 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Data Is Scarce: Scaling Sparse Language Models with Repeated Training
May 31, 2026Scaling laws for dense LLMs under infinite data are well explored, but how sparsity interacts with limited data is not. In this work, we study sparse training in data-constrained regimes where limited unique tokens require multi-epoch training. Our experiments span models up to 1.92B parameters in the fitting set, sparsity up to 93.75%, unique data budgets up to 2.6B tokens, and total training tokens up to 41.6B over 16 epochs; we further validate extrapolation on held-out dense-equivalent models up to 7.68B parameters. We find that: 1. Sparse scaling in data-limited settings: We introduce a scaling law that models loss as a function of active parameters, unique tokens, data repetition, and sparsity, accurately predicting performance across compute and data budgets. 2. Delayed data saturation: sparse training postpones diminishing returns from repeated data, making multi-epoch training more effective. 3. Resource trade-offs: With fixed data, loss-optimal sparsity is moderate ~ 50%, while compute-optimal sparsity is higher and grows with data scale. Overall, sparsity is not just a tool for efficiency, but a mechanism for improving scaling trade-offs under data scarcity. Our code is available at: https://github.com/boqian333/sparse-dc-scaling.
Memory-Efficient LLM Training with Dynamic Sparsity: From Stability to Practical Scaling
May 30, 2026Dynamic Sparse Training (DST) offers a promising paradigm for improving the training and inference efficiency of deep neural networks; however, we find that in large language model training, DST can suffer from optimization instability, manifested as loss spikes after topology updates. In this work, we show that the naive use of standard Adam-based optimizers leads to a cold-start issue for newly regrown parameters, resulting in excessively large updates and disrupted training dynamics. To address this issue, we propose Sparse Memory-Efficient Training (SMET), which stabilizes DST with optimizer warm-up and improves training progress through density-aware learning-rate scaling. SMET further reduces memory consumption by storing gradients and optimizer states only for active parameters. We provide a theoretical analysis of the update behaviors under SMET, showing improved optimization stability. Extensive experiments demonstrate that SMET enables stable, scalable, and memory-efficient sparse pre-training of LLMs, paving the way for sparse training as a practical alternative to dense training. Our code is publicly available at: https://github.com/QiaoXiao7282/SMET.
Batch Matrix-form Equations and Implementation of Multilayer Perceptrons
Nov 14, 2025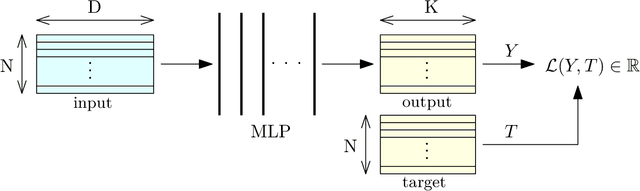

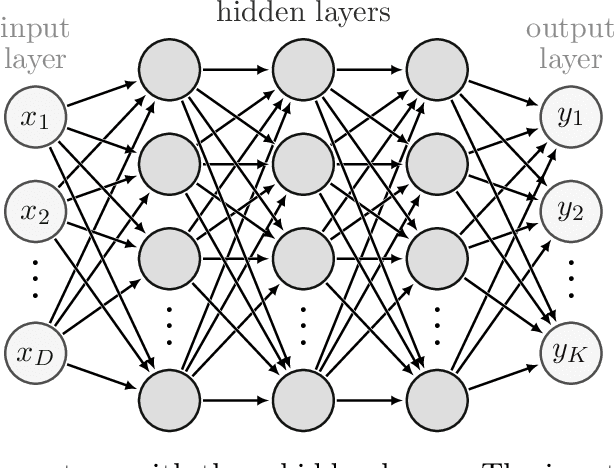
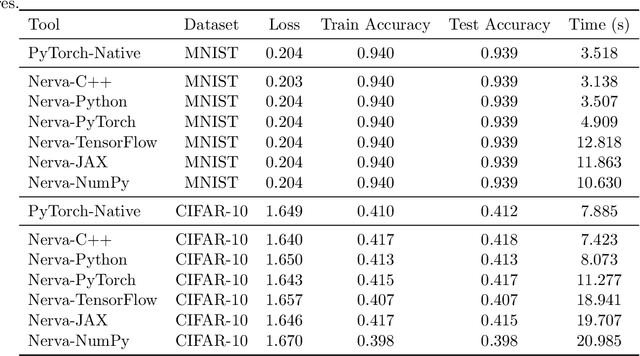
