 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBatch Matrix-form Equations and Implementation of Multilayer Perceptrons
Nov 14, 2025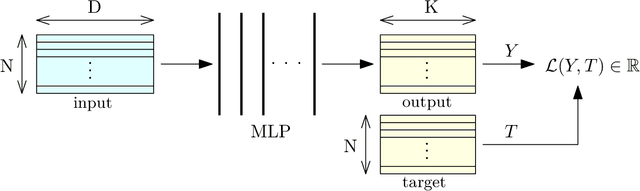

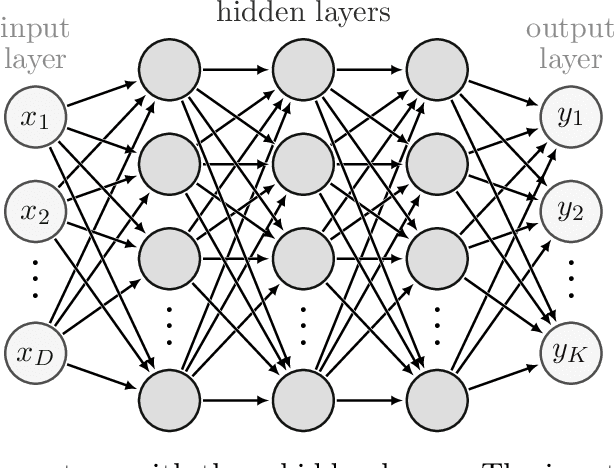
Multilayer perceptrons (MLPs) remain fundamental to modern deep learning, yet their algorithmic details are rarely presented in complete, explicit \emph{batch matrix-form}. Rather, most references express gradients per sample or rely on automatic differentiation. Although automatic differentiation can achieve equally high computational efficiency, the usage of batch matrix-form makes the computational structure explicit, which is essential for transparent, systematic analysis, and optimization in settings such as sparse neural networks. This paper fills that gap by providing a mathematically rigorous and implementation-ready specification of MLPs in batch matrix-form. We derive forward and backward equations for all standard and advanced layers, including batch normalization and softmax, and validate all equations using the symbolic mathematics library SymPy. From these specifications, we construct uniform reference implementations in NumPy, PyTorch, JAX, TensorFlow, and a high-performance C++ backend optimized for sparse operations. Our main contributions are: (1) a complete derivation of batch matrix-form backpropagation for MLPs, (2) symbolic validation of all gradient equations, (3) uniform Python and C++ reference implementations grounded in a small set of matrix primitives, and (4) demonstration of how explicit formulations enable efficient sparse computation. Together, these results establish a validated, extensible foundation for understanding, teaching, and researching neural network algorithms.
Out-of-Distribution Generalization with a SPARC: Racing 100 Unseen Vehicles with a Single Policy
Nov 12, 2025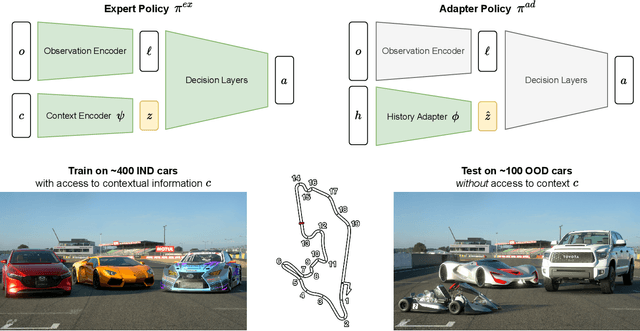
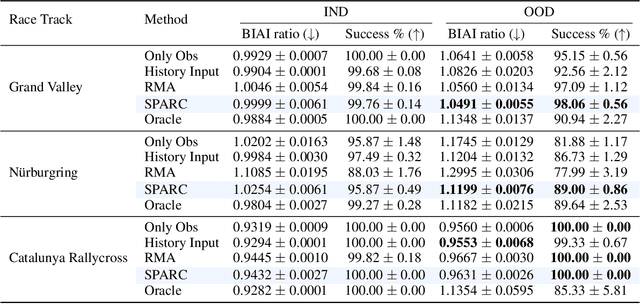
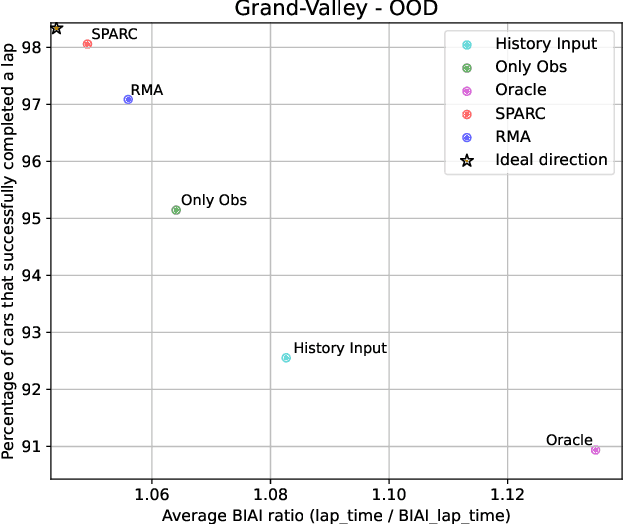
Generalization to unseen environments is a significant challenge in the field of robotics and control. In this work, we focus on contextual reinforcement learning, where agents act within environments with varying contexts, such as self-driving cars or quadrupedal robots that need to operate in different terrains or weather conditions than they were trained for. We tackle the critical task of generalizing to out-of-distribution (OOD) settings, without access to explicit context information at test time. Recent work has addressed this problem by training a context encoder and a history adaptation module in separate stages. While promising, this two-phase approach is cumbersome to implement and train. We simplify the methodology and introduce SPARC: single-phase adaptation for robust control. We test SPARC on varying contexts within the high-fidelity racing simulator Gran Turismo 7 and wind-perturbed MuJoCo environments, and find that it achieves reliable and robust OOD generalization.
