 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeave it to the Specialist: Repair Sparse LLMs with Sparse Fine-Tuning via Sparsity Evolution
May 29, 2025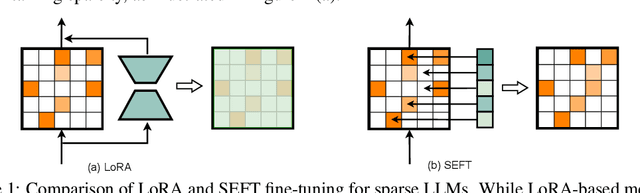
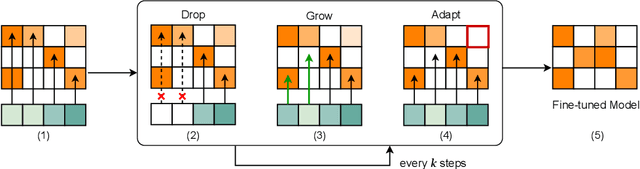
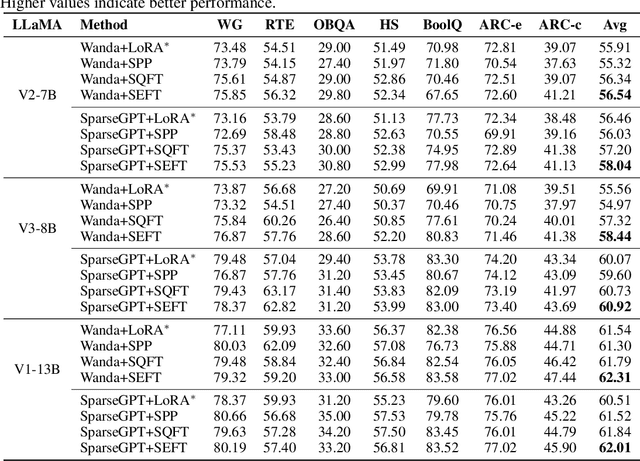
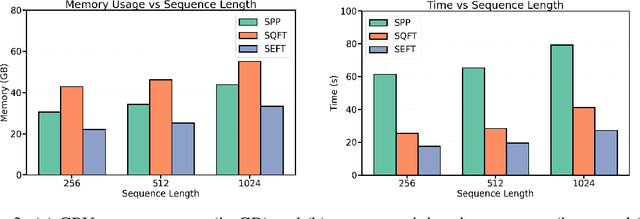
Large language models (LLMs) have achieved remarkable success across various tasks but face deployment challenges due to their massive computational demands. While post-training pruning methods like SparseGPT and Wanda can effectively reduce the model size, but struggle to maintain model performance at high sparsity levels, limiting their utility for downstream tasks. Existing fine-tuning methods, such as full fine-tuning and LoRA, fail to preserve sparsity as they require updating the whole dense metrics, not well-suited for sparse LLMs. In this paper, we propose Sparsity Evolution Fine-Tuning (SEFT), a novel method designed specifically for sparse LLMs. SEFT dynamically evolves the sparse topology of pruned models during fine-tuning, while preserving the overall sparsity throughout the process. The strengths of SEFT lie in its ability to perform task-specific adaptation through a weight drop-and-grow strategy, enabling the pruned model to self-adapt its sparse connectivity pattern based on the target dataset. Furthermore, a sensitivity-driven pruning criterion is employed to ensure that the desired sparsity level is consistently maintained throughout fine-tuning. Our experiments on various LLMs, including LLaMA families, DeepSeek, and Mistral, across a diverse set of benchmarks demonstrate that SEFT achieves stronger performance while offering superior memory and time efficiency compared to existing baselines. Our code is publicly available at: https://github.com/QiaoXiao7282/SEFT.
Training Plug-n-Play Knowledge Modules with Deep Context Distillation
Mar 11, 2025Dynamically integrating new or rapidly evolving information after (Large) Language Model pre-training remains challenging, particularly in low-data scenarios or when dealing with private and specialized documents. In-context learning and retrieval-augmented generation (RAG) face limitations, including their high inference costs and their inability to capture global document information. In this paper, we propose a way of modularizing knowledge by training document-level Knowledge Modules (KMs). KMs are lightweight components implemented as parameter-efficient LoRA modules, which are trained to store information about new documents and can be easily plugged into models on demand. We show that next-token prediction performs poorly as the training objective for KMs. We instead propose Deep Context Distillation: we learn KMs parameters such as to simulate hidden states and logits of a teacher that takes the document in context. Our method outperforms standard next-token prediction and pre-instruction training techniques, across two datasets. Finally, we highlight synergies between KMs and retrieval-augmented generation.