Multilayer perceptrons (MLPs) remain fundamental to modern deep learning, yet their algorithmic details are rarely presented in complete, explicit \emph{batch matrix-form}. Rather, most references express gradients per sample or rely on automatic differentiation. Although automatic differentiation can achieve equally high computational efficiency, the usage of batch matrix-form makes the computational structure explicit, which is essential for transparent, systematic analysis, and optimization in settings such as sparse neural networks. This paper fills that gap by providing a mathematically rigorous and implementation-ready specification of MLPs in batch matrix-form. We derive forward and backward equations for all standard and advanced layers, including batch normalization and softmax, and validate all equations using the symbolic mathematics library SymPy. From these specifications, we construct uniform reference implementations in NumPy, PyTorch, JAX, TensorFlow, and a high-performance C++ backend optimized for sparse operations. Our main contributions are: (1) a complete derivation of batch matrix-form backpropagation for MLPs, (2) symbolic validation of all gradient equations, (3) uniform Python and C++ reference implementations grounded in a small set of matrix primitives, and (4) demonstration of how explicit formulations enable efficient sparse computation. Together, these results establish a validated, extensible foundation for understanding, teaching, and researching neural network algorithms.
Leave it to the Specialist: Repair Sparse LLMs with Sparse Fine-Tuning via Sparsity Evolution
May 29, 2025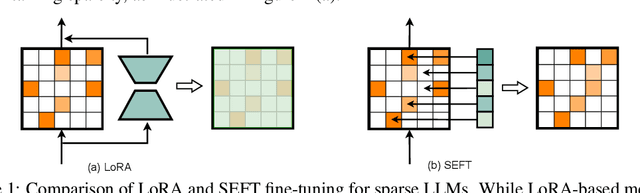
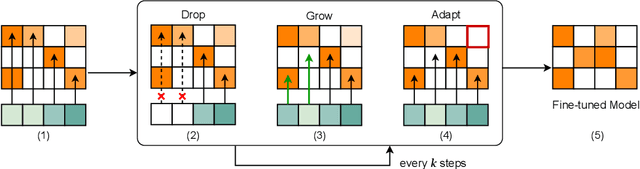
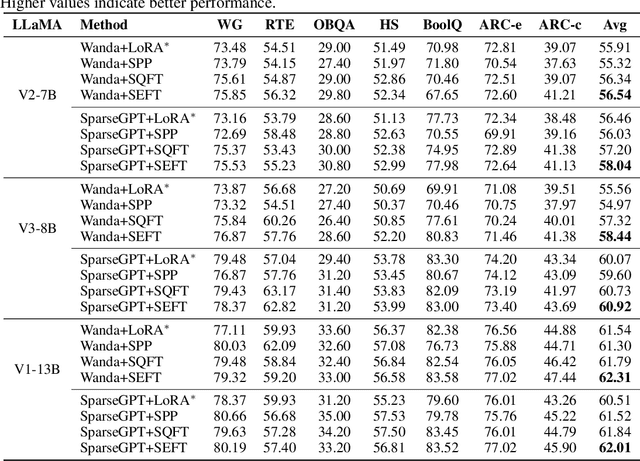
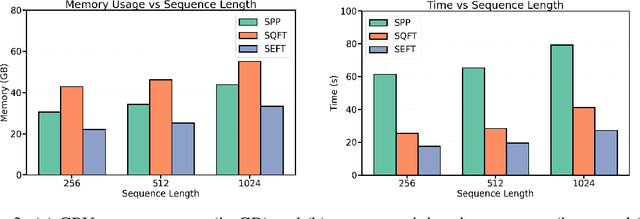
Large language models (LLMs) have achieved remarkable success across various tasks but face deployment challenges due to their massive computational demands. While post-training pruning methods like SparseGPT and Wanda can effectively reduce the model size, but struggle to maintain model performance at high sparsity levels, limiting their utility for downstream tasks. Existing fine-tuning methods, such as full fine-tuning and LoRA, fail to preserve sparsity as they require updating the whole dense metrics, not well-suited for sparse LLMs. In this paper, we propose Sparsity Evolution Fine-Tuning (SEFT), a novel method designed specifically for sparse LLMs. SEFT dynamically evolves the sparse topology of pruned models during fine-tuning, while preserving the overall sparsity throughout the process. The strengths of SEFT lie in its ability to perform task-specific adaptation through a weight drop-and-grow strategy, enabling the pruned model to self-adapt its sparse connectivity pattern based on the target dataset. Furthermore, a sensitivity-driven pruning criterion is employed to ensure that the desired sparsity level is consistently maintained throughout fine-tuning. Our experiments on various LLMs, including LLaMA families, DeepSeek, and Mistral, across a diverse set of benchmarks demonstrate that SEFT achieves stronger performance while offering superior memory and time efficiency compared to existing baselines. Our code is publicly available at: https://github.com/QiaoXiao7282/SEFT.
NeuroTrails: Training with Dynamic Sparse Heads as the Key to Effective Ensembling