MEAL: A Benchmark for Continual Multi-Agent Reinforcement Learning
Jun 17, 2025Benchmarks play a crucial role in the development and analysis of reinforcement learning (RL) algorithms, with environment availability strongly impacting research. One particularly underexplored intersection is continual learning (CL) in cooperative multi-agent settings. To remedy this, we introduce MEAL (Multi-agent Environments for Adaptive Learning), the first benchmark tailored for continual multi-agent reinforcement learning (CMARL). Existing CL benchmarks run environments on the CPU, leading to computational bottlenecks and limiting the length of task sequences. MEAL leverages JAX for GPU acceleration, enabling continual learning across sequences of 100 tasks on a standard desktop PC in a few hours. We show that naively combining popular CL and MARL methods yields strong performance on simple environments, but fails to scale to more complex settings requiring sustained coordination and adaptation. Our ablation study identifies architectural and algorithmic features critical for CMARL on MEAL.
NeuroTrails: Training with Dynamic Sparse Heads as the Key to Effective Ensembling
May 23, 2025Model ensembles have long been a cornerstone for improving generalization and robustness in deep learning. However, their effectiveness often comes at the cost of substantial computational overhead. To address this issue, state-of-the-art methods aim to replicate ensemble-class performance without requiring multiple independently trained networks. Unfortunately, these algorithms often still demand considerable compute at inference. In response to these limitations, we introduce $\textbf{NeuroTrails}$, a sparse multi-head architecture with dynamically evolving topology. This unexplored model-agnostic training paradigm improves ensemble performance while reducing the required resources. We analyze the underlying reason for its effectiveness and observe that the various neural trails induced by dynamic sparsity attain a $\textit{Goldilocks zone}$ of prediction diversity. NeuroTrails displays efficacy with convolutional and transformer-based architectures on computer vision and language tasks. Experiments on ResNet-50/ImageNet, LLaMA-350M/C4, among many others, demonstrate increased accuracy and stronger robustness in zero-shot generalization, while requiring significantly fewer parameters.
