 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Data Is Scarce: Scaling Sparse Language Models with Repeated Training
May 31, 2026Scaling laws for dense LLMs under infinite data are well explored, but how sparsity interacts with limited data is not. In this work, we study sparse training in data-constrained regimes where limited unique tokens require multi-epoch training. Our experiments span models up to 1.92B parameters in the fitting set, sparsity up to 93.75%, unique data budgets up to 2.6B tokens, and total training tokens up to 41.6B over 16 epochs; we further validate extrapolation on held-out dense-equivalent models up to 7.68B parameters. We find that: 1. Sparse scaling in data-limited settings: We introduce a scaling law that models loss as a function of active parameters, unique tokens, data repetition, and sparsity, accurately predicting performance across compute and data budgets. 2. Delayed data saturation: sparse training postpones diminishing returns from repeated data, making multi-epoch training more effective. 3. Resource trade-offs: With fixed data, loss-optimal sparsity is moderate ~ 50%, while compute-optimal sparsity is higher and grows with data scale. Overall, sparsity is not just a tool for efficiency, but a mechanism for improving scaling trade-offs under data scarcity. Our code is available at: https://github.com/boqian333/sparse-dc-scaling.
Memory-Efficient LLM Training with Dynamic Sparsity: From Stability to Practical Scaling
May 30, 2026Dynamic Sparse Training (DST) offers a promising paradigm for improving the training and inference efficiency of deep neural networks; however, we find that in large language model training, DST can suffer from optimization instability, manifested as loss spikes after topology updates. In this work, we show that the naive use of standard Adam-based optimizers leads to a cold-start issue for newly regrown parameters, resulting in excessively large updates and disrupted training dynamics. To address this issue, we propose Sparse Memory-Efficient Training (SMET), which stabilizes DST with optimizer warm-up and improves training progress through density-aware learning-rate scaling. SMET further reduces memory consumption by storing gradients and optimizer states only for active parameters. We provide a theoretical analysis of the update behaviors under SMET, showing improved optimization stability. Extensive experiments demonstrate that SMET enables stable, scalable, and memory-efficient sparse pre-training of LLMs, paving the way for sparse training as a practical alternative to dense training. Our code is publicly available at: https://github.com/QiaoXiao7282/SMET.
C-SHAP for time series: An approach to high-level temporal explanations
Apr 15, 2025



Time series are ubiquitous in domains such as energy forecasting, healthcare, and industry. Using AI systems, some tasks within these domains can be efficiently handled. Explainable AI (XAI) aims to increase the reliability of AI solutions by explaining model reasoning. For time series, many XAI methods provide point- or sequence-based attribution maps. These methods explain model reasoning in terms of low-level patterns. However, they do not capture high-level patterns that may also influence model reasoning. We propose a concept-based method to provide explanations in terms of these high-level patterns. In this paper, we present C-SHAP for time series, an approach which determines the contribution of concepts to a model outcome. We provide a general definition of C-SHAP and present an example implementation using time series decomposition. Additionally, we demonstrate the effectiveness of the methodology through a use case from the energy domain.
Dynamic Sparse Training versus Dense Training: The Unexpected Winner in Image Corruption Robustness
Oct 03, 2024
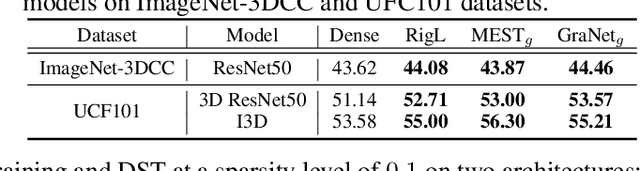
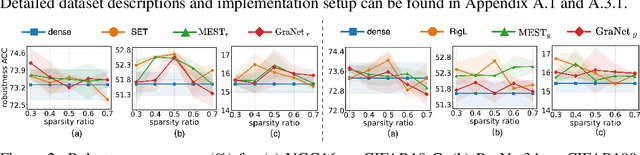

