 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlack Box Causal Inference: Effect Estimation via Meta Prediction
Mar 07, 2025



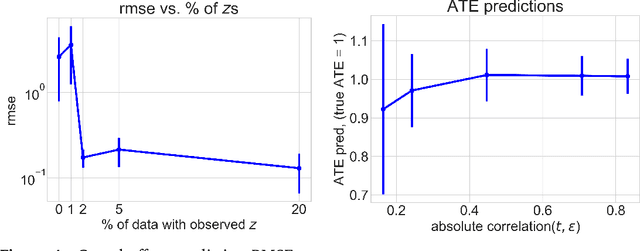
Causal inference and the estimation of causal effects plays a central role in decision-making across many areas, including healthcare and economics. Estimating causal effects typically requires an estimator that is tailored to each problem of interest. But developing estimators can take significant effort for even a single causal inference setting. For example, algorithms for regression-based estimators, propensity score methods, and doubly robust methods were designed across several decades to handle causal estimation with observed confounders. Similarly, several estimators have been developed to exploit instrumental variables (IVs), including two-stage least-squares (TSLS), control functions, and the method-of-moments. In this work, we instead frame causal inference as a dataset-level prediction problem, offloading algorithm design to the learning process. The approach we introduce, called black box causal inference (BBCI), builds estimators in a black-box manner by learning to predict causal effects from sampled dataset-effect pairs. We demonstrate accurate estimation of average treatment effects (ATEs) and conditional average treatment effects (CATEs) with BBCI across several causal inference problems with known identification, including problems with less developed estimators.
Shortcut Learning Through the Lens of Early Training Dynamics
Feb 18, 2023



Deep Neural Networks (DNNs) are prone to learn shortcut patterns that damage the generalization of the DNN during deployment. Shortcut Learning is concerning, particularly when the DNNs are applied to safety-critical domains. This paper aims to better understand shortcut learning through the lens of the learning dynamics of the internal neurons during the training process. More specifically, we make the following observations: (1) While previous works treat shortcuts as synonymous with spurious correlations, we emphasize that not all spurious correlations are shortcuts. We show that shortcuts are only those spurious features that are "easier" than the core features. (2) We build upon this premise and use instance difficulty methods (like Prediction Depth) to quantify "easy" and to identify this behavior during the training phase. (3) We empirically show that shortcut learning can be detected by observing the learning dynamics of the DNN's early layers, irrespective of the network architecture used. In other words, easy features learned by the initial layers of a DNN early during the training are potential shortcuts. We verify our claims on simulated and real medical imaging data and justify the empirical success of our hypothesis by showing the theoretical connections between Prediction Depth and information-theoretic concepts like V-usable information. Lastly, our experiments show the insufficiency of monitoring only accuracy plots during training (as is common in machine learning pipelines), and we highlight the need for monitoring early training dynamics using example difficulty metrics.
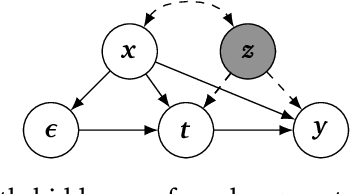
DIET: Conditional independence testing with marginal dependence measures of residual information
Aug 18, 2022

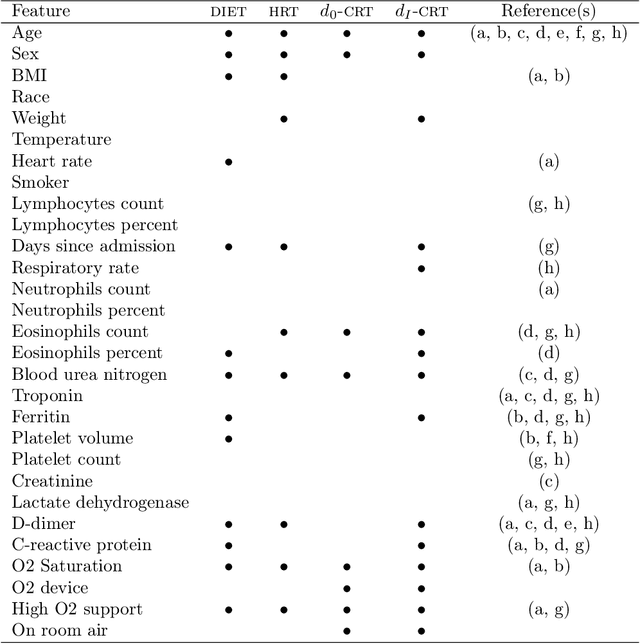
Conditional randomization tests (CRTs) assess whether a variable $x$ is predictive of another variable $y$, having observed covariates $z$. CRTs require fitting a large number of predictive models, which is often computationally intractable. Existing solutions to reduce the cost of CRTs typically split the dataset into a train and test portion, or rely on heuristics for interactions, both of which lead to a loss in power. We propose the decoupled independence test (DIET), an algorithm that avoids both of these issues by leveraging marginal independence statistics to test conditional independence relationships. DIET tests the marginal independence of two random variables: $F(x \mid z)$ and $F(y \mid z)$ where $F(\cdot \mid z)$ is a conditional cumulative distribution function (CDF). These variables are termed "information residuals." We give sufficient conditions for DIET to achieve finite sample type-1 error control and power greater than the type-1 error rate. We then prove that when using the mutual information between the information residuals as a test statistic, DIET yields the most powerful conditionally valid test. Finally, we show DIET achieves higher power than other tractable CRTs on several synthetic and real benchmarks.
Generalized Control Functions via Variational Decoupling
Jul 08, 2019

Causal estimation relies on separating the variation in the outcome due to the confounders from that due to the treatment. To achieve this separation, practitioners can use external sources of randomness that only influence the treatment called instrumental variables (IVs). Traditional IV-methods rely on structural assumptions that limit the effect that the confounders can have on both outcome and treatment. To relax these assumptions we develop a new estimator called the generalized control-function method (GCFN). GCFN's first stage called variational decoupling (VDE) recovers the residual variation in the treatment given the IV. In the second stage, GCFN regresses the outcome on the treatment and residual variation to compute the causal effect. We evaluate GCFN on simulated data and on recovering the causal effect of slave export on community trust. We show how VDE can help unify IV-estimators and non-IV-estimators.
Removing Hidden Confounding by Experimental Grounding
Oct 27, 2018

Observational data is increasingly used as a means for making individual-level causal predictions and intervention recommendations. The foremost challenge of causal inference from observational data is hidden confounding, whose presence cannot be tested in data and can invalidate any causal conclusion. Experimental data does not suffer from confounding but is usually limited in both scope and scale. We introduce a novel method of using limited experimental data to correct the hidden confounding in causal effect models trained on larger observational data, even if the observational data does not fully overlap with the experimental data. Our method makes strictly weaker assumptions than existing approaches, and we prove conditions under which it yields a consistent estimator. We demonstrate our method's efficacy using real-world data from a large educational experiment.