 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Robust Uncertainty Estimation with Random Activation Functions
Feb 28, 2023Deep neural networks are in the limelight of machine learning with their excellent performance in many data-driven applications. However, they can lead to inaccurate predictions when queried in out-of-distribution data points, which can have detrimental effects especially in sensitive domains, such as healthcare and transportation, where erroneous predictions can be very costly and/or dangerous. Subsequently, quantifying the uncertainty of the output of a neural network is often leveraged to evaluate the confidence of its predictions, and ensemble models have proved to be effective in measuring the uncertainty by utilizing the variance of predictions over a pool of models. In this paper, we propose a novel approach for uncertainty quantification via ensembles, called Random Activation Functions (RAFs) Ensemble, that aims at improving the ensemble diversity toward a more robust estimation, by accommodating each neural network with a different (random) activation function. Extensive empirical study demonstrates that RAFs Ensemble outperforms state-of-the-art ensemble uncertainty quantification methods on both synthetic and real-world datasets in a series of regression tasks.
Survey on Fair Reinforcement Learning: Theory and Practice
May 20, 2022
Fairness-aware learning aims at satisfying various fairness constraints in addition to the usual performance criteria via data-driven machine learning techniques. Most of the research in fairness-aware learning employs the setting of fair-supervised learning. However, many dynamic real-world applications can be better modeled using sequential decision-making problems and fair reinforcement learning provides a more suitable alternative for addressing these problems. In this article, we provide an extensive overview of fairness approaches that have been implemented via a reinforcement learning (RL) framework. We discuss various practical applications in which RL methods have been applied to achieve a fair solution with high accuracy. We further include various facets of the theory of fair reinforcement learning, organizing them into single-agent RL, multi-agent RL, long-term fairness via RL, and offline learning. Moreover, we highlight a few major issues to explore in order to advance the field of fair-RL, namely - i) correcting societal biases, ii) feasibility of group fairness or individual fairness, and iii) explainability in RL. Our work is beneficial for both researchers and practitioners as we discuss articles providing mathematical guarantees as well as articles with empirical studies on real-world problems.
MDP-based Shallow Parsing in Distantly Supervised QA Systems
Sep 27, 2019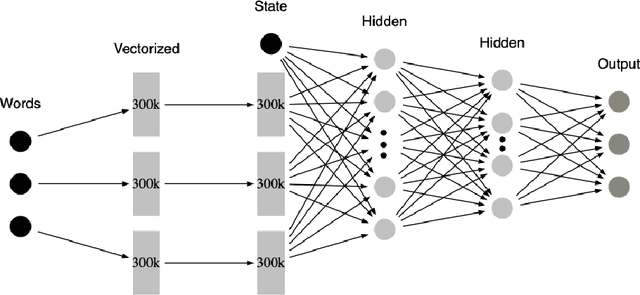

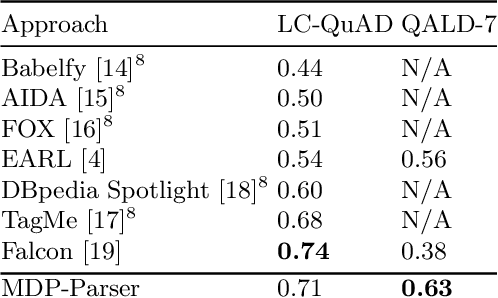
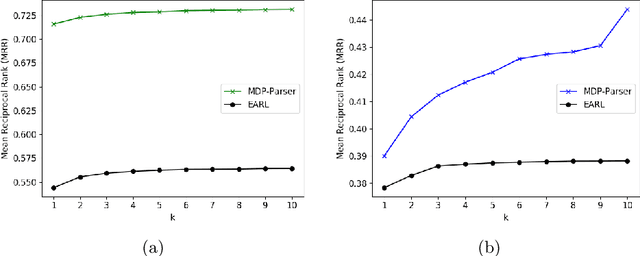
Question answering systems over knowledge graphs commonly consist of multiple components such as shallow parser, entity/relation linker, query generation and answer retrieval. We focus on the first task, shallow parsing, which so far received little attention in the QA community. Despite the lack of gold annotations for shallow parsing in question answering datasets, we devise a Reinforcement Learning based model called MDP-Parser, and show that it outperforms the current state-of-the-art approaches. Furthermore, it can be easily embedded into the existing entity/relation linking tools to boost the overall accuracy.