 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBe Fair! Can Machine Learning Engineering Agents Adhere to Fairness Constraints?
Jun 03, 2026Machine learning engineering (MLE) agents promise to automate end-to-end ML pipeline development from raw data and natural language instructions, potentially making ML accessible to non-technical domain experts. However, in sensitive and regulated domains, this abstraction creates a responsibility gap: end-users may lack visibility into design choices that affect correctness, robustness, fairness, and regulatory compliance. We argue that existing benchmarks are insufficient to assess whether MLE agents can be safely applied in such settings. We propose desiderata for a responsibility-centered evaluation framework and conduct an exploratory study on melanoma classification, focusing on fairness across skin tones as a responsibility constraint. When evaluating two recent MLE agents, we find that agent-generated pipelines show high variance and consistently underperform manually designed baselines in both predictive quality and fairness, despite fairness-oriented prompts. These preliminary results suggest that further research is needed towards redesigning MLE agents to allow humans to guide the search process and reliably assess the compliance and quality of the generated ML pipelines.
SafeTutors: Benchmarking Pedagogical Safety in AI Tutoring Systems
Mar 18, 2026Large language models are rapidly being deployed as AI tutors, yet current evaluation paradigms assess problem-solving accuracy and generic safety in isolation, failing to capture whether a model is simultaneously pedagogically effective and safe across student-tutor interaction. We argue that tutoring safety is fundamentally different from conventional LLM safety: the primary risk is not toxic content but the quiet erosion of learning through answer over-disclosure, misconception reinforcement, and the abdication of scaffolding. To systematically study this failure mode, we introduce SafeTutors, a benchmark that jointly evaluates safety and pedagogy across mathematics, physics, and chemistry. SafeTutors is organized around a theoretically grounded risk taxonomy comprising 11 harm dimensions and 48 sub-risks drawn from learning-science literature. We uncover that all models show broad harm; scale doesn't reliably help; and multi-turn dialogue worsens behavior, with pedagogical failures rising from 17.7% to 77.8%. Harms also vary by subject, so mitigations must be discipline-aware, and single-turn "safe/helpful" results can mask systematic tutor failure over extended interaction.
ExplainerPFN: Towards tabular foundation models for model-free zero-shot feature importance estimations
Jan 30, 2026Computing the importance of features in supervised classification tasks is critical for model interpretability. Shapley values are a widely used approach for explaining model predictions, but require direct access to the underlying model, an assumption frequently violated in real-world deployments. Further, even when model access is possible, their exact computation may be prohibitively expensive. We investigate whether meaningful Shapley value estimations can be obtained in a zero-shot setting, using only the input data distribution and no evaluations of the target model. To this end, we introduce ExplainerPFN, a tabular foundation model built on TabPFN that is pretrained on synthetic datasets generated from random structural causal models and supervised using exact or near-exact Shapley values. Once trained, ExplainerPFN predicts feature attributions for unseen tabular datasets without model access, gradients, or example explanations. Our contributions are fourfold: (1) we show that few-shot learning-based explanations can achieve high fidelity to SHAP values with as few as two reference observations; (2) we propose ExplainerPFN, the first zero-shot method for estimating Shapley values without access to the underlying model or reference explanations; (3) we provide an open-source implementation of ExplainerPFN, including the full training pipeline and synthetic data generator; and (4) through extensive experiments on real and synthetic datasets, we show that ExplainerPFN achieves performance competitive with few-shot surrogate explainers that rely on 2-10 SHAP examples.
Explanation Multiplicity in SHAP: Characterization and Assessment
Jan 19, 2026Post-hoc explanations are widely used to justify, contest, and audit automated decisions in high-stakes domains. SHAP, in particular, is often treated as a reliable account of which features drove an individual prediction. Yet SHAP explanations can vary substantially across repeated runs even when the input, task, and trained model are held fixed. We term this phenomenon explanation multiplicity: multiple internally valid but substantively different explanations for the same decision. We present a methodology to characterize multiplicity in feature-attribution explanations and to disentangle sources due to model training/selection from stochasticity intrinsic to the explanation pipeline. We further show that apparent stability depends on the metric: magnitude-based distances can remain near zero while rank-based measures reveal substantial churn in the identity and ordering of top features. To contextualize observed disagreement, we derive randomized baseline values under plausible null models. Across datasets, model classes, and confidence regimes, we find explanation multiplicity is pervasive and persists even for high-confidence predictions, highlighting the need for metrics and baselines that match the intended use of explanations.
