Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNerva: a Truly Sparse Implementation of Neural Networks
Paper and Code
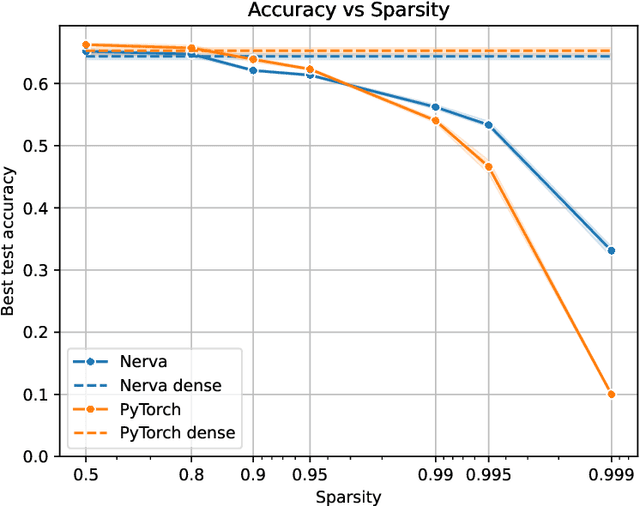

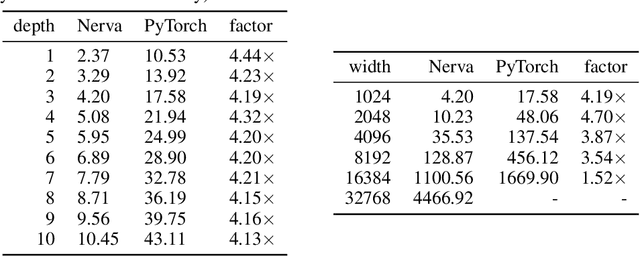

We introduce Nerva, a fast neural network library under development in C++. It supports sparsity by using the sparse matrix operations of Intel's Math Kernel Library (MKL), which eliminates the need for binary masks. We show that Nerva significantly decreases training time and memory usage while reaching equivalent accuracy to PyTorch. We run static sparse experiments with an MLP on CIFAR-10. On high sparsity levels like $99\%$, the runtime is reduced by a factor of $4\times$ compared to a PyTorch model using masks. Similar to other popular frameworks such as PyTorch and Keras, Nerva offers a Python interface for users to work with.
* The Nerva library is available at https://github.com/wiegerw/nerva
View paper on