 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentity Management for Agentic AI: The new frontier of authorization, authentication, and security for an AI agent world
Oct 29, 2025The rapid rise of AI agents presents urgent challenges in authentication, authorization, and identity management. Current agent-centric protocols (like MCP) highlight the demand for clarified best practices in authentication and authorization. Looking ahead, ambitions for highly autonomous agents raise complex long-term questions regarding scalable access control, agent-centric identities, AI workload differentiation, and delegated authority. This OpenID Foundation whitepaper is for stakeholders at the intersection of AI agents and access management. It outlines the resources already available for securing today's agents and presents a strategic agenda to address the foundational authentication, authorization, and identity problems pivotal for tomorrow's widespread autonomous systems.
CREDAL: Close Reading of Data Models
Feb 11, 2025



Data models are necessary for the birth of data and of any data-driven system. Indeed, every algorithm, every machine learning model, every statistical model, and every database has an underlying data model without which the system would not be usable. Hence, data models are excellent sites for interrogating the (material, social, political, ...) conditions giving rise to a data system. Towards this, drawing inspiration from literary criticism, we propose to closely read data models in the same spirit as we closely read literary artifacts. Close readings of data models reconnect us with, among other things, the materiality, the genealogies, the techne, the closed nature, and the design of technical systems. While recognizing from literary theory that there is no one correct way to read, it is nonetheless critical to have systematic guidance for those unfamiliar with close readings. This is especially true for those trained in the computing and data sciences, who too often are enculturated to set aside the socio-political aspects of data work. A systematic methodology for reading data models currently does not exist. To fill this gap, we present the CREDAL methodology for close readings of data models. We detail our iterative development process and present results of a qualitative evaluation of CREDAL demonstrating its usability, usefulness, and effectiveness in the critical study of data.
GNN Transformation Framework for Improving Efficiency and Scalability
Jul 25, 2022
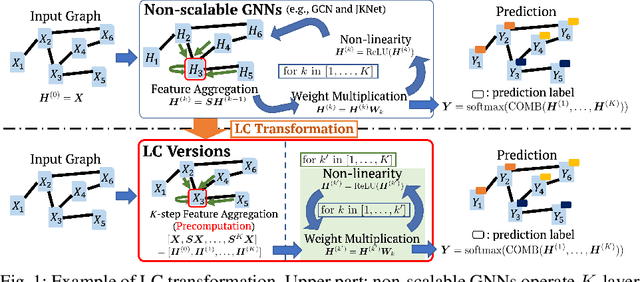
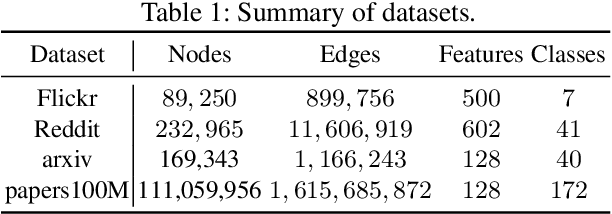
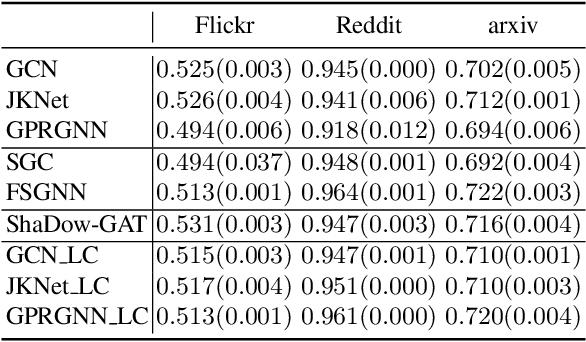
We propose a framework that automatically transforms non-scalable GNNs into precomputation-based GNNs which are efficient and scalable for large-scale graphs. The advantages of our framework are two-fold; 1) it transforms various non-scalable GNNs to scale well to large-scale graphs by separating local feature aggregation from weight learning in their graph convolution, 2) it efficiently executes precomputation on GPU for large-scale graphs by decomposing their edges into small disjoint and balanced sets. Through extensive experiments with large-scale graphs, we demonstrate that the transformed GNNs run faster in training time than existing GNNs while achieving competitive accuracy to the state-of-the-art GNNs. Consequently, our transformation framework provides simple and efficient baselines for future research on scalable GNNs.
