 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Width-Based Planning and Learning
Jan 15, 2021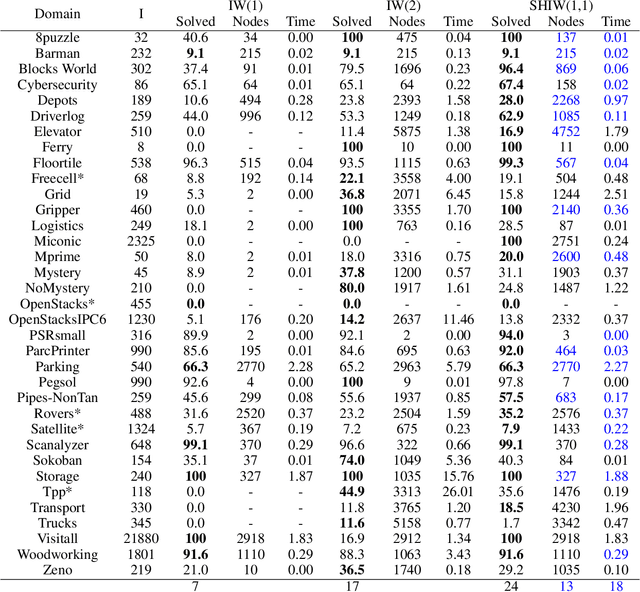
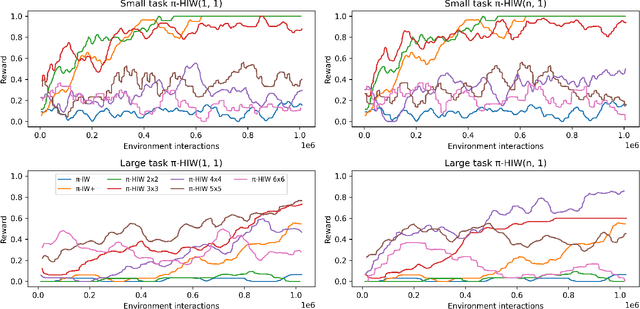
Width-based search methods have demonstrated state-of-the-art performance in a wide range of testbeds, from classical planning problems to image-based simulators such as Atari games. These methods scale independently of the size of the state-space, but exponentially in the problem width. In practice, running the algorithm with a width larger than 1 is computationally intractable, prohibiting IW from solving higher width problems. In this paper, we present a hierarchical algorithm that plans at two levels of abstraction. A high-level planner uses abstract features that are incrementally discovered from low-level pruning decisions. We illustrate this algorithm in classical planning PDDL domains as well as in pixel-based simulator domains. In classical planning, we show how IW(1) at two levels of abstraction can solve problems of width 2. For pixel-based domains, we show how in combination with a learned policy and a learned value function, the proposed hierarchical IW can outperform current flat IW-based planners in Atari games with sparse rewards.
