 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Robustness in Preference-Based Reinforcement Learning with Dynamic Sparsity
Paper and Code
Jun 10, 2024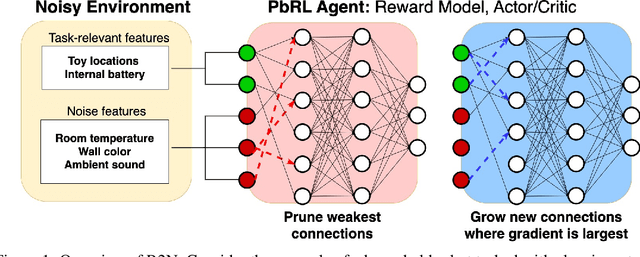
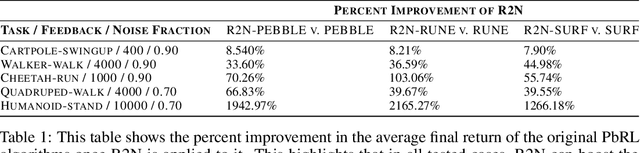
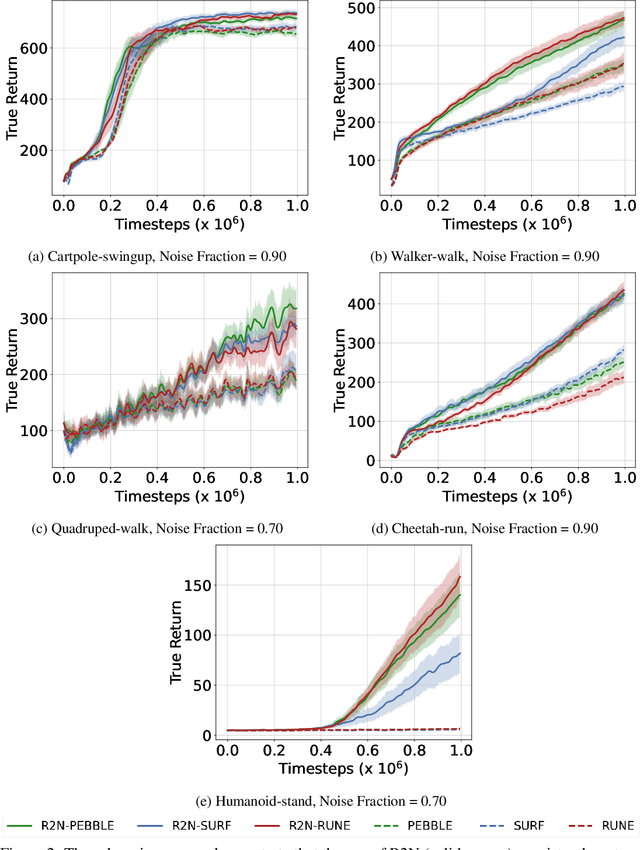
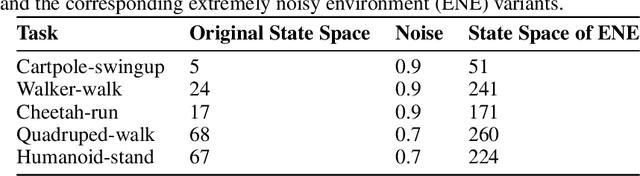
For autonomous agents to successfully integrate into human-centered environments, agents should be able to learn from and adapt to humans in their native settings. Preference-based reinforcement learning (PbRL) is a promising approach that learns reward functions from human preferences. This enables RL agents to adapt their behavior based on human desires. However, humans live in a world full of diverse information, most of which is not relevant to completing a particular task. It becomes essential that agents learn to focus on the subset of task-relevant environment features. Unfortunately, prior work has largely ignored this aspect; primarily focusing on improving PbRL algorithms in standard RL environments that are carefully constructed to contain only task-relevant features. This can result in algorithms that may not effectively transfer to a more noisy real-world setting. To that end, this work proposes R2N (Robust-to-Noise), the first PbRL algorithm that leverages principles of dynamic sparse training to learn robust reward models that can focus on task-relevant features. We study the effectiveness of R2N in the Extremely Noisy Environment setting, an RL problem setting where up to 95% of the state features are irrelevant distractions. In experiments with a simulated teacher, we demonstrate that R2N can adapt the sparse connectivity of its neural networks to focus on task-relevant features, enabling R2N to significantly outperform several state-of-the-art PbRL algorithms in multiple locomotion and control environments.