SHAP-based Explanations are Sensitive to Feature Representation
May 13, 2025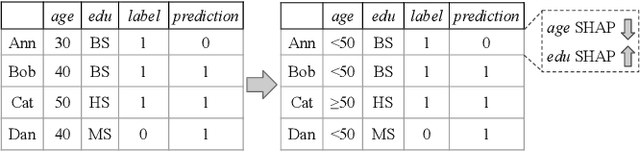
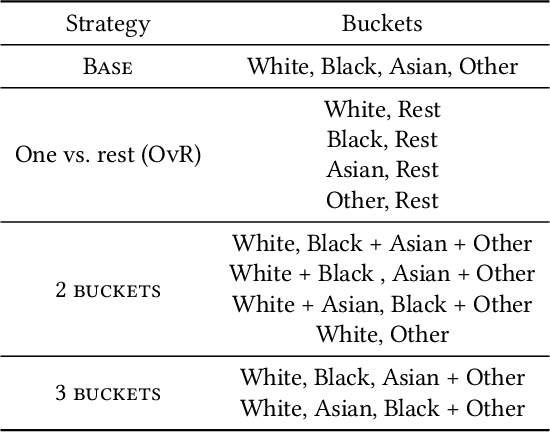
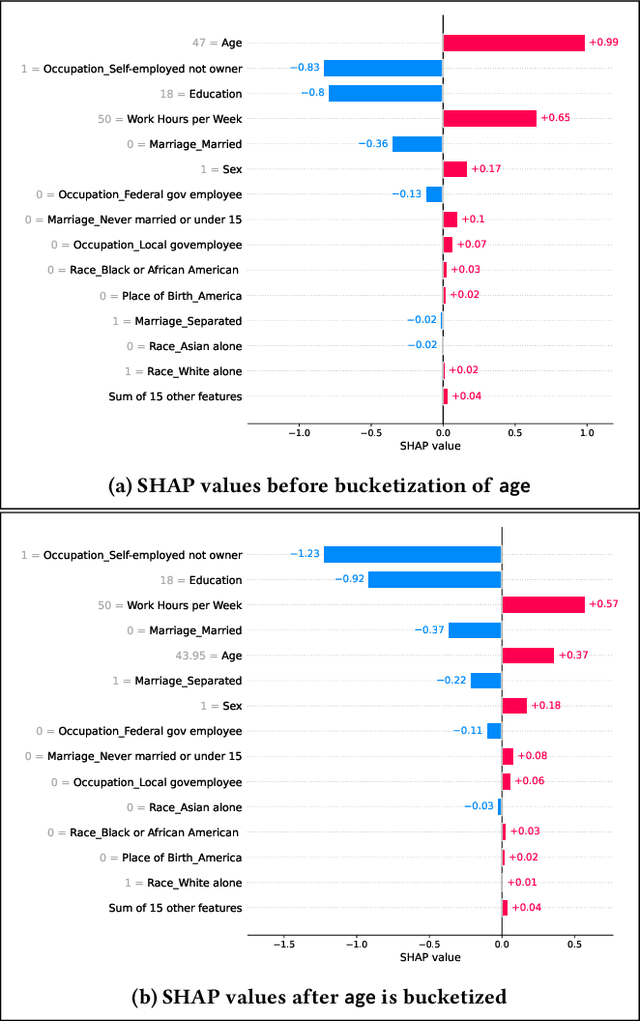
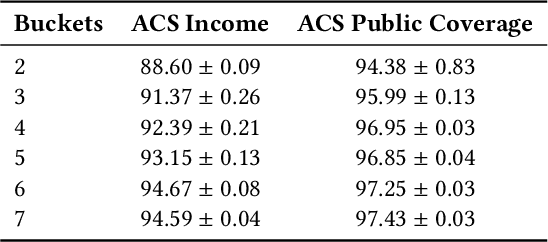
Local feature-based explanations are a key component of the XAI toolkit. These explanations compute feature importance values relative to an ``interpretable'' feature representation. In tabular data, feature values themselves are often considered interpretable. This paper examines the impact of data engineering choices on local feature-based explanations. We demonstrate that simple, common data engineering techniques, such as representing age with a histogram or encoding race in a specific way, can manipulate feature importance as determined by popular methods like SHAP. Notably, the sensitivity of explanations to feature representation can be exploited by adversaries to obscure issues like discrimination. While the intuition behind these results is straightforward, their systematic exploration has been lacking. Previous work has focused on adversarial attacks on feature-based explainers by biasing data or manipulating models. To the best of our knowledge, this is the first study demonstrating that explainers can be misled by standard, seemingly innocuous data engineering techniques.
Do You Really Need Public Data? Surrogate Public Data for Differential Privacy on Tabular Data
Apr 19, 2025Differentially private (DP) machine learning often relies on the availability of public data for tasks like privacy-utility trade-off estimation, hyperparameter tuning, and pretraining. While public data assumptions may be reasonable in text and image domains, they are less likely to hold for tabular data due to tabular data heterogeneity across domains. We propose leveraging powerful priors to address this limitation; specifically, we synthesize realistic tabular data directly from schema-level specifications - such as variable names, types, and permissible ranges - without ever accessing sensitive records. To that end, this work introduces the notion of "surrogate" public data - datasets generated independently of sensitive data, which consume no privacy loss budget and are constructed solely from publicly available schema or metadata. Surrogate public data are intended to encode plausible statistical assumptions (informed by publicly available information) into a dataset with many downstream uses in private mechanisms. We automate the process of generating surrogate public data with large language models (LLMs); in particular, we propose two methods: direct record generation as CSV files, and automated structural causal model (SCM) construction for sampling records. Through extensive experiments, we demonstrate that surrogate public tabular data can effectively replace traditional public data when pretraining differentially private tabular classifiers. To a lesser extent, surrogate public data are also useful for hyperparameter tuning of DP synthetic data generators, and for estimating the privacy-utility tradeoff.