It is generally perceived that Dynamic Sparse Training opens the door to a new era of scalability and efficiency for artificial neural networks at, perhaps, some costs in accuracy performance for the classification task. At the same time, Dense Training is widely accepted as being the "de facto" approach to train artificial neural networks if one would like to maximize their robustness against image corruption. In this paper, we question this general practice. Consequently, we claim that, contrary to what is commonly thought, the Dynamic Sparse Training methods can consistently outperform Dense Training in terms of robustness accuracy, particularly if the efficiency aspect is not considered as a main objective (i.e., sparsity levels between 10% and up to 50%), without adding (or even reducing) resource cost. We validate our claim on two types of data, images and videos, using several traditional and modern deep learning architectures for computer vision and three widely studied Dynamic Sparse Training algorithms. Our findings reveal a new yet-unknown benefit of Dynamic Sparse Training and open new possibilities in improving deep learning robustness beyond the current state of the art.
Prototype-based Interpretable Breast Cancer Prediction Models: Analysis and Challenges
Mar 29, 2024



Deep learning models have achieved high performance in medical applications, however, their adoption in clinical practice is hindered due to their black-box nature. Self-explainable models, like prototype-based models, can be especially beneficial as they are interpretable by design. However, if the learnt prototypes are of low quality then the prototype-based models are as good as black-box. Having high quality prototypes is a pre-requisite for a truly interpretable model. In this work, we propose a prototype evaluation framework for coherence (PEF-C) for quantitatively evaluating the quality of the prototypes based on domain knowledge. We show the use of PEF-C in the context of breast cancer prediction using mammography. Existing works on prototype-based models on breast cancer prediction using mammography have focused on improving the classification performance of prototype-based models compared to black-box models and have evaluated prototype quality through anecdotal evidence. We are the first to go beyond anecdotal evidence and evaluate the quality of the mammography prototypes systematically using our PEF-C. Specifically, we apply three state-of-the-art prototype-based models, ProtoPNet, BRAIxProtoPNet++ and PIP-Net on mammography images for breast cancer prediction and evaluate these models w.r.t. i) classification performance, and ii) quality of the prototypes, on three public datasets. Our results show that prototype-based models are competitive with black-box models in terms of classification performance, and achieve a higher score in detecting ROIs. However, the quality of the prototypes are not yet sufficient and can be improved in aspects of relevance, purity and learning a variety of prototypes. We call the XAI community to systematically evaluate the quality of the prototypes to check their true usability in high stake decisions and improve such models further.
Weakly Supervised Learning for Breast Cancer Prediction on Mammograms in Realistic Settings
Oct 19, 2023



