 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable AI to Improve Machine Learning Reliability for Industrial Cyber-Physical Systems
Jan 22, 2026Industrial Cyber-Physical Systems (CPS) are sensitive infrastructure from both safety and economics perspectives, making their reliability critically important. Machine Learning (ML), specifically deep learning, is increasingly integrated in industrial CPS, but the inherent complexity of ML models results in non-transparent operation. Rigorous evaluation is needed to prevent models from exhibiting unexpected behaviour on future, unseen data. Explainable AI (XAI) can be used to uncover model reasoning, allowing a more extensive analysis of behaviour. We apply XAI to to improve predictive performance of ML models intended for industrial CPS. We analyse the effects of components from time-series data decomposition on model predictions using SHAP values. Through this method, we observe evidence on the lack of sufficient contextual information during model training. By increasing the window size of data instances, informed by the XAI findings, we are able to improve model performance.
C-SHAP for time series: An approach to high-level temporal explanations
Apr 15, 2025



Time series are ubiquitous in domains such as energy forecasting, healthcare, and industry. Using AI systems, some tasks within these domains can be efficiently handled. Explainable AI (XAI) aims to increase the reliability of AI solutions by explaining model reasoning. For time series, many XAI methods provide point- or sequence-based attribution maps. These methods explain model reasoning in terms of low-level patterns. However, they do not capture high-level patterns that may also influence model reasoning. We propose a concept-based method to provide explanations in terms of these high-level patterns. In this paper, we present C-SHAP for time series, an approach which determines the contribution of concepts to a model outcome. We provide a general definition of C-SHAP and present an example implementation using time series decomposition. Additionally, we demonstrate the effectiveness of the methodology through a use case from the energy domain.
This Looks Like That, Because ... Explaining Prototypes for Interpretable Image Recognition
Nov 05, 2020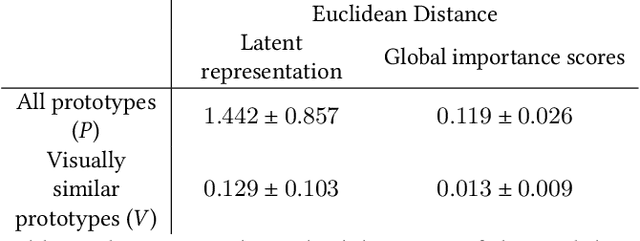


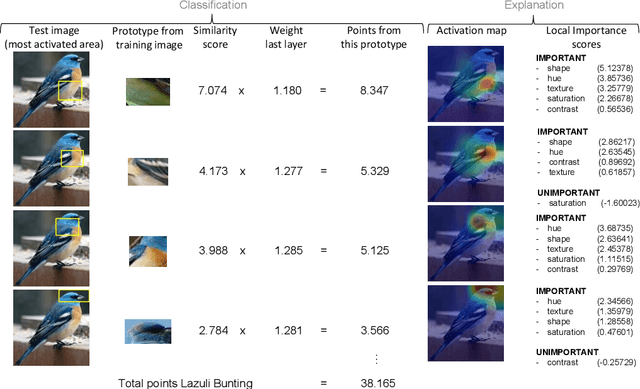
Image recognition with prototypes is considered an interpretable alternative for black box deep learning models. Classification depends on the extent to which a test image "looks like" a prototype. However, perceptual similarity for humans can be different from the similarity learnt by the model. A user is unaware of the underlying classification strategy and does not know which image characteristics (e.g., color or shape) is the dominant characteristic for the decision. We address this ambiguity and argue that prototypes should be explained. Only visualizing prototypes can be insufficient for understanding what a prototype exactly represents, and why a prototype and an image are considered similar. We improve interpretability by automatically enhancing prototypes with extra information about visual characteristics considered important by the model. Specifically, our method quantifies the influence of color hue, shape, texture, contrast and saturation in a prototype. We apply our method to the existing Prototypical Part Network (ProtoPNet) and show that our explanations clarify the meaning of a prototype which might have been interpreted incorrectly otherwise. We also reveal that visually similar prototypes can have the same explanations, indicating redundancy. Because of the generality of our approach, it can improve the interpretability of any similarity-based method for prototypical image recognition.