Scaling Sparse Fine-Tuning to Large Language Models
Feb 02, 2024Large Language Models (LLMs) are difficult to fully fine-tune (e.g., with instructions or human feedback) due to their sheer number of parameters. A family of parameter-efficient sparse fine-tuning methods have proven promising in terms of performance but their memory requirements increase proportionally to the size of the LLMs. In this work, we scale sparse fine-tuning to state-of-the-art LLMs like LLaMA 2 7B and 13B. We propose SpIEL, a novel sparse fine-tuning method which, for a desired density level, maintains an array of parameter indices and the deltas of these parameters relative to their pretrained values. It iterates over: (a) updating the active deltas, (b) pruning indices (based on the change of magnitude of their deltas) and (c) regrowth of indices. For regrowth, we explore two criteria based on either the accumulated gradients of a few candidate parameters or their approximate momenta estimated using the efficient SM3 optimizer. We experiment with instruction-tuning of LLMs on standard dataset mixtures, finding that SpIEL is often superior to popular parameter-efficient fine-tuning methods like LoRA (low-rank adaptation) in terms of performance and comparable in terms of run time. We additionally show that SpIEL is compatible with both quantization and efficient optimizers, to facilitate scaling to ever-larger model sizes. We release the code for SpIEL at https://github.com/AlanAnsell/peft and for the instruction-tuning experiments at https://github.com/ducdauge/sft-llm.
Cross-Lingual Transfer with Target Language-Ready Task Adapters
Jun 05, 2023Adapters have emerged as a modular and parameter-efficient approach to (zero-shot) cross-lingual transfer. The established MAD-X framework employs separate language and task adapters which can be arbitrarily combined to perform the transfer of any task to any target language. Subsequently, BAD-X, an extension of the MAD-X framework, achieves improved transfer at the cost of MAD-X's modularity by creating "bilingual" adapters specific to the source-target language pair. In this work, we aim to take the best of both worlds by (i) fine-tuning task adapters adapted to the target language(s) (so-called "target language-ready" (TLR) adapters) to maintain high transfer performance, but (ii) without sacrificing the highly modular design of MAD-X. The main idea of "target language-ready" adapters is to resolve the training-vs-inference discrepancy of MAD-X: the task adapter "sees" the target language adapter for the very first time during inference, and thus might not be fully compatible with it. We address this mismatch by exposing the task adapter to the target language adapter during training, and empirically validate several variants of the idea: in the simplest form, we alternate between using the source and target language adapters during task adapter training, which can be generalized to cycling over any set of language adapters. We evaluate different TLR-based transfer configurations with varying degrees of generality across a suite of standard cross-lingual benchmarks, and find that the most general (and thus most modular) configuration consistently outperforms MAD-X and BAD-X on most tasks and languages.
Distilling Efficient Language-Specific Models for Cross-Lingual Transfer
Jun 02, 2023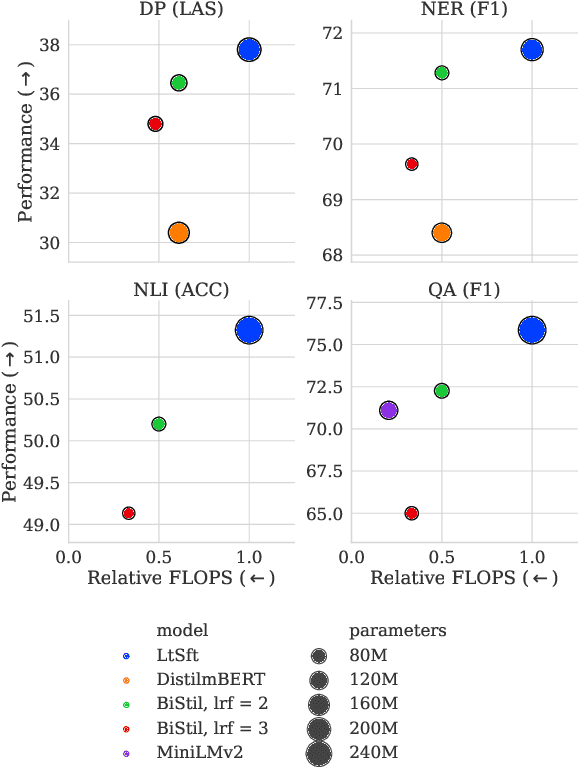