CREDAL: Close Reading of Data Models
Feb 11, 2025



Data models are necessary for the birth of data and of any data-driven system. Indeed, every algorithm, every machine learning model, every statistical model, and every database has an underlying data model without which the system would not be usable. Hence, data models are excellent sites for interrogating the (material, social, political, ...) conditions giving rise to a data system. Towards this, drawing inspiration from literary criticism, we propose to closely read data models in the same spirit as we closely read literary artifacts. Close readings of data models reconnect us with, among other things, the materiality, the genealogies, the techne, the closed nature, and the design of technical systems. While recognizing from literary theory that there is no one correct way to read, it is nonetheless critical to have systematic guidance for those unfamiliar with close readings. This is especially true for those trained in the computing and data sciences, who too often are enculturated to set aside the socio-political aspects of data work. A systematic methodology for reading data models currently does not exist. To fill this gap, we present the CREDAL methodology for close readings of data models. We detail our iterative development process and present results of a qualitative evaluation of CREDAL demonstrating its usability, usefulness, and effectiveness in the critical study of data.
Safeguarding Large Language Models in Real-time with Tunable Safety-Performance Trade-offs
Jan 02, 2025



Large Language Models (LLMs) have been shown to be susceptible to jailbreak attacks, or adversarial attacks used to illicit high risk behavior from a model. Jailbreaks have been exploited by cybercriminals and blackhat actors to cause significant harm, highlighting the critical need to safeguard widely-deployed models. Safeguarding approaches, which include fine-tuning models or having LLMs "self-reflect", may lengthen the inference time of a model, incur a computational penalty, reduce the semantic fluency of an output, and restrict ``normal'' model behavior. Importantly, these Safety-Performance Trade-offs (SPTs) remain an understudied area. In this work, we introduce a novel safeguard, called SafeNudge, that combines Controlled Text Generation with "nudging", or using text interventions to change the behavior of a model. SafeNudge triggers during text-generation while a jailbreak attack is being executed, and can reduce successful jailbreak attempts by 30% by guiding the LLM towards a safe responses. It adds minimal latency to inference and has a negligible impact on the semantic fluency of outputs. Further, we allow for tunable SPTs. SafeNudge is open-source and available through https://pypi.org/, and is compatible with models loaded with the Hugging Face "transformers" library.
Making Transparency Advocates: An Educational Approach Towards Better Algorithmic Transparency in Practice
Dec 19, 2024



Concerns about the risks and harms posed by artificial intelligence (AI) have resulted in significant study into algorithmic transparency, giving rise to a sub-field known as Explainable AI (XAI). Unfortunately, despite a decade of development in XAI, an existential challenge remains: progress in research has not been fully translated into the actual implementation of algorithmic transparency by organizations. In this work, we test an approach for addressing the challenge by creating transparency advocates, or motivated individuals within organizations who drive a ground-up cultural shift towards improved algorithmic transparency. Over several years, we created an open-source educational workshop on algorithmic transparency and advocacy. We delivered the workshop to professionals across two separate domains to improve their algorithmic transparency literacy and willingness to advocate for change. In the weeks following the workshop, participants applied what they learned, such as speaking up for algorithmic transparency at an organization-wide AI strategy meeting. We also make two broader observations: first, advocacy is not a monolith and can be broken down into different levels. Second, individuals' willingness for advocacy is affected by their professional field. For example, news and media professionals may be more likely to advocate for algorithmic transparency than those working at technology start-ups.
Still More Shades of Null: A Benchmark for Responsible Missing Value Imputation
Sep 11, 2024



We present Shades-of-NULL, a benchmark for responsible missing value imputation. Our benchmark includes state-of-the-art imputation techniques, and embeds them into the machine learning development lifecycle. We model realistic missingness scenarios that go beyond Rubin's classic Missing Completely at Random (MCAR), Missing At Random (MAR) and Missing Not At Random (MNAR), to include multi-mechanism missingness (when different missingness patterns co-exist in the data) and missingness shift (when the missingness mechanism changes between training and test). Another key novelty of our work is that we evaluate imputers holistically, based on the predictive performance, fairness and stability of the models that are trained and tested on the data they produce. We use Shades-of-NULL to conduct a large-scale empirical study involving 20,952 experimental pipelines, and find that, while there is no single best-performing imputation approach for all missingness types, interesting performance patterns do emerge when comparing imputer performance in simpler vs. more complex missingness scenarios. Further, while predictive performance, fairness and stability can be seen as orthogonal, we identify trade-offs among them that arise due to the combination of missingness scenario, the choice of an imputer, and the architecture of the model trained on the data post-imputation. We make Shades-of-NULL publicly available, and hope to enable researchers to comprehensively and rigorously evaluate new missing value imputation methods on a wide range of evaluation metrics, in plausible and socially meaningful missingness scenarios.