunately, despite a decade of development in XAI, an existential challenge remains: progress in research has not been fully translated into the actual implementation of algorithmic transparency by organizations. In this work, we test an approach for addressing the challenge by creating transparency advocates, or motivated individuals within organizations who drive a ground-up cultural shift towards improved algorithmic transparency. Over several years, we created an open-source educational workshop on algorithmic transparency and advocacy. We delivered the workshop to professionals across two separate domains to improve their algorithmic transparency literacy and willingness to advocate for change. In the weeks following the workshop, participants applied what they learned, such as speaking up for algorithmic transparency at an organization-wide AI strategy meeting. We also make two broader observations: first, advocacy is not a monolith and can be broken down into different levels. Second, individuals' willingness for advocacy is affected by their professional field. For example, news and media professionals may be more likely to advocate for algorithmic transparency than those working at technology start-ups.
Output Scouting: Auditing Large Language Models for Catastrophic Responses
Oct 04, 2024



Recent high profile incidents in which the use of Large Language Models (LLMs) resulted in significant harm to individuals have brought about a growing interest in AI safety. One reason LLM safety issues occur is that models often have at least some non-zero probability of producing harmful outputs. In this work, we explore the following scenario: imagine an AI safety auditor is searching for catastrophic responses from an LLM (e.g. a "yes" responses to "can I fire an employee for being pregnant?"), and is able to query the model a limited number times (e.g. 1000 times). What is a strategy for querying the model that would efficiently find those failure responses? To this end, we propose output scouting: an approach that aims to generate semantically fluent outputs to a given prompt matching any target probability distribution. We then run experiments using two LLMs and find numerous examples of catastrophic responses. We conclude with a discussion that includes advice for practitioners who are looking to implement LLM auditing for catastrophic responses. We also release an open-source toolkit (https://github.com/joaopfonseca/outputscouting) that implements our auditing framework using the Hugging Face transformers library.
Fairness in Algorithmic Recourse Through the Lens of Substantive Equality of Opportunity
Jan 29, 2024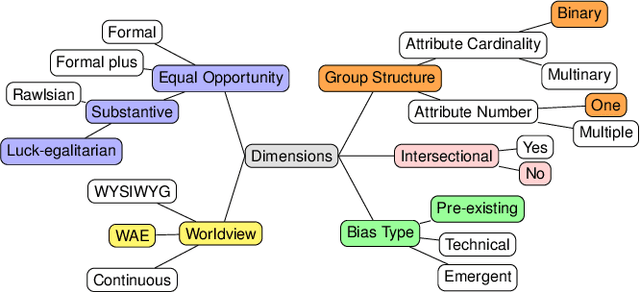
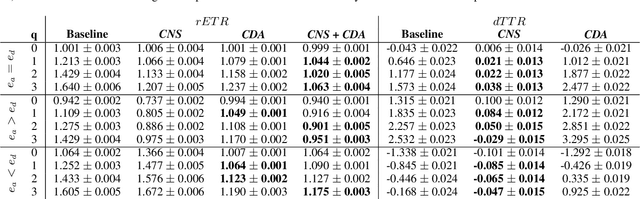
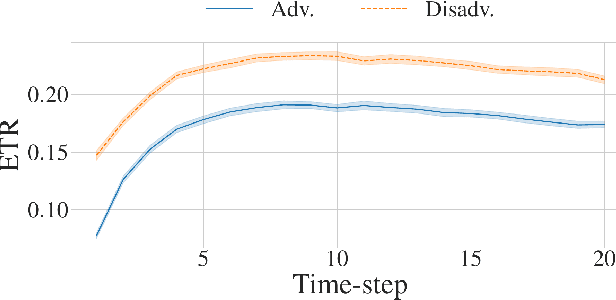
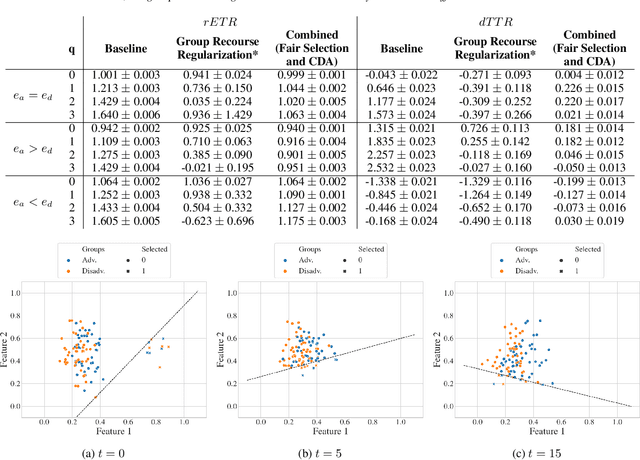
Algorithmic recourse -- providing recommendations to those affected negatively by the outcome of an algorithmic system on how they can take action and change that outcome -- has gained attention as a means of giving persons agency in their interactions with artificial intelligence (AI) systems. Recent work has shown that even if an AI decision-making classifier is ``fair'' (according to some reasonable criteria), recourse itself may be unfair due to differences in the initial circumstances of individuals, compounding disparities for marginalized populations and requiring them to exert more effort than others. There is a need to define more methods and metrics for evaluating fairness in recourse that span a range of normative views of the world, and specifically those that take into account time. Time is a critical element in recourse because the longer it takes an individual to act, the more the setting may change due to model or data drift. This paper seeks to close this research gap by proposing two notions of fairness in recourse that are in normative alignment with substantive equality of opportunity, and that consider time. The first considers the (often repeated) effort individuals exert per successful recourse event, and the second considers time per successful recourse event. Building upon an agent-based framework for simulating recourse, this paper demonstrates how much effort is needed to overcome disparities in initial circumstances. We then proposes an intervention to improve the fairness of recourse by rewarding effort, and compare it to existing strategies.
