 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBest-of-Both-Worlds Multi-Dueling Bandits: Unified Algorithms for Stochastic and Adversarial Preferences under Condorcet and Borda Objectives
Mar 19, 2026Multi-dueling bandits, where a learner selects $m \geq 2$ arms per round and observes only the winner, arise naturally in many applications including ranking and recommendation systems, yet a fundamental question has remained open: can a single algorithm perform optimally in both stochastic and adversarial environments, without knowing which regime it faces? We answer this affirmatively, providing the first best-of-both-worlds algorithms for multi-dueling bandits under both Condorcet and Borda objectives. For the Condorcet setting, we propose \texttt{MetaDueling}, a black-box reduction that converts any dueling bandit algorithm into a multi-dueling bandit algorithm by transforming multi-way winner feedback into an unbiased pairwise signal. Instantiating our reduction with \texttt{Versatile-DB} yields the first best-of-both-worlds algorithm for multi-dueling bandits: it achieves $O(\sqrt{KT})$ pseudo-regret against adversarial preferences and the instance-optimal $O\!\left(\sum_{i \neq a^\star} \frac{\log T}{Δ_i}\right)$ pseudo-regret under stochastic preferences, both simultaneously and without prior knowledge of the regime. For the Borda setting, we propose \AlgBorda, a stochastic-and-adversarial algorithm that achieves $O\left(K^2 \log KT + K \log^2 T + \sum_{i: Δ_i^{\mathrm{B}} > 0} \frac{K\log KT}{(Δ_i^{\mathrm{B}})^2}\right)$ regret in stochastic environments and $O\left(K \sqrt{T \log KT} + K^{1/3} T^{2/3} (\log K)^{1/3}\right)$ regret against adversaries, again without prior knowledge of the regime. We complement our upper bounds with matching lower bounds for the Condorcet setting. For the Borda setting, our upper bounds are near-optimal with respect to the lower bounds (within a factor of $K$) and match the best-known results in the literature.
Evaluating Causal Discovery Algorithms for Path-Specific Fairness and Utility in Healthcare
Mar 16, 2026Causal discovery in health data faces evaluation challenges when ground truth is unknown. We address this by collaborating with experts to construct proxy ground-truth graphs, establishing benchmarks for synthetic Alzheimer's disease and heart failure clinical records data. We evaluate the Peter-Clark, Greedy Equivalence Search, and Fast Causal Inference algorithms on structural recovery and path-specific fairness decomposition, going beyond composite fairness scores. On synthetic data, Peter-Clark achieved the best structural recovery. On heart failure data, Fast Causal Inference achieved the highest utility. For path-specific effects, ejection fraction contributed 3.37 percentage points to the indirect effect in the ground truth. These differences drove variations in the fairness-utility ratio across algorithms. Our results highlight the need for graph-aware fairness evaluation and fine-grained path-specific analysis when deploying causal discovery in clinical applications.
Adversarial Multi-dueling Bandits
Jun 18, 2024We introduce the problem of regret minimization in adversarial multi-dueling bandits. While adversarial preferences have been studied in dueling bandits, they have not been explored in multi-dueling bandits. In this setting, the learner is required to select $m \geq 2$ arms at each round and observes as feedback the identity of the most preferred arm which is based on an arbitrary preference matrix chosen obliviously. We introduce a novel algorithm, MiDEX (Multi Dueling EXP3), to learn from such preference feedback that is assumed to be generated from a pairwise-subset choice model. We prove that the expected cumulative $T$-round regret of MiDEX compared to a Borda-winner from a set of $K$ arms is upper bounded by $O((K \log K)^{1/3} T^{2/3})$. Moreover, we prove a lower bound of $\Omega(K^{1/3} T^{2/3})$ for the expected regret in this setting which demonstrates that our proposed algorithm is near-optimal.
Investigating Gender Fairness in Machine Learning-driven Personalized Care for Chronic Pain
Feb 29, 2024This study investigates gender fairness in personalized pain care recommendations using machine learning algorithms. Leveraging a contextual bandits framework, personalized recommendations are formulated and evaluated using LinUCB algorithm on a dataset comprising interactions with $164$ patients across $10$ sessions each. Results indicate that while adjustments to algorithm parameters influence the quality of pain care recommendations, this impact remains consistent across genders. However, when certain patient information, such as self-reported pain measurements, is absent, the quality of pain care recommendations for women is notably inferior to that for men.
Provably Efficient Exploration in Constrained Reinforcement Learning:Posterior Sampling Is All You Need
Sep 27, 2023We present a new algorithm based on posterior sampling for learning in constrained Markov decision processes (CMDP) in the infinite-horizon undiscounted setting. The algorithm achieves near-optimal regret bounds while being advantageous empirically compared to the existing algorithms. Our main theoretical result is a Bayesian regret bound for each cost component of \tilde{O} (HS \sqrt{AT}) for any communicating CMDP with S states, A actions, and bound on the hitting time H. This regret bound matches the lower bound in order of time horizon T and is the best-known regret bound for communicating CMDPs in the infinite-horizon undiscounted setting. Empirical results show that, despite its simplicity, our posterior sampling algorithm outperforms the existing algorithms for constrained reinforcement learning.
