 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBatch Matrix-form Equations and Implementation of Multilayer Perceptrons
Nov 14, 2025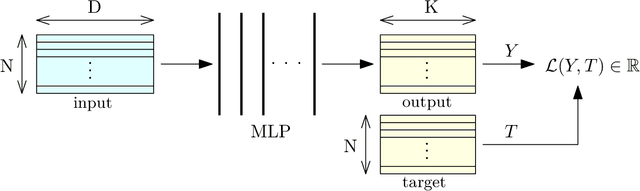

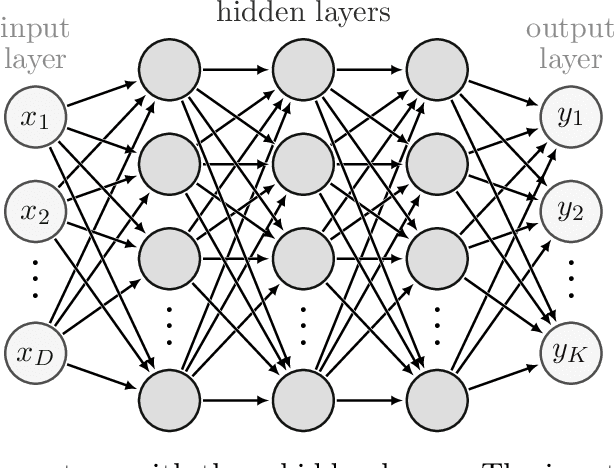
Multilayer perceptrons (MLPs) remain fundamental to modern deep learning, yet their algorithmic details are rarely presented in complete, explicit \emph{batch matrix-form}. Rather, most references express gradients per sample or rely on automatic differentiation. Although automatic differentiation can achieve equally high computational efficiency, the usage of batch matrix-form makes the computational structure explicit, which is essential for transparent, systematic analysis, and optimization in settings such as sparse neural networks. This paper fills that gap by providing a mathematically rigorous and implementation-ready specification of MLPs in batch matrix-form. We derive forward and backward equations for all standard and advanced layers, including batch normalization and softmax, and validate all equations using the symbolic mathematics library SymPy. From these specifications, we construct uniform reference implementations in NumPy, PyTorch, JAX, TensorFlow, and a high-performance C++ backend optimized for sparse operations. Our main contributions are: (1) a complete derivation of batch matrix-form backpropagation for MLPs, (2) symbolic validation of all gradient equations, (3) uniform Python and C++ reference implementations grounded in a small set of matrix primitives, and (4) demonstration of how explicit formulations enable efficient sparse computation. Together, these results establish a validated, extensible foundation for understanding, teaching, and researching neural network algorithms.
Nerva: a Truly Sparse Implementation of Neural Networks
Jul 24, 2024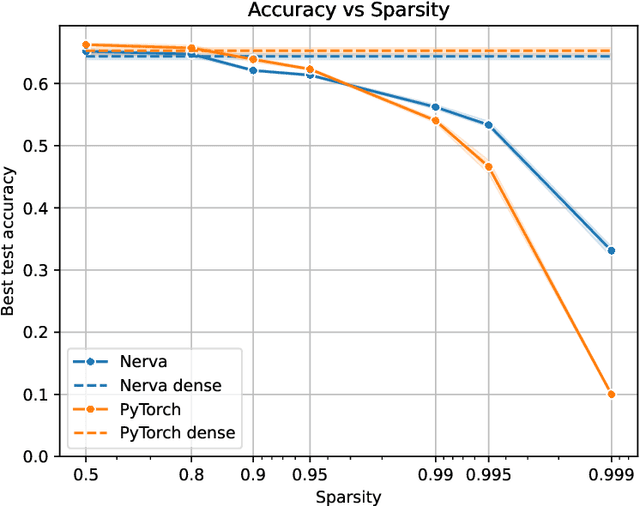

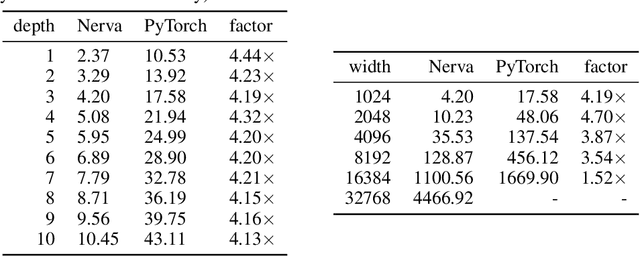

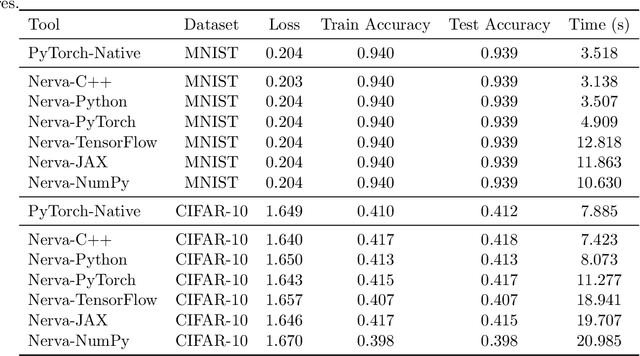
We introduce Nerva, a fast neural network library under development in C++. It supports sparsity by using the sparse matrix operations of Intel's Math Kernel Library (MKL), which eliminates the need for binary masks. We show that Nerva significantly decreases training time and memory usage while reaching equivalent accuracy to PyTorch. We run static sparse experiments with an MLP on CIFAR-10. On high sparsity levels like $99\%$, the runtime is reduced by a factor of $4\times$ compared to a PyTorch model using masks. Similar to other popular frameworks such as PyTorch and Keras, Nerva offers a Python interface for users to work with.