Setting the Right Expectations: Algorithmic Recourse Over Time
Sep 13, 2023


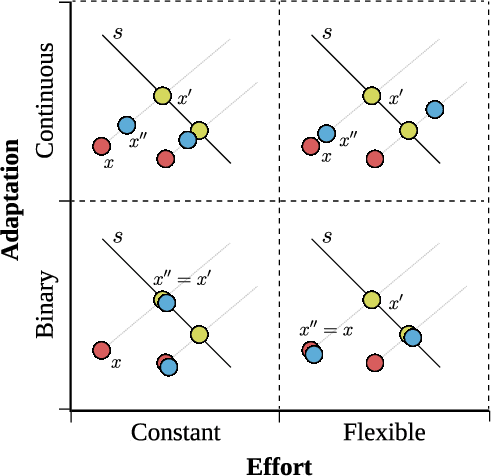
Algorithmic systems are often called upon to assist in high-stakes decision making. In light of this, algorithmic recourse, the principle wherein individuals should be able to take action against an undesirable outcome made by an algorithmic system, is receiving growing attention. The bulk of the literature on algorithmic recourse to-date focuses primarily on how to provide recourse to a single individual, overlooking a critical element: the effects of a continuously changing context. Disregarding these effects on recourse is a significant oversight, since, in almost all cases, recourse consists of an individual making a first, unfavorable attempt, and then being given an opportunity to make one or several attempts at a later date - when the context might have changed. This can create false expectations, as initial recourse recommendations may become less reliable over time due to model drift and competition for access to the favorable outcome between individuals. In this work we propose an agent-based simulation framework for studying the effects of a continuously changing environment on algorithmic recourse. In particular, we identify two main effects that can alter the reliability of recourse for individuals represented by the agents: (1) competition with other agents acting upon recourse, and (2) competition with new agents entering the environment. Our findings highlight that only a small set of specific parameterizations result in algorithmic recourse that is reliable for agents over time. Consequently, we argue that substantial additional work is needed to understand recourse reliability over time, and to develop recourse methods that reward agents' effort.
The Possibility of Fairness: Revisiting the Impossibility Theorem in Practice
Feb 13, 2023The ``impossibility theorem'' -- which is considered foundational in algorithmic fairness literature -- asserts that there must be trade-offs between common notions of fairness and performance when fitting statistical models, except in two special cases: when the prevalence of the outcome being predicted is equal across groups, or when a perfectly accurate predictor is used. However, theory does not always translate to practice. In this work, we challenge the implications of the impossibility theorem in practical settings. First, we show analytically that, by slightly relaxing the impossibility theorem (to accommodate a \textit{practitioner's} perspective of fairness), it becomes possible to identify a large set of models that satisfy seemingly incompatible fairness constraints. Second, we demonstrate the existence of these models through extensive experiments on five real-world datasets. We conclude by offering tools and guidance for practitioners to understand when -- and to what degree -- fairness along multiple criteria can be achieved. For example, if one allows only a small margin-of-error between metrics, there exists a large set of models simultaneously satisfying \emph{False Negative Rate Parity}, \emph{False Positive Rate Parity}, and \emph{Positive Predictive Value Parity}, even when there is a moderate prevalence difference between groups. This work has an important implication for the community: achieving fairness along multiple metrics for multiple groups (and their intersections) is much more possible than was previously believed.