Automatic methods for early detection of breast cancer on mammography can significantly decrease mortality. Broad uptake of those methods in hospitals is currently hindered because the methods have too many constraints. They assume annotations available for single images or even regions-of-interest (ROIs), and a fixed number of images per patient. Both assumptions do not hold in a general hospital setting. Relaxing those assumptions results in a weakly supervised learning setting, where labels are available per case, but not for individual images or ROIs. Not all images taken for a patient contain malignant regions and the malignant ROIs cover only a tiny part of an image, whereas most image regions represent benign tissue. In this work, we investigate a two-level multi-instance learning (MIL) approach for case-level breast cancer prediction on two public datasets (1.6k and 5k cases) and an in-house dataset of 21k cases. Observing that breast cancer is usually only present in one side, while images of both breasts are taken as a precaution, we propose a domain-specific MIL pooling variant. We show that two-level MIL can be applied in realistic clinical settings where only case labels, and a variable number of images per patient are available. Data in realistic settings scales with continuous patient intake, while manual annotation efforts do not. Hence, research should focus in particular on unsupervised ROI extraction, in order to improve breast cancer prediction for all patients.
Interpreting and Correcting Medical Image Classification with PIP-Net
Jul 19, 2023Part-prototype models are explainable-by-design image classifiers, and a promising alternative to black box AI. This paper explores the applicability and potential of interpretable machine learning, in particular PIP-Net, for automated diagnosis support on real-world medical imaging data. PIP-Net learns human-understandable prototypical image parts and we evaluate its accuracy and interpretability for fracture detection and skin cancer diagnosis. We find that PIP-Net's decision making process is in line with medical classification standards, while only provided with image-level class labels. Because of PIP-Net's unsupervised pretraining of prototypes, data quality problems such as undesired text in an X-ray or labelling errors can be easily identified. Additionally, we are the first to show that humans can manually correct the reasoning of PIP-Net by directly disabling undesired prototypes. We conclude that part-prototype models are promising for medical applications due to their interpretability and potential for advanced model debugging.
From Anecdotal Evidence to Quantitative Evaluation Methods: A Systematic Review on Evaluating Explainable AI
Jan 20, 2022
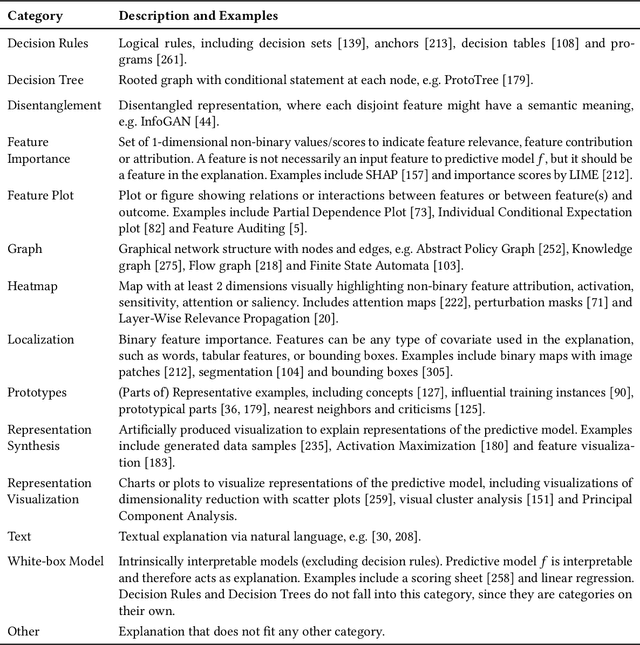

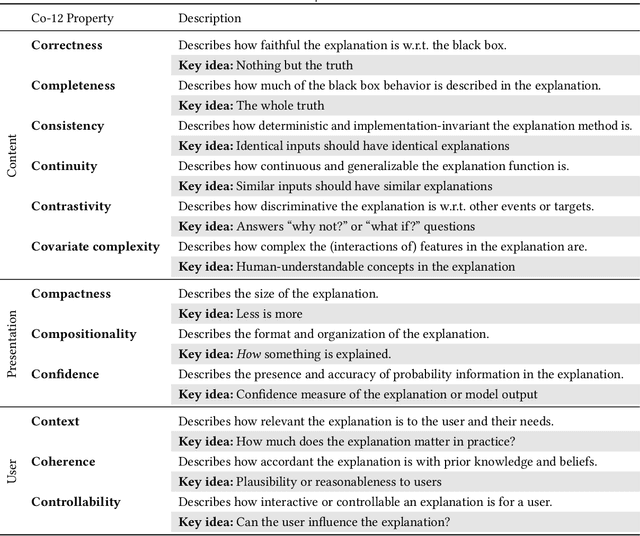
The rising popularity of explainable artificial intelligence (XAI) to understand high-performing black boxes, also raised the question of how to evaluate explanations of machine learning (ML) models. While interpretability and explainability are often presented as a subjectively validated binary property, we consider it a multi-faceted concept. We identify 12 conceptual properties, such as Compactness and Correctness, that should be evaluated for comprehensively assessing the quality of an explanation. Our so-called Co-12 properties serve as categorization scheme for systematically reviewing the evaluation practice of more than 300 papers published in the last 7 years at major AI and ML conferences that introduce an XAI method. We find that 1 in 3 papers evaluate exclusively with anecdotal evidence, and 1 in 5 papers evaluate with users. We also contribute to the call for objective, quantifiable evaluation methods by presenting an extensive overview of quantitative XAI evaluation methods. This systematic collection of evaluation methods provides researchers and practitioners with concrete tools to thoroughly validate, benchmark and compare new and existing XAI methods. This also opens up opportunities to include quantitative metrics as optimization criteria during model training in order to optimize for accuracy and interpretability simultaneously.