Multi-Armed Bandits with Generalized Temporally-Partitioned Rewards
Mar 01, 2023

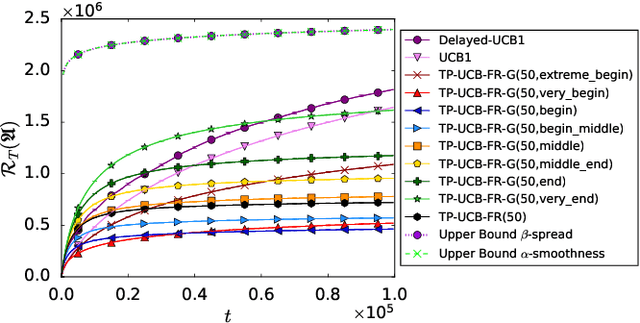

Decision-making problems of sequential nature, where decisions made in the past may have an impact on the future, are used to model many practically important applications. In some real-world applications, feedback about a decision is delayed and may arrive via partial rewards that are observed with different delays. Motivated by such scenarios, we propose a novel problem formulation called multi-armed bandits with generalized temporally-partitioned rewards. To formalize how feedback about a decision is partitioned across several time steps, we introduce $\beta$-spread property. We derive a lower bound on the performance of any uniformly efficient algorithm for the considered problem. Moreover, we provide an algorithm called TP-UCB-FR-G and prove an upper bound on its performance measure. In some scenarios, our upper bound improves upon the state of the art. We provide experimental results validating the proposed algorithm and our theoretical results.
Curiosity-driven Exploration in Sparse-reward Multi-agent Reinforcement Learning
Feb 21, 2023Sparsity of rewards while applying a deep reinforcement learning method negatively affects its sample-efficiency. A viable solution to deal with the sparsity of rewards is to learn via intrinsic motivation which advocates for adding an intrinsic reward to the reward function to encourage the agent to explore the environment and expand the sample space. Though intrinsic motivation methods are widely used to improve data-efficient learning in the reinforcement learning model, they also suffer from the so-called detachment problem. In this article, we discuss the limitations of intrinsic curiosity module in sparse-reward multi-agent reinforcement learning and propose a method called I-Go-Explore that combines the intrinsic curiosity module with the Go-Explore framework to alleviate the detachment problem.
Local Differential Privacy for Sequential Decision Making in a Changing Environment
Jan 02, 2023We study the problem of preserving privacy while still providing high utility in sequential decision making scenarios in a changing environment. We consider abruptly changing environment: the environment remains constant during periods and it changes at unknown time instants. To formulate this problem, we propose a variant of multi-armed bandits called non-stationary stochastic corrupt bandits. We construct an algorithm called SW-KLUCB-CF and prove an upper bound on its utility using the performance measure of regret. The proven regret upper bound for SW-KLUCB-CF is near-optimal in the number of time steps and matches the best known bound for analogous problems in terms of the number of time steps and the number of changes. Moreover, we present a provably optimal mechanism which can guarantee the desired level of local differential privacy while providing high utility.
Generalizing distribution of partial rewards for multi-armed bandits with temporally-partitioned rewards
Nov 13, 2022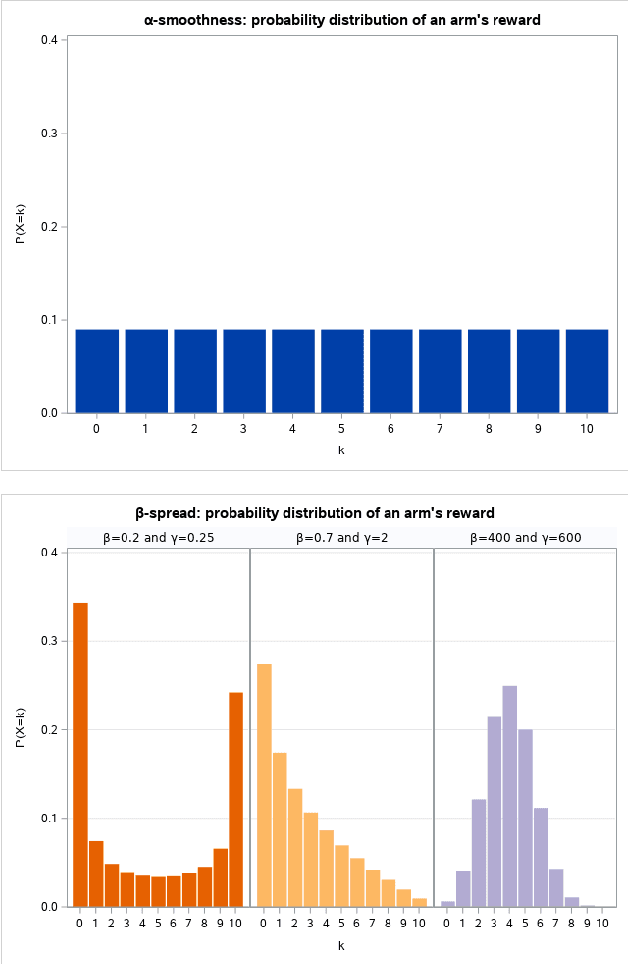
We investigate the Multi-Armed Bandit problem with Temporally-Partitioned Rewards (TP-MAB) setting in this paper. In the TP-MAB setting, an agent will receive subsets of the reward over multiple rounds rather than the entire reward for the arm all at once. In this paper, we introduce a general formulation of how an arm's cumulative reward is distributed across several rounds, called Beta-spread property. Such a generalization is needed to be able to handle partitioned rewards in which the maximum reward per round is not distributed uniformly across rounds. We derive a lower bound on the TP-MAB problem under the assumption that Beta-spread holds. Moreover, we provide an algorithm TP-UCB-FR-G, which uses the Beta-spread property to improve the regret upper bound in some scenarios. By generalizing how the cumulative reward is distributed, this setting is applicable in a broader range of applications.
