 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObjective hearing threshold identification from auditory brainstem response measurements using supervised and self-supervised approaches
Dec 16, 2021
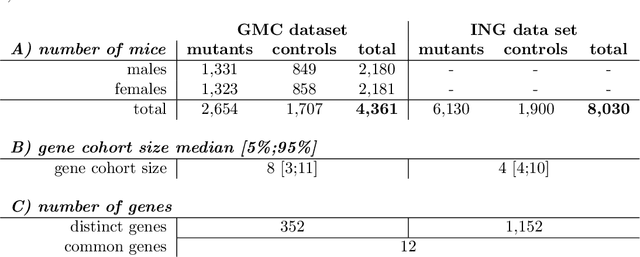
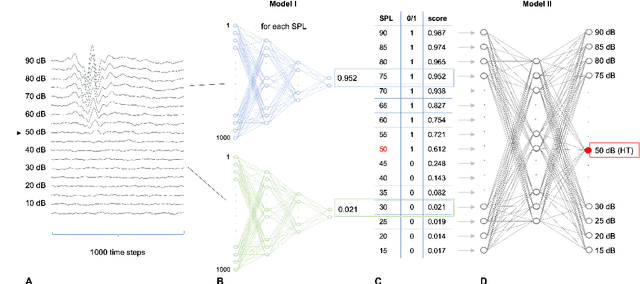
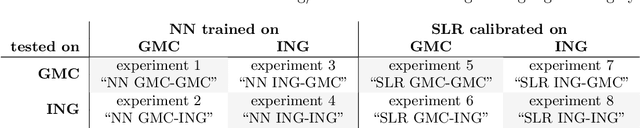
Hearing loss is a major health problem and psychological burden in humans. Mouse models offer a possibility to elucidate genes involved in the underlying developmental and pathophysiological mechanisms of hearing impairment. To this end, large-scale mouse phenotyping programs include auditory phenotyping of single-gene knockout mouse lines. Using the auditory brainstem response (ABR) procedure, the German Mouse Clinic and similar facilities worldwide have produced large, uniform data sets of averaged ABR raw data of mutant and wildtype mice. In the course of standard ABR analysis, hearing thresholds are assessed visually by trained staff from series of signal curves of increasing sound pressure level. This is time-consuming and prone to be biased by the reader as well as the graphical display quality and scale. In an attempt to reduce workload and improve quality and reproducibility, we developed and compared two methods for automated hearing threshold identification from averaged ABR raw data: a supervised approach involving two combined neural networks trained on human-generated labels and a self-supervised approach, which exploits the signal power spectrum and combines random forest sound level estimation with a piece-wise curve fitting algorithm for threshold finding. We show that both models work well, outperform human threshold detection, and are suitable for fast, reliable, and unbiased hearing threshold detection and quality control. In a high-throughput mouse phenotyping environment, both methods perform well as part of an automated end-to-end screening pipeline to detect candidate genes for hearing involvement. Code for both models as well as data used for this work are freely available.
deepregression: a Flexible Neural Network Framework for Semi-Structured Deep Distributional Regression
Apr 06, 2021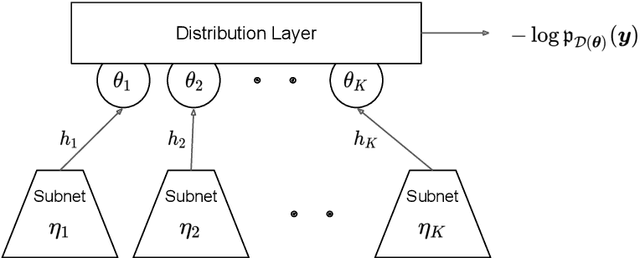
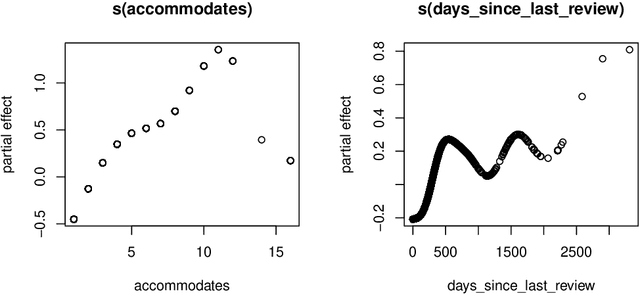
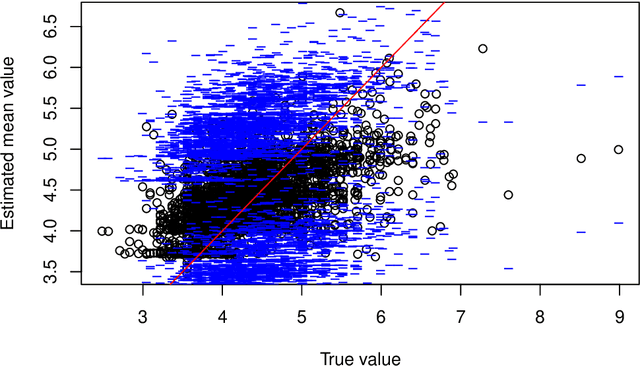