Survey on Fair Reinforcement Learning: Theory and Practice
May 20, 2022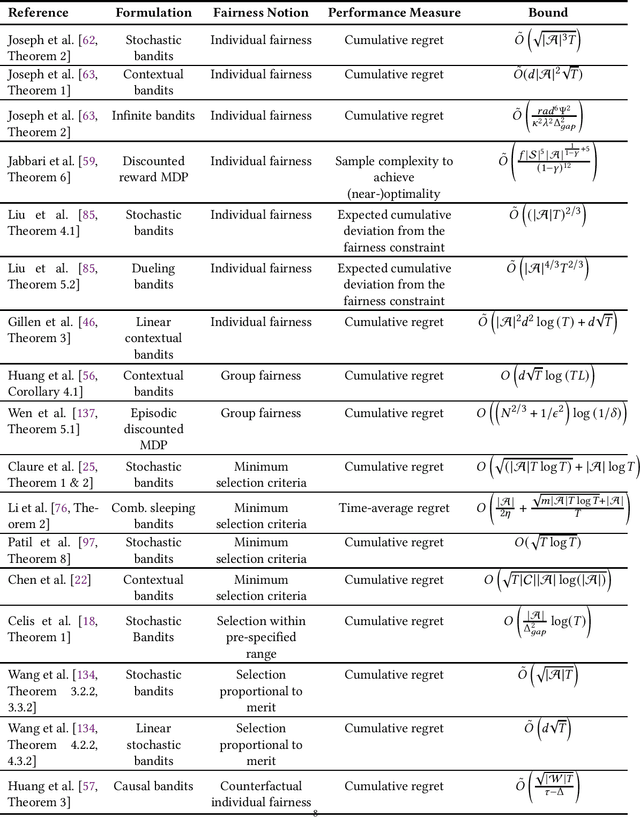
Fairness-aware learning aims at satisfying various fairness constraints in addition to the usual performance criteria via data-driven machine learning techniques. Most of the research in fairness-aware learning employs the setting of fair-supervised learning. However, many dynamic real-world applications can be better modeled using sequential decision-making problems and fair reinforcement learning provides a more suitable alternative for addressing these problems. In this article, we provide an extensive overview of fairness approaches that have been implemented via a reinforcement learning (RL) framework. We discuss various practical applications in which RL methods have been applied to achieve a fair solution with high accuracy. We further include various facets of the theory of fair reinforcement learning, organizing them into single-agent RL, multi-agent RL, long-term fairness via RL, and offline learning. Moreover, we highlight a few major issues to explore in order to advance the field of fair-RL, namely - i) correcting societal biases, ii) feasibility of group fairness or individual fairness, and iii) explainability in RL. Our work is beneficial for both researchers and practitioners as we discuss articles providing mathematical guarantees as well as articles with empirical studies on real-world problems.
Novelty Producing Synaptic Plasticity
Feb 10, 2020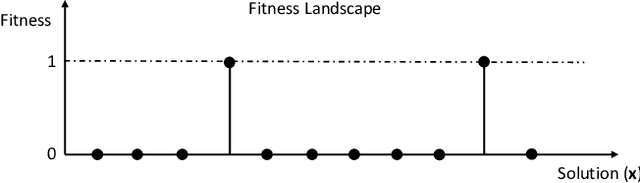

A learning process with the plasticity property often requires reinforcement signals to guide the process. However, in some tasks (e.g. maze-navigation), it is very difficult (or impossible) to measure the performance of an agent (i.e. a fitness value) to provide reinforcements since the position of the goal is not known. This requires finding the correct behavior among a vast number of possible behaviors without having the knowledge of the reinforcement signals. In these cases, an exhaustive search may be needed. However, this might not be feasible especially when optimizing artificial neural networks in continuous domains. In this work, we introduce novelty producing synaptic plasticity (NPSP), where we evolve synaptic plasticity rules to produce as many novel behaviors as possible to find the behavior that can solve the problem. We evaluate the NPSP on maze-navigation on deceptive maze environments that require complex actions and the achievement of subgoals to complete. Our results show that the search heuristic used with the proposed NPSP is indeed capable of producing much more novel behaviors in comparison with a random search taken as baseline.