Massively multilingual Transformers (MMTs), such as mBERT and XLM-R, are widely used for cross-lingual transfer learning. While these are pretrained to represent hundreds of languages, end users of NLP systems are often interested only in individual languages. For such purposes, the MMTs' language coverage makes them unnecessarily expensive to deploy in terms of model size, inference time, energy, and hardware cost. We thus propose to extract compressed, language-specific models from MMTs which retain the capacity of the original MMTs for cross-lingual transfer. This is achieved by distilling the MMT bilingually, i.e., using data from only the source and target language of interest. Specifically, we use a two-phase distillation approach, termed BiStil: (i) the first phase distils a general bilingual model from the MMT, while (ii) the second, task-specific phase sparsely fine-tunes the bilingual "student" model using a task-tuned variant of the original MMT as its "teacher". We evaluate this distillation technique in zero-shot cross-lingual transfer across a number of standard cross-lingual benchmarks. The key results indicate that the distilled models exhibit minimal degradation in target language performance relative to the base MMT despite being significantly smaller and faster. Furthermore, we find that they outperform multilingually distilled models such as DistilmBERT and MiniLMv2 while having a very modest training budget in comparison, even on a per-language basis. We also show that bilingual models distilled from MMTs greatly outperform bilingual models trained from scratch. Our code and models are available at https://github.com/AlanAnsell/bistil.
Composable Sparse Fine-Tuning for Cross-Lingual Transfer
Oct 14, 2021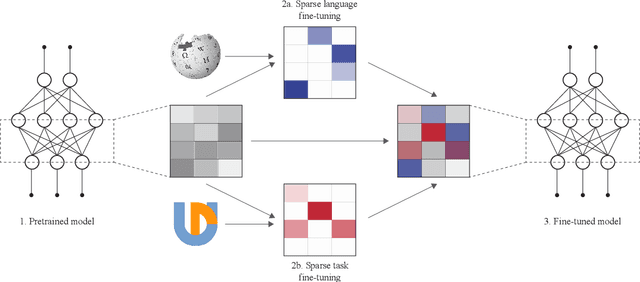
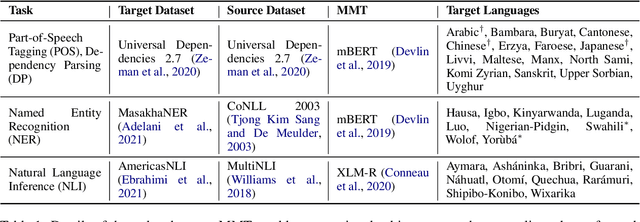
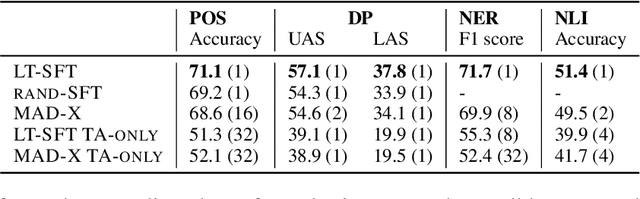
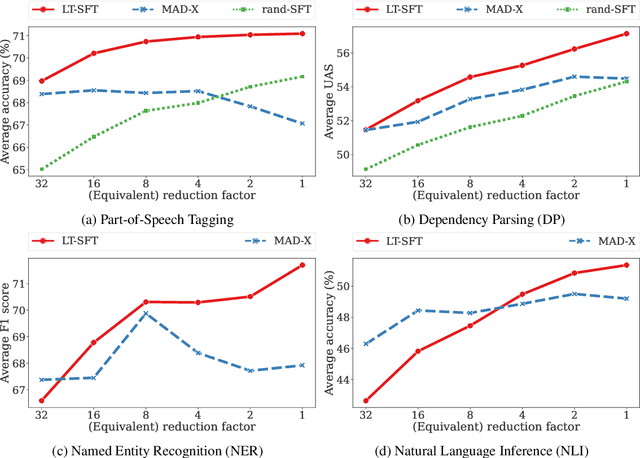
Fine-tuning all parameters of a pre-trained model has become the mainstream approach for transfer learning. To increase its efficiency and prevent catastrophic forgetting and interference, techniques like adapters and sparse fine-tuning have been developed. Adapters are modular, as they can be combined to adapt a model towards different facets of knowledge (e.g., dedicated language and/or task adapters). Sparse fine-tuning is expressive, as it controls the behavior of all model components. In this work, we introduce a new fine-tuning method with both these desirable properties. In particular, we learn sparse, real-valued masks based on a simple variant of the Lottery Ticket Hypothesis. Task-specific masks are obtained from annotated data in a source language, and language-specific masks from masked language modeling in a target language. Both these masks can then be composed with the pre-trained model. Unlike adapter-based fine-tuning, this method neither increases the number of parameters at inference time nor alters the original model architecture. Most importantly, it outperforms adapters in zero-shot cross-lingual transfer by a large margin in a series of multilingual benchmarks, including Universal Dependencies, MasakhaNER, and AmericasNLI. Based on an in-depth analysis, we additionally find that sparsity is crucial to prevent both 1) interference between the fine-tunings to be composed and 2) overfitting. We release the code and models at https://github.com/cambridgeltl/composable-sft.