LiMTR: Time Series Motion Prediction for Diverse Road Users through Multimodal Feature Integration
Oct 21, 2024Predicting the behavior of road users accurately is crucial to enable the safe operation of autonomous vehicles in urban or densely populated areas. Therefore, there has been a growing interest in time series motion prediction research, leading to significant advancements in state-of-the-art techniques in recent years. However, the potential of using LiDAR data to capture more detailed local features, such as a person's gaze or posture, remains largely unexplored. To address this, we develop a novel multimodal approach for motion prediction based on the PointNet foundation model architecture, incorporating local LiDAR features. Evaluation on the Waymo Open Dataset shows a performance improvement of 6.20% and 1.58% in minADE and mAP respectively, when integrated and compared with the previous state-of-the-art MTR. We open-source the code of our LiMTR model.
Nerva: a Truly Sparse Implementation of Neural Networks
Jul 24, 2024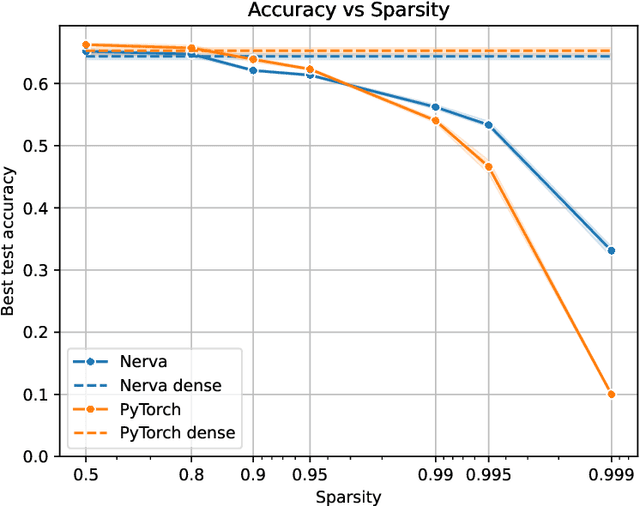

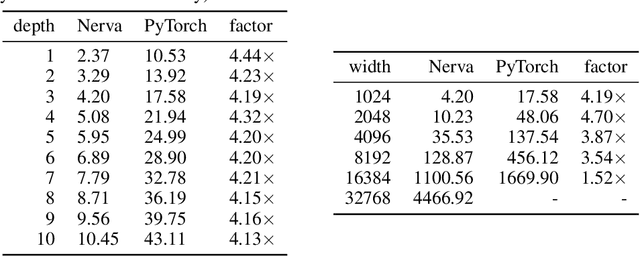

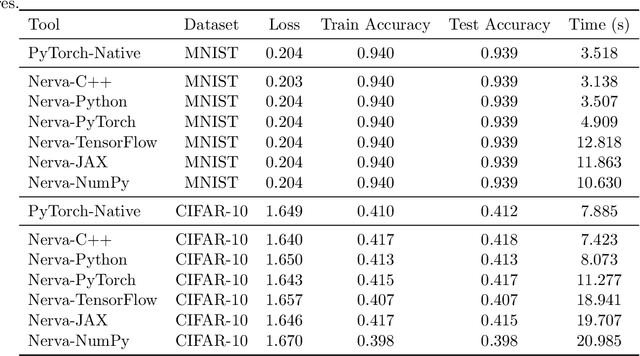
We introduce Nerva, a fast neural network library under development in C++. It supports sparsity by using the sparse matrix operations of Intel's Math Kernel Library (MKL), which eliminates the need for binary masks. We show that Nerva significantly decreases training time and memory usage while reaching equivalent accuracy to PyTorch. We run static sparse experiments with an MLP on CIFAR-10. On high sparsity levels like $99\%$, the runtime is reduced by a factor of $4\times$ compared to a PyTorch model using masks. Similar to other popular frameworks such as PyTorch and Keras, Nerva offers a Python interface for users to work with.