Evolving Plasticity for Autonomous Learning under Changing Environmental Conditions
Apr 02, 2019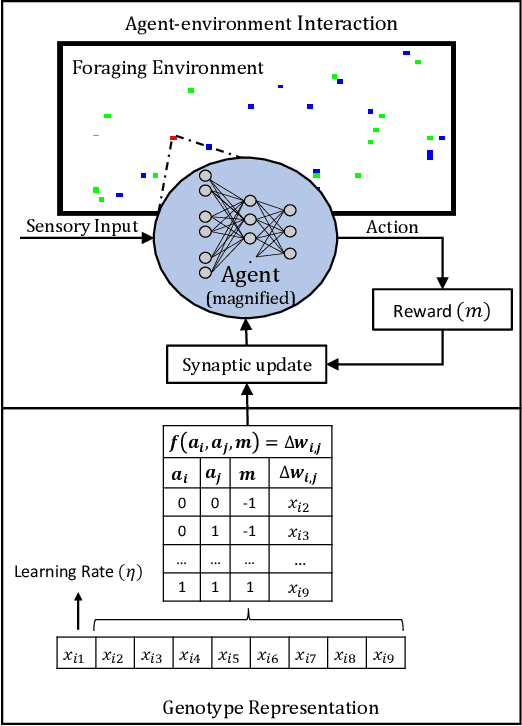
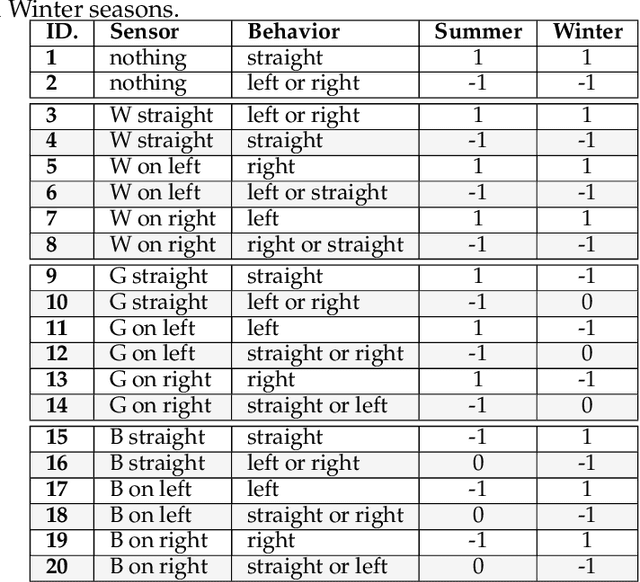
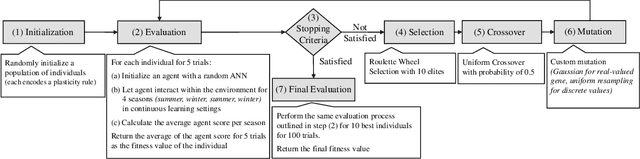
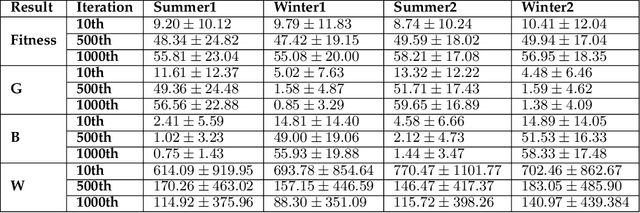
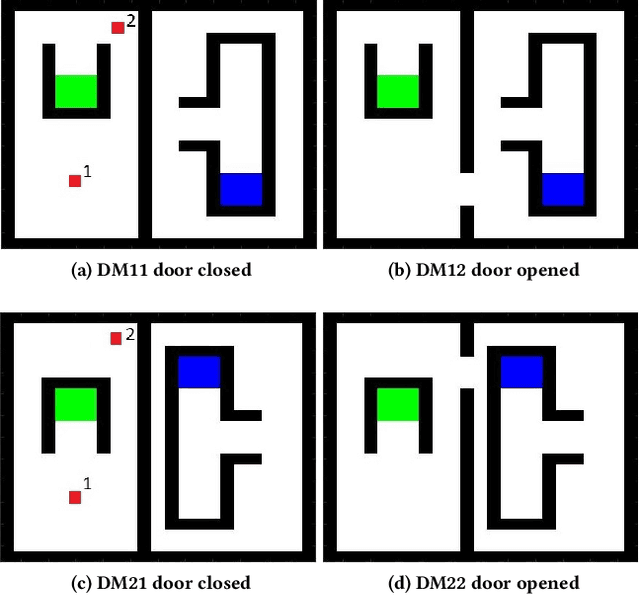
A fundamental aspect of learning in biological neural networks (BNNs) is the plasticity property which allows them to modify their configurations during their lifetime. Hebbian learning is a biologically plausible mechanism for modeling the plasticity property based on the local activation of neurons. In this work, we employ genetic algorithms to evolve local learning rules, from Hebbian perspective, to produce autonomous learning under changing environmental conditions. Our evolved synaptic plasticity rules are capable of performing synaptic updates in distributed and self-organized fashion, based only on the binary activation states of neurons, and a reinforcement signal received from the environment. We demonstrate the learning and adaptation capabilities of the ANNs modified by the evolved plasticity rules on a foraging task in a continuous learning settings. Our results show that evolved plasticity rules are highly efficient at adapting the ANNs to task under changing environmental conditions.