PolyLM: Learning about Polysemy through Language Modeling
Jan 25, 2021

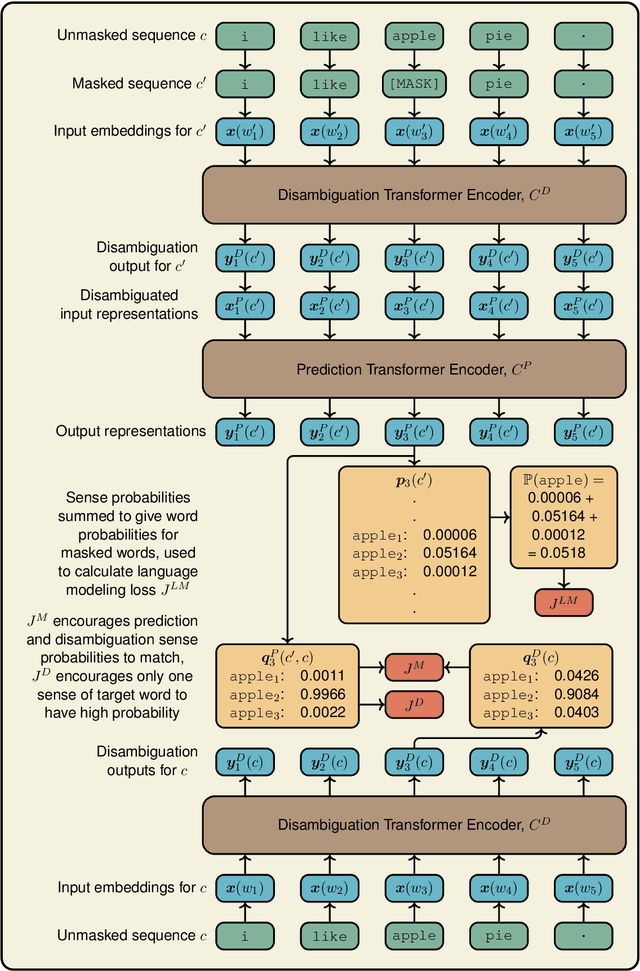
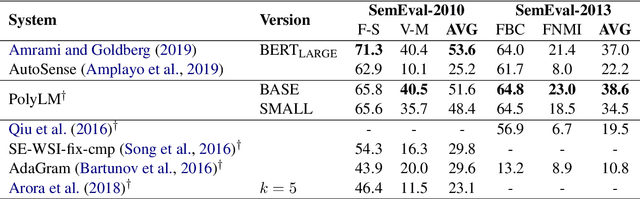
To avoid the "meaning conflation deficiency" of word embeddings, a number of models have aimed to embed individual word senses. These methods at one time performed well on tasks such as word sense induction (WSI), but they have since been overtaken by task-specific techniques which exploit contextualized embeddings. However, sense embeddings and contextualization need not be mutually exclusive. We introduce PolyLM, a method which formulates the task of learning sense embeddings as a language modeling problem, allowing contextualization techniques to be applied. PolyLM is based on two underlying assumptions about word senses: firstly, that the probability of a word occurring in a given context is equal to the sum of the probabilities of its individual senses occurring; and secondly, that for a given occurrence of a word, one of its senses tends to be much more plausible in the context than the others. We evaluate PolyLM on WSI, showing that it performs considerably better than previous sense embedding techniques, and matches the current state-of-the-art specialized WSI method despite having six times fewer parameters. Code and pre-trained models are available at https://github.com/AlanAnsell/PolyLM.