May 23, 2025Model ensembles have long been a cornerstone for improving generalization and robustness in deep learning. However, their effectiveness often comes at the cost of substantial computational overhead. To address this issue, state-of-the-art methods aim to replicate ensemble-class performance without requiring multiple independently trained networks. Unfortunately, these algorithms often still demand considerable compute at inference. In response to these limitations, we introduce $\textbf{NeuroTrails}$, a sparse multi-head architecture with dynamically evolving topology. This unexplored model-agnostic training paradigm improves ensemble performance while reducing the required resources. We analyze the underlying reason for its effectiveness and observe that the various neural trails induced by dynamic sparsity attain a $\textit{Goldilocks zone}$ of prediction diversity. NeuroTrails displays efficacy with convolutional and transformer-based architectures on computer vision and language tasks. Experiments on ResNet-50/ImageNet, LLaMA-350M/C4, among many others, demonstrate increased accuracy and stronger robustness in zero-shot generalization, while requiring significantly fewer parameters.
Sparse-to-Sparse Training of Diffusion Models
Apr 30, 2025Diffusion models (DMs) are a powerful type of generative models that have achieved state-of-the-art results in various image synthesis tasks and have shown potential in other domains, such as natural language processing and temporal data modeling. Despite their stable training dynamics and ability to produce diverse high-quality samples, DMs are notorious for requiring significant computational resources, both in the training and inference stages. Previous work has focused mostly on increasing the efficiency of model inference. This paper introduces, for the first time, the paradigm of sparse-to-sparse training to DMs, with the aim of improving both training and inference efficiency. We focus on unconditional generation and train sparse DMs from scratch (Latent Diffusion and ChiroDiff) on six datasets using three different methods (Static-DM, RigL-DM, and MagRan-DM) to study the effect of sparsity in model performance. Our experiments show that sparse DMs are able to match and often outperform their Dense counterparts, while substantially reducing the number of trainable parameters and FLOPs. We also identify safe and effective values to perform sparse-to-sparse training of DMs.
LiMTR: Time Series Motion Prediction for Diverse Road Users through Multimodal Feature Integration
Oct 21, 2024Predicting the behavior of road users accurately is crucial to enable the safe operation of autonomous vehicles in urban or densely populated areas. Therefore, there has been a growing interest in time series motion prediction research, leading to significant advancements in state-of-the-art techniques in recent years. However, the potential of using LiDAR data to capture more detailed local features, such as a person's gaze or posture, remains largely unexplored. To address this, we develop a novel multimodal approach for motion prediction based on the PointNet foundation model architecture, incorporating local LiDAR features. Evaluation on the Waymo Open Dataset shows a performance improvement of 6.20% and 1.58% in minADE and mAP respectively, when integrated and compared with the previous state-of-the-art MTR. We open-source the code of our LiMTR model.
