 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounteracting Matthew Effect in Self-Improvement of LVLMs through Head-Tail Re-balancing
Oct 30, 2025Self-improvement has emerged as a mainstream paradigm for advancing the reasoning capabilities of large vision-language models (LVLMs), where models explore and learn from successful trajectories iteratively. However, we identify a critical issue during this process: the model excels at generating high-quality trajectories for simple queries (i.e., head data) but struggles with more complex ones (i.e., tail data). This leads to an imbalanced optimization that drives the model to prioritize simple reasoning skills, while hindering its ability to tackle more complex reasoning tasks. Over iterations, this imbalance becomes increasingly pronounced--a dynamic we term the "Matthew effect"--which ultimately hinders further model improvement and leads to performance bottlenecks. To counteract this challenge, we introduce four efficient strategies from two perspectives: distribution-reshaping and trajectory-resampling, to achieve head-tail re-balancing during the exploration-and-learning self-improvement process. Extensive experiments on Qwen2-VL-7B-Instruct and InternVL2.5-4B models across visual reasoning tasks demonstrate that our methods consistently improve visual reasoning capabilities, outperforming vanilla self-improvement by 3.86 points on average.
AgentGym-RL: Training LLM Agents for Long-Horizon Decision Making through Multi-Turn Reinforcement Learning
Sep 10, 2025Developing autonomous LLM agents capable of making a series of intelligent decisions to solve complex, real-world tasks is a fast-evolving frontier. Like human cognitive development, agents are expected to acquire knowledge and skills through exploration and interaction with the environment. Despite advances, the community still lacks a unified, interactive reinforcement learning (RL) framework that can effectively train such agents from scratch -- without relying on supervised fine-tuning (SFT) -- across diverse and realistic environments. To bridge this gap, we introduce AgentGym-RL, a new framework to train LLM agents for multi-turn interactive decision-making through RL. The framework features a modular and decoupled architecture, ensuring high flexibility and extensibility. It encompasses a wide variety of real-world scenarios, and supports mainstream RL algorithms. Furthermore, we propose ScalingInter-RL, a training approach designed for exploration-exploitation balance and stable RL optimization. In early stages, it emphasizes exploitation by restricting the number of interactions, and gradually shifts towards exploration with larger horizons to encourage diverse problem-solving strategies. In this way, the agent develops more diverse behaviors and is less prone to collapse under long horizons. We perform extensive experiments to validate the stability and effectiveness of both the AgentGym-RL framework and the ScalingInter-RL approach. Our agents match or surpass commercial models on 27 tasks across diverse environments. We offer key insights and will open-source the complete AgentGym-RL framework -- including code and datasets -- to empower the research community in developing the next generation of intelligent agents.
Fuzzy Lattice-based Description Logic
Jun 06, 2025Recently, description logic LE-ALC was introduced for reasoning in the semantic environment of enriched formal contexts, and a polynomial-time tableaux algorithm was developed to check the consistency of knowledge bases with acyclic TBoxes. In this work, we introduce a fuzzy generalization of LE-ALC called LE-FALC which provides a description logic counterpart of many-valued normal non-distributive logic a.k.a. many-valued LE-logic. This description logic can be used to represent and reason about knowledge in the formal framework of fuzzy formal contexts and fuzzy formal concepts. We provide a tableaux algorithm that provides a complete and sound polynomial-time decision procedure to check the consistency of LE-FALC ABoxes. As a result, we also obtain an exponential-time decision procedure for checking the consistency of LE-FALC with acyclic TBoxes by unraveling.
* In Proceedings LSFA 2024, arXiv:2506.05219
MANTA: A Large-Scale Multi-View and Visual-Text Anomaly Detection Dataset for Tiny Objects
Dec 06, 2024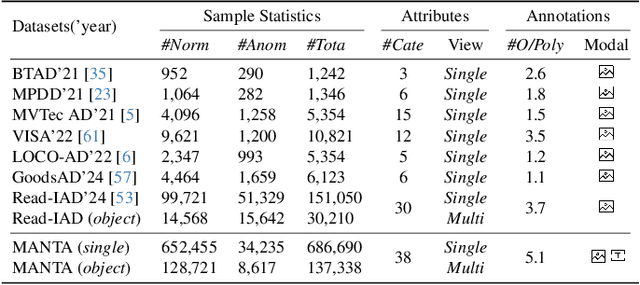
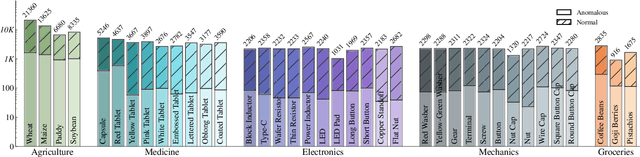