Boosting Robustness in Preference-Based Reinforcement Learning with Dynamic Sparsity
Jun 10, 2024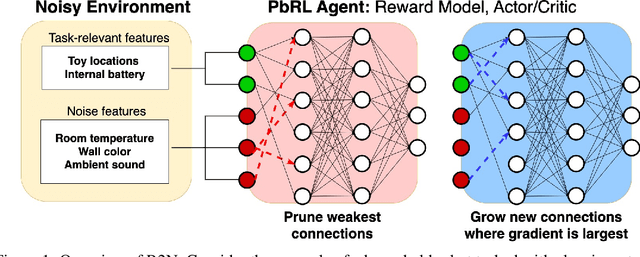
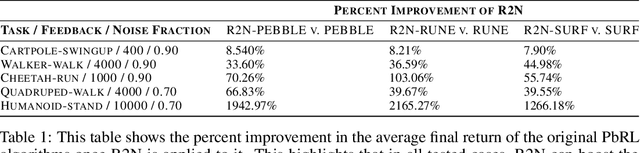
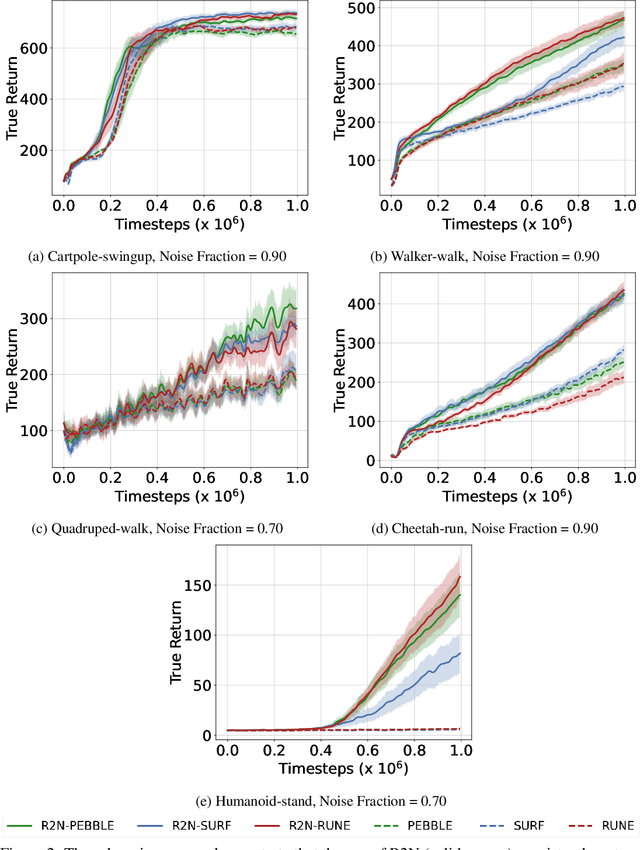
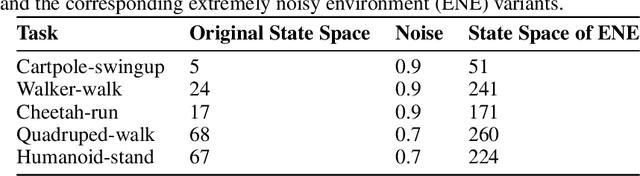
For autonomous agents to successfully integrate into human-centered environments, agents should be able to learn from and adapt to humans in their native settings. Preference-based reinforcement learning (PbRL) is a promising approach that learns reward functions from human preferences. This enables RL agents to adapt their behavior based on human desires. However, humans live in a world full of diverse information, most of which is not relevant to completing a particular task. It becomes essential that agents learn to focus on the subset of task-relevant environment features. Unfortunately, prior work has largely ignored this aspect; primarily focusing on improving PbRL algorithms in standard RL environments that are carefully constructed to contain only task-relevant features. This can result in algorithms that may not effectively transfer to a more noisy real-world setting. To that end, this work proposes R2N (Robust-to-Noise), the first PbRL algorithm that leverages principles of dynamic sparse training to learn robust reward models that can focus on task-relevant features. We study the effectiveness of R2N in the Extremely Noisy Environment setting, an RL problem setting where up to 95% of the state features are irrelevant distractions. In experiments with a simulated teacher, we demonstrate that R2N can adapt the sparse connectivity of its neural networks to focus on task-relevant features, enabling R2N to significantly outperform several state-of-the-art PbRL algorithms in multiple locomotion and control environments.