Learning with Delayed Synaptic Plasticity
Mar 22, 2019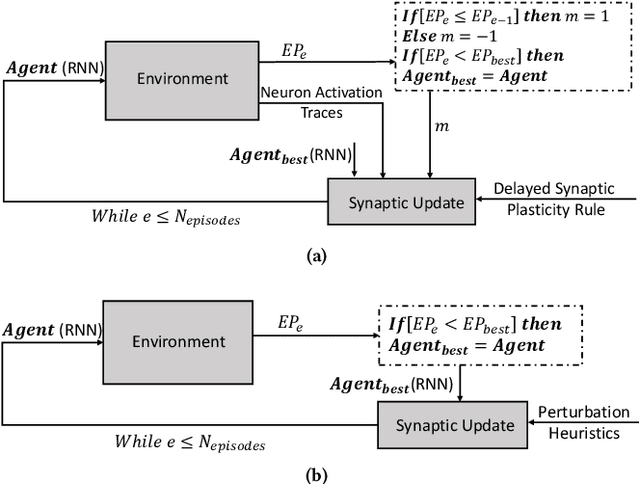
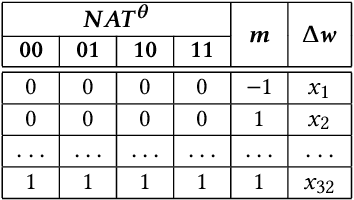
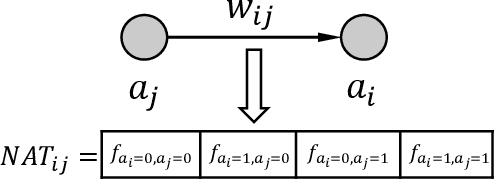

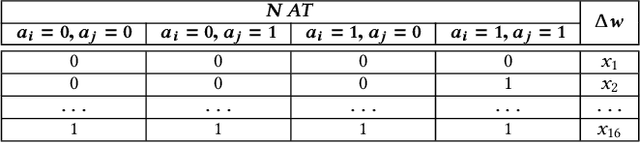
The plasticity property of biological neural networks allows them to perform learning and optimize their behavior by changing their inner configuration. Inspired by biology, plasticity can be modeled in artificial neural networks by using Hebbian learning rules, i.e. rules that update synapses based on the neuron activations and a reinforcement signal received from the environment. However, the distal reward problem arises when the reinforcement signals are not available immediately after each network output to associate the neuron activations that contributed to receiving the reinforcement signal. In this work, we extend Hebbian plasticity rules to allow learning in distal reward cases. We propose the use of neuron activation traces (NATs) to provide additional data storage in each synapse and keep track of the activation of the neurons while the network performs a certain task for an episode. Delayed reinforcement signals are provided after each episode, based on the performance of the network relative to its performance during the previous episode. We employ genetic algorithms to evolve delayed synaptic plasticity (DSP) rules and perform synaptic updates based on NATs and delayed reinforcement signals. We compare DSP with an analogous hill climbing algorithm which does not incorporate domain knowledge introduced with the NATs.
struc2gauss: Structure Preserving Network Embedding via Gaussian Embedding
May 25, 2018
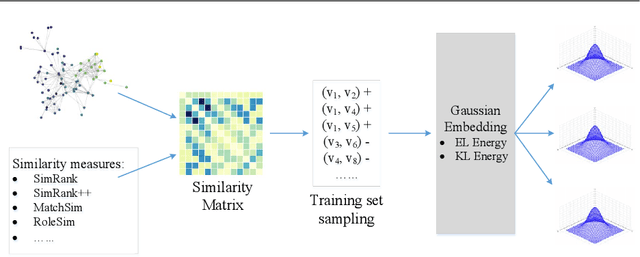
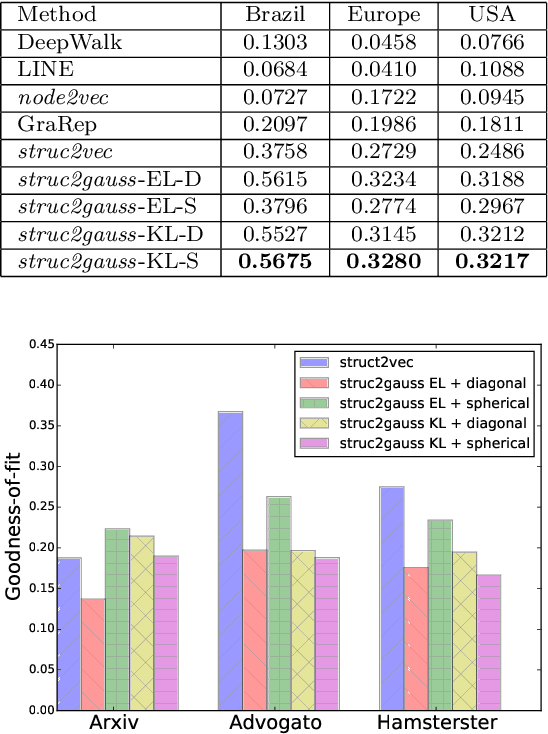
Network embedding (NE) is playing a principal role in network mining, due to its ability to map nodes into efficient low-dimensional embedding vectors. However, two major limitations exist in state-of-the-art NE methods: structure preservation and uncertainty modeling. Almost all previous methods represent a node into a point in space and focus on the local structural information, i.e., neighborhood information. However, neighborhood information does not capture the global structural information and point vector representation fails in modeling the uncertainty of node representations. In this paper, we propose a new NE framework, struc2gauss, which learns node representations in the space of