 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Possibility of Fairness: Revisiting the Impossibility Theorem in Practice
Feb 13, 2023The ``impossibility theorem'' -- which is considered foundational in algorithmic fairness literature -- asserts that there must be trade-offs between common notions of fairness and performance when fitting statistical models, except in two special cases: when the prevalence of the outcome being predicted is equal across groups, or when a perfectly accurate predictor is used. However, theory does not always translate to practice. In this work, we challenge the implications of the impossibility theorem in practical settings. First, we show analytically that, by slightly relaxing the impossibility theorem (to accommodate a \textit{practitioner's} perspective of fairness), it becomes possible to identify a large set of models that satisfy seemingly incompatible fairness constraints. Second, we demonstrate the existence of these models through extensive experiments on five real-world datasets. We conclude by offering tools and guidance for practitioners to understand when -- and to what degree -- fairness along multiple criteria can be achieved. For example, if one allows only a small margin-of-error between metrics, there exists a large set of models simultaneously satisfying \emph{False Negative Rate Parity}, \emph{False Positive Rate Parity}, and \emph{Positive Predictive Value Parity}, even when there is a moderate prevalence difference between groups. This work has an important implication for the community: achieving fairness along multiple metrics for multiple groups (and their intersections) is much more possible than was previously believed.
Argumentative Topology: Finding Loop(holes) in Logic
Nov 17, 2020
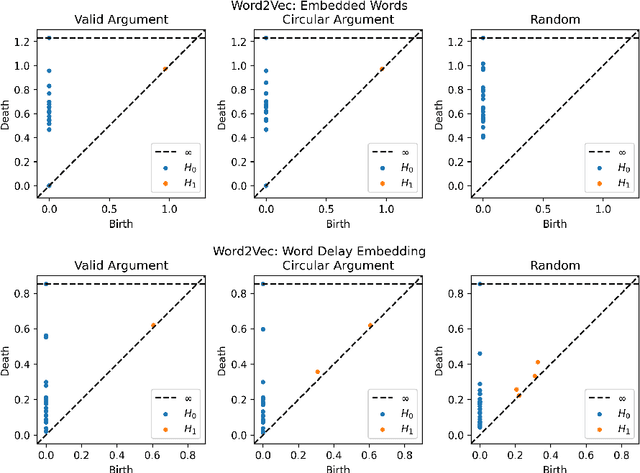
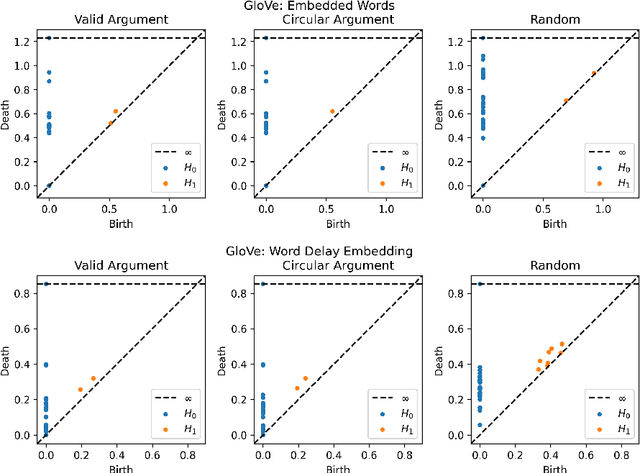
Advances in natural language processing have resulted in increased capabilities with respect to multiple tasks. One of the possible causes of the observed performance gains is the introduction of increasingly sophisticated text representations. While many of the new word embedding techniques can be shown to capture particular notions of sentiment or associative structures, we explore the ability of two different word embeddings to uncover or capture the notion of logical shape in text. To this end we present a novel framework that we call Topological Word Embeddings which leverages mathematical techniques in dynamical system analysis and data driven shape extraction (i.e. topological data analysis). In this preliminary work we show that using a topological delay embedding we are able to capture and extract a different, shape-based notion of logic aimed at answering the question "Can we find a circle in a circular argument?"