Dynamic Sparse Training versus Dense Training: The Unexpected Winner in Image Corruption Robustness
Oct 03, 2024
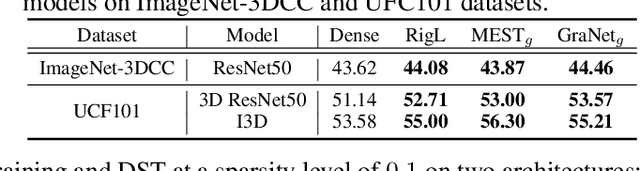
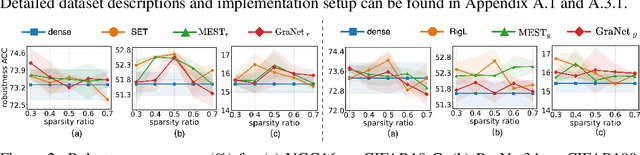

It is generally perceived that Dynamic Sparse Training opens the door to a new era of scalability and efficiency for artificial neural networks at, perhaps, some costs in accuracy performance for the classification task. At the same time, Dense Training is widely accepted as being the "de facto" approach to train artificial neural networks if one would like to maximize their robustness against image corruption. In this paper, we question this general practice. Consequently, we claim that, contrary to what is commonly thought, the Dynamic Sparse Training methods can consistently outperform Dense Training in terms of robustness accuracy, particularly if the efficiency aspect is not considered as a main objective (i.e., sparsity levels between 10% and up to 50%), without adding (or even reducing) resource cost. We validate our claim on two types of data, images and videos, using several traditional and modern deep learning architectures for computer vision and three widely studied Dynamic Sparse Training algorithms. Our findings reveal a new yet-unknown benefit of Dynamic Sparse Training and open new possibilities in improving deep learning robustness beyond the current state of the art.
Are Sparse Neural Networks Better Hard Sample Learners?
Sep 13, 2024



While deep learning has demonstrated impressive progress, it remains a daunting challenge to learn from hard samples as these samples are usually noisy and intricate. These hard samples play a crucial role in the optimal performance of deep neural networks. Most research on Sparse Neural Networks (SNNs) has focused on standard training data, leaving gaps in understanding their effectiveness on complex and challenging data. This paper's extensive investigation across scenarios reveals that most SNNs trained on challenging samples can often match or surpass dense models in accuracy at certain sparsity levels, especially with limited data. We observe that layer-wise density ratios tend to play an important role in SNN performance, particularly for methods that train from scratch without pre-trained initialization. These insights enhance our understanding of SNNs' behavior and potential for efficient learning approaches in data-centric AI. Our code is publicly available at: \url{https://github.com/QiaoXiao7282/hard_sample_learners}.
Unveiling the Power of Sparse Neural Networks for Feature Selection
Aug 08, 2024



Sparse Neural Networks (SNNs) have emerged as powerful tools for efficient feature selection. Leveraging the dynamic sparse training (DST) algorithms within SNNs has demonstrated promising feature selection capabilities while drastically reducing computational overheads. Despite these advancements, several critical aspects remain insufficiently explored for feature selection. Questions persist regarding the choice of the DST algorithm for network training, the choice of metric for ranking features/neurons, and the comparative performance of these methods across diverse datasets when compared to dense networks. This paper addresses these gaps by presenting a comprehensive systematic analysis of feature selection with sparse neural networks. Moreover, we introduce a novel metric considering sparse neural network characteristics, which is designed to quantify feature importance within the context of SNNs. Our findings show that feature selection with SNNs trained with DST algorithms can achieve, on average, more than $50\%$ memory and $55\%$ FLOPs reduction compared to the dense networks, while outperforming them in terms of the quality of the selected features. Our code and the supplementary material are available on GitHub (\url{https://github.com/zahraatashgahi/Neuron-Attribution}).