This paper describes the implementation of semi-structured deep distributional regression, a flexible framework to learn distributions based on a combination of additive regression models and deep neural networks. deepregression is implemented in both R and Python, using the deep learning libraries TensorFlow and PyTorch, respectively. The implementation consists of (1) a modular neural network building system for the combination of various statistical and deep learning approaches, (2) an orthogonalization cell to allow for an interpretable combination of different subnetworks as well as (3) pre-processing steps necessary to initialize such models. The software package allows to define models in a user-friendly manner using distribution definitions via a formula environment that is inspired by classical statistical model frameworks such as mgcv. The packages' modular design and functionality provides a unique resource for rapid and reproducible prototyping of complex statistical and deep learning models while simultaneously retaining the indispensable interpretability of classical statistical models.
Adaptive Smoothing Path Integral Control
May 13, 2020
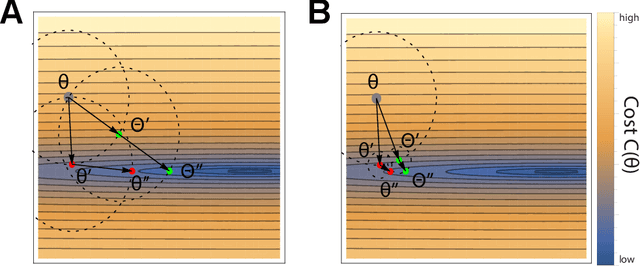
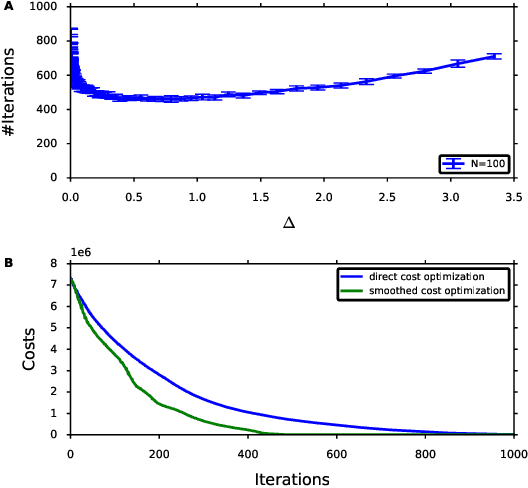
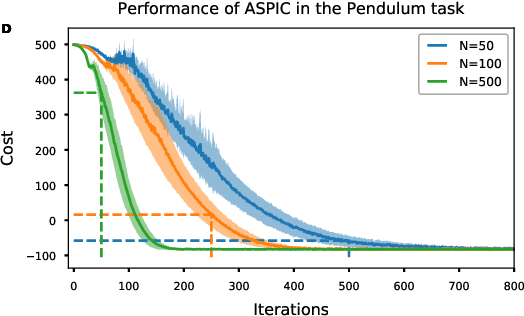
In Path Integral control problems a representation of an optimally controlled dynamical system can be formally computed and serve as a guidepost to learn a parametrized policy. The Path Integral Cross-Entropy (PICE) method tries to exploit this, but is hampered by poor sample efficiency. We propose a model-free algorithm called ASPIC (Adaptive Smoothing of Path Integral Control) that applies an inf-convolution to the cost function to speedup convergence of policy optimization. We identify PICE as the infinite smoothing limit of such technique and show that the sample efficiency problems that PICE suffers disappear for finite levels of smoothing. For zero smoothing this method becomes a greedy optimization of the cost, which is the standard approach in current reinforcement learning. We show analytically and empirically that intermediate levels of smoothing are optimal, which renders the new method superior to both PICE and direct cost-optimization.