 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlack Box Causal Inference: Effect Estimation via Meta Prediction
Mar 07, 2025



Causal inference and the estimation of causal effects plays a central role in decision-making across many areas, including healthcare and economics. Estimating causal effects typically requires an estimator that is tailored to each problem of interest. But developing estimators can take significant effort for even a single causal inference setting. For example, algorithms for regression-based estimators, propensity score methods, and doubly robust methods were designed across several decades to handle causal estimation with observed confounders. Similarly, several estimators have been developed to exploit instrumental variables (IVs), including two-stage least-squares (TSLS), control functions, and the method-of-moments. In this work, we instead frame causal inference as a dataset-level prediction problem, offloading algorithm design to the learning process. The approach we introduce, called black box causal inference (BBCI), builds estimators in a black-box manner by learning to predict causal effects from sampled dataset-effect pairs. We demonstrate accurate estimation of average treatment effects (ATEs) and conditional average treatment effects (CATEs) with BBCI across several causal inference problems with known identification, including problems with less developed estimators.
Language Models as Causal Effect Generators
Nov 12, 2024We present a framework for large language model (LLM) based data generation with controllable causal structure. In particular, we define a procedure for turning any language model and any directed acyclic graph (DAG) into a sequence-driven structural causal model (SD-SCM). Broadly speaking, an SD-SCM is a causal model with user-defined structure and LLM-defined structural equations. We characterize how an SD-SCM allows sampling from observational, interventional, and counterfactual distributions according to the desired causal structure. We then leverage this procedure to propose a new type of benchmark for causal inference methods, generating individual-level counterfactual data without needing to manually specify functional relationships between variables. We create an example benchmark consisting of thousands of datasets, and test a suite of popular estimation methods on these datasets for average, conditional average, and individual treatment effect estimation, both with and without hidden confounding. Apart from generating data, the same procedure also allows us to test for the presence of a causal effect that might be encoded in an LLM. This procedure can underpin auditing LLMs for misinformation, discrimination, or otherwise undesirable behavior. We believe SD-SCMs can serve as a useful tool in any application that would benefit from sequential data with controllable causal structure.
A New Paradigm for Counterfactual Reasoning in Fairness and Recourse
Jan 25, 2024



Counterfactuals and counterfactual reasoning underpin numerous techniques for auditing and understanding artificial intelligence (AI) systems. The traditional paradigm for counterfactual reasoning in this literature is the interventional counterfactual, where hypothetical interventions are imagined and simulated. For this reason, the starting point for causal reasoning about legal protections and demographic data in AI is an imagined intervention on a legally-protected characteristic, such as ethnicity, race, gender, disability, age, etc. We ask, for example, what would have happened had your race been different? An inherent limitation of this paradigm is that some demographic interventions -- like interventions on race -- may not translate into the formalisms of interventional counterfactuals. In this work, we explore a new paradigm based instead on the backtracking counterfactual, where rather than imagine hypothetical interventions on legally-protected characteristics, we imagine alternate initial conditions while holding these characteristics fixed. We ask instead, what would explain a counterfactual outcome for you as you actually are or could be? This alternate framework allows us to address many of the same social concerns, but to do so while asking fundamentally different questions that do not rely on demographic interventions.
Causal Dependence Plots for Interpretable Machine Learning
Mar 07, 2023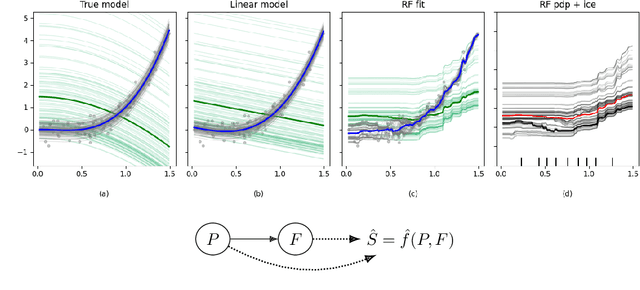