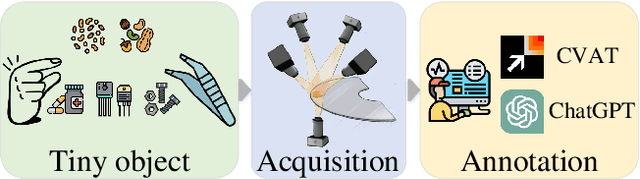
We present MANTA, a visual-text anomaly detection dataset for tiny objects. The visual component comprises over 137.3K images across 38 object categories spanning five typical domains, of which 8.6K images are labeled as anomalous with pixel-level annotations. Each image is captured from five distinct viewpoints to ensure comprehensive object coverage. The text component consists of two subsets: Declarative Knowledge, including 875 words that describe common anomalies across various domains and specific categories, with detailed explanations for < what, why, how>, including causes and visual characteristics; and Constructivist Learning, providing 2K multiple-choice questions with varying levels of difficulty, each paired with images and corresponded answer explanations. We also propose a baseline for visual-text tasks and conduct extensive benchmarking experiments to evaluate advanced methods across different settings, highlighting the challenges and efficacy of our dataset.
Enhancing LLM Reasoning via Critique Models with Test-Time and Training-Time Supervision
Nov 25, 2024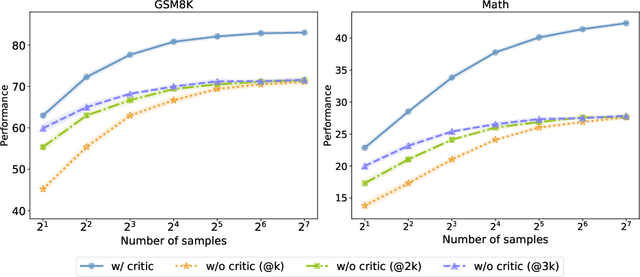