MaDi: Learning to Mask Distractions for Generalization in Visual Deep Reinforcement Learning
Dec 23, 2023



The visual world provides an abundance of information, but many input pixels received by agents often contain distracting stimuli. Autonomous agents need the ability to distinguish useful information from task-irrelevant perceptions, enabling them to generalize to unseen environments with new distractions. Existing works approach this problem using data augmentation or large auxiliary networks with additional loss functions. We introduce MaDi, a novel algorithm that learns to mask distractions by the reward signal only. In MaDi, the conventional actor-critic structure of deep reinforcement learning agents is complemented by a small third sibling, the Masker. This lightweight neural network generates a mask to determine what the actor and critic will receive, such that they can focus on learning the task. The masks are created dynamically, depending on the current input. We run experiments on the DeepMind Control Generalization Benchmark, the Distracting Control Suite, and a real UR5 Robotic Arm. Our algorithm improves the agent's focus with useful masks, while its efficient Masker network only adds 0.2% more parameters to the original structure, in contrast to previous work. MaDi consistently achieves generalization results better than or competitive to state-of-the-art methods.
Fantastic Weights and How to Find Them: Where to Prune in Dynamic Sparse Training
Jun 21, 2023



Dynamic Sparse Training (DST) is a rapidly evolving area of research that seeks to optimize the sparse initialization of a neural network by adapting its topology during training. It has been shown that under specific conditions, DST is able to outperform dense models. The key components of this framework are the pruning and growing criteria, which are repeatedly applied during the training process to adjust the network's sparse connectivity. While the growing criterion's impact on DST performance is relatively well studied, the influence of the pruning criterion remains overlooked. To address this issue, we design and perform an extensive empirical analysis of various pruning criteria to better understand their effect on the dynamics of DST solutions. Surprisingly, we find that most of the studied methods yield similar results. The differences become more significant in the low-density regime, where the best performance is predominantly given by the simplest technique: magnitude-based pruning. The code is provided at https://github.com/alooow/fantastic_weights_paper
Automatic Noise Filtering with Dynamic Sparse Training in Deep Reinforcement Learning
Feb 13, 2023Tomorrow's robots will need to distinguish useful information from noise when performing different tasks. A household robot for instance may continuously receive a plethora of information about the home, but needs to focus on just a small subset to successfully execute its current chore. Filtering distracting inputs that contain irrelevant data has received little attention in the reinforcement learning literature. To start resolving this, we formulate a problem setting in reinforcement learning called the $\textit{extremely noisy environment}$ (ENE), where up to $99\%$ of the input features are pure noise. Agents need to detect which features provide task-relevant information about the state of the environment. Consequently, we propose a new method termed $\textit{Automatic Noise Filtering}$ (ANF), which uses the principles of dynamic sparse training in synergy with various deep reinforcement learning algorithms. The sparse input layer learns to focus its connectivity on task-relevant features, such that ANF-SAC and ANF-TD3 outperform standard SAC and TD3 by a large margin, while using up to $95\%$ fewer weights. Furthermore, we devise a transfer learning setting for ENEs, by permuting all features of the environment after 1M timesteps to simulate the fact that other information sources can become relevant as the world evolves. Again, ANF surpasses the baselines in final performance and sample complexity. Our code is available at https://github.com/bramgrooten/automatic-noise-filtering