Explaining artificial intelligence or machine learning models is an increasingly important problem. For humans to stay in the loop and control such systems, we must be able to understand how they interact with the world. This work proposes using known or assumed causal structure in the input variables to produce simple and practical explanations of supervised learning models. Our explanations -- which we name Causal Dependence Plots or CDP -- visualize how the model output depends on changes in a given predictor \emph{along with any consequent causal changes in other predictors}. Since this causal dependence captures how humans often think about input-output dependence, CDPs can be powerful tools in the explainable AI or interpretable ML toolkit and contribute to applications including scientific machine learning and algorithmic fairness. CDP can also be used for model-agnostic or black-box explanations.
Counterfactuals for the Future
Dec 07, 2022Counterfactuals are often described as 'retrospective,' focusing on hypothetical alternatives to a realized past. This description relates to an often implicit assumption about the structure and stability of exogenous variables in the system being modeled -- an assumption that is reasonable in many settings where counterfactuals are used. In this work, we consider cases where we might reasonably make a different assumption about exogenous variables, namely, that the exogenous noise terms of each unit do exhibit some unit-specific structure and/or stability. This leads us to a different use of counterfactuals -- a 'forward-looking' rather than 'retrospective' counterfactual. We introduce "counterfactual treatment choice," a type of treatment choice problem that motivates using forward-looking counterfactuals. We then explore how mismatches between interventional versus forward-looking counterfactual approaches to treatment choice, consistent with different assumptions about exogenous noise, can lead to counterintuitive results.
Impact Remediation: Optimal Interventions to Reduce Inequality
Jul 01, 2021

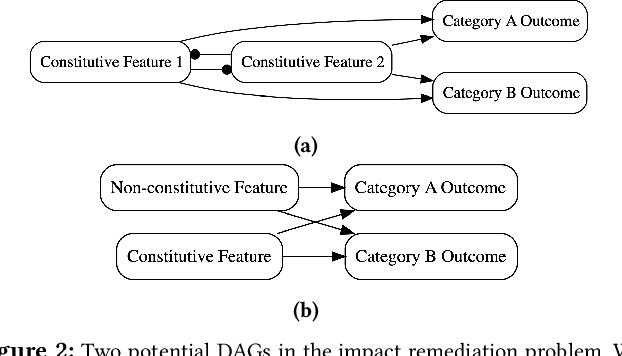
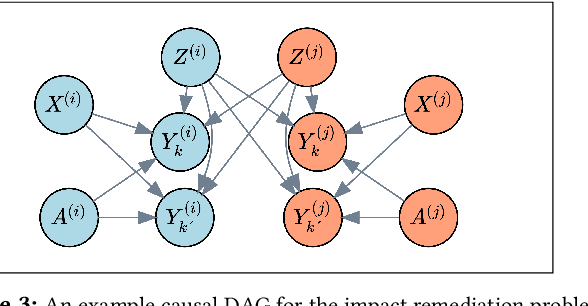
A significant body of research in the data sciences considers unfair discrimination against social categories such as race or gender that could occur or be amplified as a result of algorithmic decisions. Simultaneously, real-world disparities continue to exist, even before algorithmic decisions are made. In this work, we draw on insights from the social sciences and humanistic studies brought into the realm of causal modeling and constrained optimization, and develop a novel algorithmic framework for tackling pre-existing real-world disparities. The purpose of our framework, which we call the "impact remediation framework," is to measure real-world disparities and discover the optimal intervention policies that could help improve equity or access to opportunity for those who are underserved with respect to an outcome of interest. We develop a disaggregated approach to tackling pre-existing disparities that relaxes the typical set of assumptions required for the use of social categories in structural causal models. Our approach flexibly incorporates counterfactuals and is compatible with various ontological assumptions about the nature of social categories. We demonstrate impact remediation with a real-world case study and compare our disaggregated approach to an existing state-of-the-art approach, comparing its structure and resulting policy recommendations. In contrast to most work on optimal policy learning, we explore disparity reduction itself as an objective, explicitly focusing the power of algorithms on reducing inequality.