 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Data Pruning for Automatic Speech Recognition
Paper and Code
Jun 26, 2024
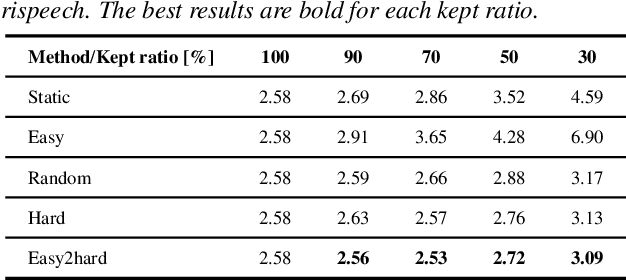
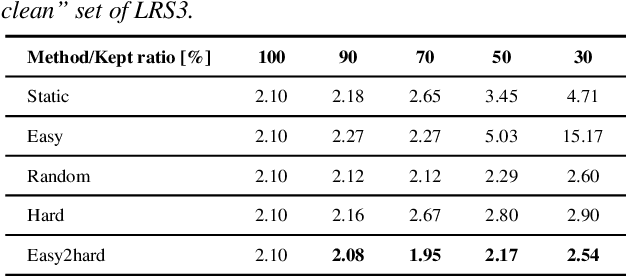
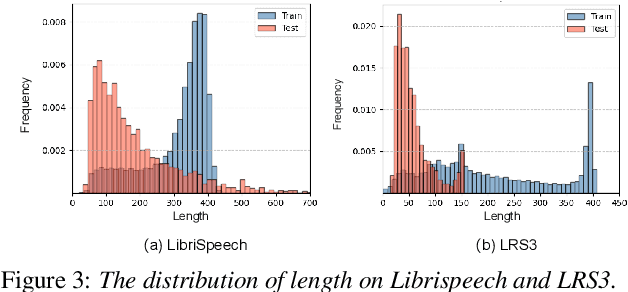
The recent success of Automatic Speech Recognition (ASR) is largely attributed to the ever-growing amount of training data. However, this trend has made model training prohibitively costly and imposed computational demands. While data pruning has been proposed to mitigate this issue by identifying a small subset of relevant data, its application in ASR has been barely explored, and existing works often entail significant overhead to achieve meaningful results. To fill this gap, this paper presents the first investigation of dynamic data pruning for ASR, finding that we can reach the full-data performance by dynamically selecting 70% of data. Furthermore, we introduce Dynamic Data Pruning for ASR (DDP-ASR), which offers several fine-grained pruning granularities specifically tailored for speech-related datasets, going beyond the conventional pruning of entire time sequences. Our intensive experiments show that DDP-ASR can save up to 1.6x training time with negligible performance loss.