An Empirical Evaluation of Posterior Sampling for Constrained Reinforcement Learning
Sep 08, 2022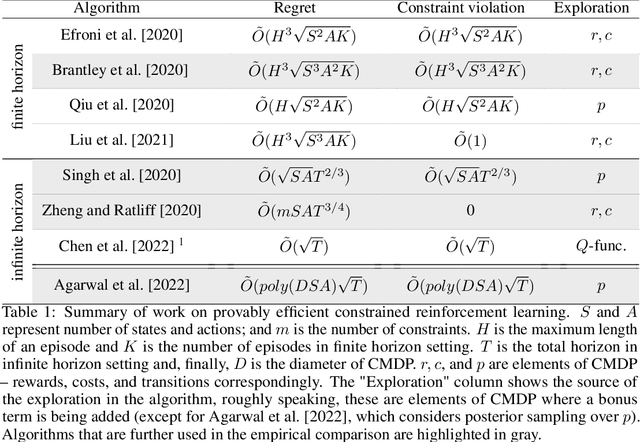
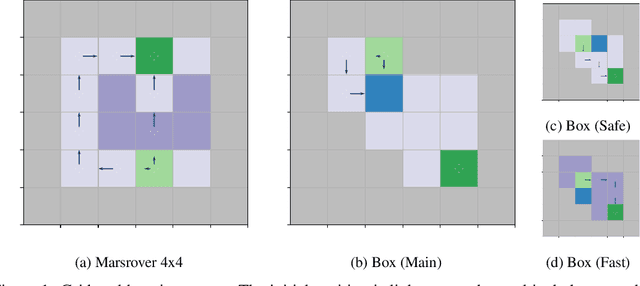
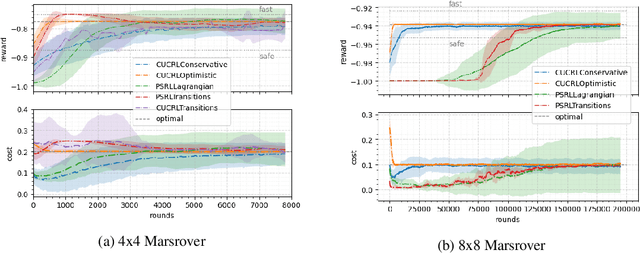
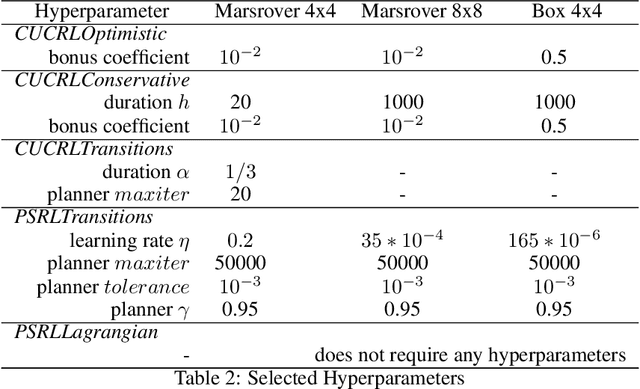
We study a posterior sampling approach to efficient exploration in constrained reinforcement learning. Alternatively to existing algorithms, we propose two simple algorithms that are more efficient statistically, simpler to implement and computationally cheaper. The first algorithm is based on a linear formulation of CMDP, and the second algorithm leverages the saddle-point formulation of CMDP. Our empirical results demonstrate that, despite its simplicity, posterior sampling achieves state-of-the-art performance and, in some cases, significantly outperforms optimistic algorithms.