Gaussian distributions and performs network embedding based on global structural information. struc2gauss first employs a given node similarity metric to measure the global structural information, then generates structural context for nodes and finally learns node representations via Gaussian embedding. Different structural similarity measures of networks and energy functions of Gaussian embedding are investigated. Experiments conducted on both synthetic and real-world data sets demonstrate that struc2gauss effectively captures the global structural information while state-of-the-art network embedding methods fails to, outperforms other methods on the structure-based clustering task and provides more information on uncertainties of node representations.
Limited Evaluation Cooperative Co-evolutionary Differential Evolution for Large-scale Neuroevolution
May 06, 2018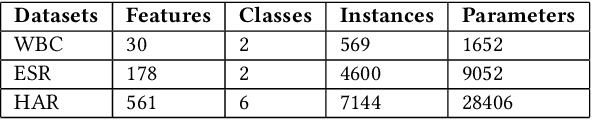
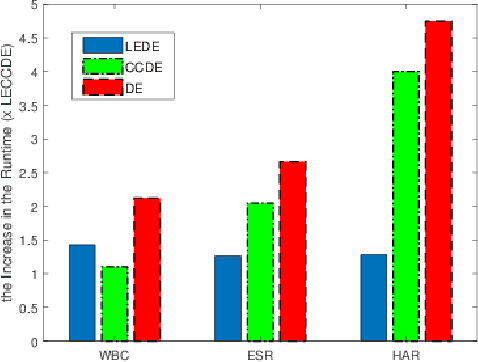
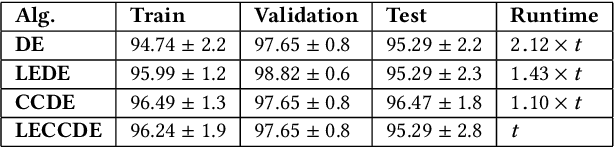
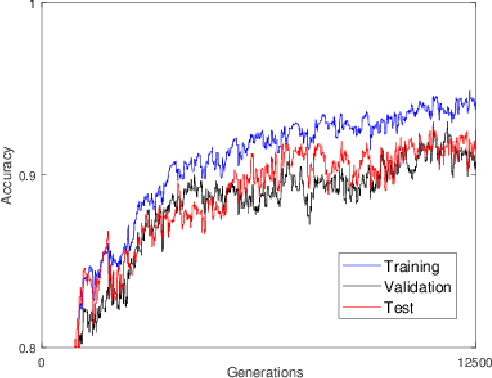
Many real-world control and classification tasks involve a large number of features. When artificial neural networks (ANNs) are used for modeling these tasks, the network architectures tend to be large. Neuroevolution is an effective approach for optimizing ANNs; however, there are two bottlenecks that make their application challenging in case of high-dimensional networks using direct encoding. First, classic evolutionary algorithms tend not to scale well for searching large parameter spaces; second, the network evaluation over a large number of training instances is in general time-consuming. In this work, we propose an approach called the Limited Evaluation Cooperative Co-evolutionary Differential Evolution algorithm (LECCDE) to optimize high-dimensional ANNs. The proposed method aims to optimize the pre-synaptic weights of each post-synaptic neuron in different subpopulations using a Cooperative Co-evolutionary Differential Evolution algorithm, and employs a limited evaluation scheme where fitness evaluation is performed on a relatively small number of training instances based on fitness inheritance. We test LECCDE on three datasets with various sizes, and our results show that cooperative co-evolution significantly improves the test error comparing to standard Differential Evolution, while the limited evaluation scheme facilitates a significant reduction in computing time.