Deep Policies for Width-Based Planning in Pixel Domains
Apr 12, 2019



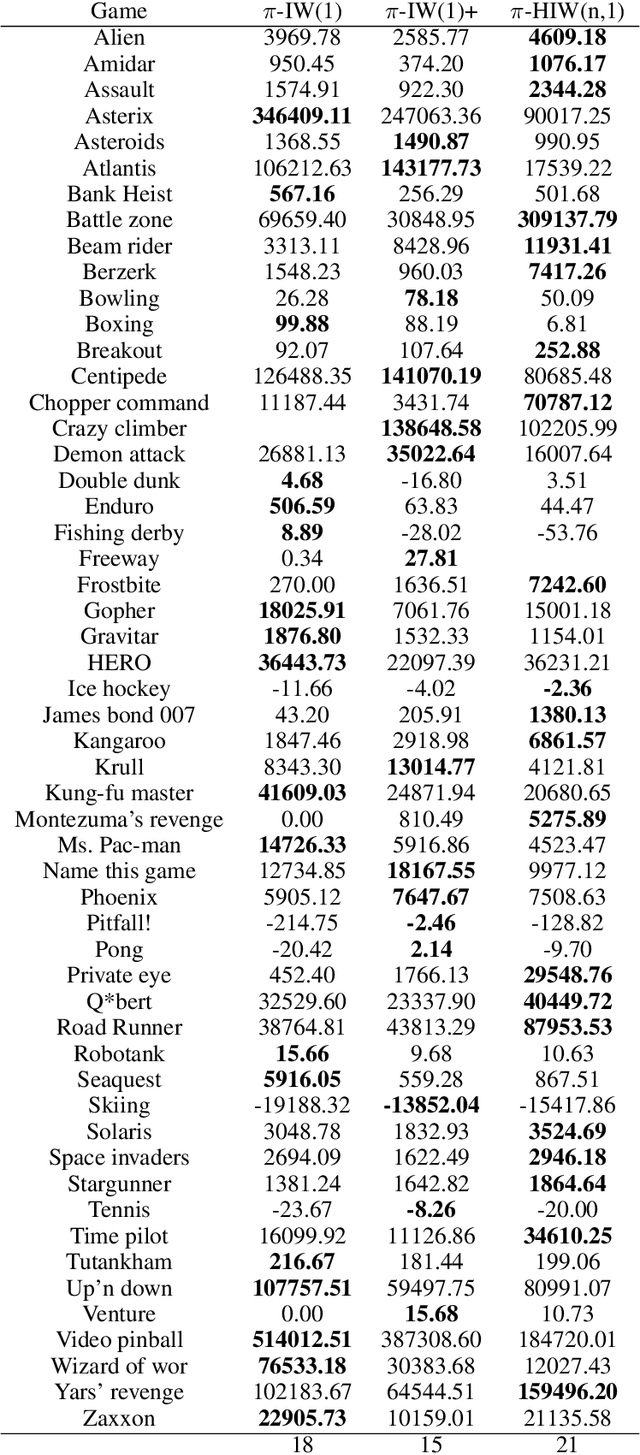
Width-based planning has demonstrated great success in recent years due to its ability to scale independently of the size of the state space. For example, Bandres et al. (2018) introduced a rollout version of the Iterated Width algorithm whose performance compares well with humans and learning methods in the pixel setting of the Atari games suite. In this setting, planning is done on-line using the "screen" states and selecting actions by looking ahead into the future. However, this algorithm is purely exploratory and does not leverage past reward information. Furthermore, it requires the state to be factored into features that need to be pre-defined for the particular task, e.g., the B-PROST pixel features. In this work, we extend width-based planning by incorporating an explicit policy in the action selection mechanism. Our method, called $\pi$-IW, interleaves width-based planning and policy learning using the state-actions visited by the planner. The policy estimate takes the form of a neural network and is in turn used to guide the planning step, thus reinforcing promising paths. Surprisingly, we observe that the representation learned by the neural network can be used as a feature space for the width-based planner without degrading its performance, thus removing the requirement of pre-defined features for the planner. We compare $\pi$-IW with previous width-based methods and with AlphaZero, a method that also interleaves planning and learning, in simple environments, and show that $\pi$-IW has superior performance. We also show that $\pi$-IW algorithm outperforms previous width-based methods in the pixel setting of Atari games suite.
Improving width-based planning with compact policies
Jun 15, 2018



Optimal action selection in decision problems characterized by sparse, delayed rewards is still an open challenge. For these problems, current deep reinforcement learning methods require enormous amounts of data to learn controllers that reach human-level performance. In this work, we propose a method that interleaves planning and learning to address this issue. The planning step hinges on the Iterated-Width (IW) planner, a state of the art planner that makes explicit use of the state representation to perform structured exploration. IW is able to scale up to problems independently of the size of the state space. From the state-actions visited by IW, the learning step estimates a compact policy, which in turn is used to guide the planning step. The type of exploration used by our method is radically different than the standard random exploration used in RL. We evaluate our method in simple problems where we show it to have superior performance than the state-of-the-art reinforcement learning algorithms A2C and Alpha Zero. Finally, we present preliminary results in a subset of the Atari games suite.