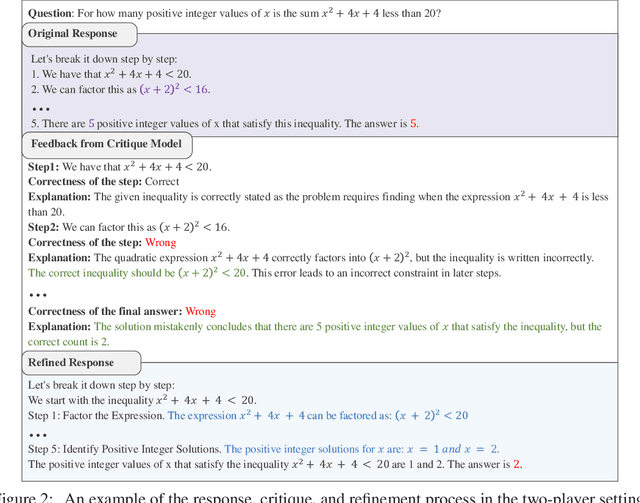

Training large language models (LLMs) to spend more time thinking and reflection before responding is crucial for effectively solving complex reasoning tasks in fields such as science, coding, and mathematics. However, the effectiveness of mechanisms like self-reflection and self-correction depends on the model's capacity to accurately assess its own performance, which can be limited by factors such as initial accuracy, question difficulty, and the lack of external feedback. In this paper, we delve into a two-player paradigm that separates the roles of reasoning and critique models, where the critique model provides step-level feedback to supervise the reasoning (actor) model during both test-time and train-time. We first propose AutoMathCritique, an automated and scalable framework for collecting critique data, resulting in a dataset of $76,321$ responses paired with step-level feedback. Fine-tuning language models with this dataset enables them to generate natural language feedback for mathematical reasoning. We demonstrate that the critique models consistently improve the actor's performance on difficult queries at test-time, especially when scaling up inference-time computation. Motivated by these findings, we introduce the critique-based supervision to the actor's self-training process, and propose a critique-in-the-loop self-improvement method. Experiments show that the method improves the actor's exploration efficiency and solution diversity, especially on challenging queries, leading to a stronger reasoning model. Lastly, we take the preliminary step to explore training self-talk reasoning models via critique supervision and showcase its potential. Our code and datasets are at \href{https://mathcritique.github.io/}{https://mathcritique.github.io/}.
Mitigating Tail Narrowing in LLM Self-Improvement via Socratic-Guided Sampling
Nov 01, 2024Self-improvement methods enable large language models (LLMs) to generate solutions themselves and iteratively train on filtered, high-quality rationales. This process proves effective and reduces the reliance on human supervision in LLMs' reasoning, but the performance soon plateaus. We delve into the process and find that models tend to over-sample on easy queries and under-sample on queries they have yet to master. As iterations proceed, this imbalance in sampling is exacerbated, leading to a long-tail distribution where solutions to difficult queries almost diminish. This phenomenon limits the performance gain of self-improving models. A straightforward solution is brute-force sampling to balance the distribution, which significantly raises computational costs. In this paper, we introduce Guided Self-Improvement (GSI), a strategy aimed at improving the efficiency of sampling challenging heavy-tailed data. It leverages Socratic-style guidance signals to help LLM reasoning with complex queries, reducing the exploration effort and minimizing computational overhead. Experiments on four models across diverse mathematical tasks show that GSI strikes a balance between performance and efficiency, while also being effective on held-out tasks.
Distill Visual Chart Reasoning Ability from LLMs to MLLMs
Oct 24, 2024



Solving complex chart Q&A tasks requires advanced visual reasoning abilities in multimodal large language models (MLLMs). Recent studies highlight that these abilities consist of two main parts: recognizing key information from visual inputs and conducting reasoning over it. Thus, a promising approach to enhance MLLMs is to construct relevant training data focusing on the two aspects. However, collecting and annotating complex charts and questions is costly and time-consuming, and ensuring the quality of annotated answers remains a challenge. In this paper, we propose Code-as-Intermediary Translation (CIT), a cost-effective, efficient and easily scalable data synthesis method for distilling visual reasoning abilities from LLMs to MLLMs. The code serves as an intermediary that translates visual chart representations into textual representations, enabling LLMs to understand cross-modal information. Specifically, we employ text-based synthesizing techniques to construct chart-plotting code and produce ReachQA, a dataset containing 3k reasoning-intensive charts and 20k Q&A pairs to enhance both recognition and reasoning abilities. Experiments show that when fine-tuned with our data, models not only perform well on chart-related benchmarks, but also demonstrate improved multimodal reasoning abilities on general mathematical benchmarks like MathVista. The code and dataset are publicly available at https://github.com/hewei2001/ReachQA.
Defeasible Reasoning on Concepts
Sep 07, 2024
In this paper, we take first steps toward developing defeasible reasoning on concepts in KLM framework. We define generalizations of cumulative reasoning system C and cumulative reasoning system with loop CL to conceptual setting. We also generalize cumulative models, cumulative ordered models, and preferential models to conceptual setting and show the soundness and completeness results for these models.
AgentGym: Evolving Large Language Model-based Agents across Diverse Environments
Jun 06, 2024



Building generalist agents that can handle diverse tasks and evolve themselves across different environments is a long-term goal in the AI community. Large language models (LLMs) are considered a promising foundation to build such agents due to their generalized capabilities. Current approaches either have LLM-based agents imitate expert-provided trajectories step-by-step, requiring human supervision, which is hard to scale and limits environmental exploration; or they let agents explore and learn in isolated environments, resulting in specialist agents with limited generalization. In this paper, we take the first step towards building generally-capable LLM-based agents with self-evolution ability. We identify a trinity of ingredients: 1) diverse environments for agent exploration and learning, 2) a trajectory set to equip agents with basic capabilities and prior knowledge, and 3) an effective and scalable evolution method. We propose AgentGym, a new framework featuring a variety of environments and tasks for broad, real-time, uni-format, and concurrent agent exploration. AgentGym also includes a database with expanded instructions, a benchmark suite, and high-quality trajectories across environments. Next, we propose a novel method, AgentEvol, to investigate the potential of agent self-evolution beyond previously seen data across tasks and environments. Experimental results show that the evolved agents can achieve results comparable to SOTA models. We release the AgentGym suite, including the platform, dataset, benchmark, checkpoints, and algorithm implementations. The AgentGym suite is available on https://github.com/WooooDyy/AgentGym.
Self-Demos: Eliciting Out-of-Demonstration Generalizability in Large Language Models
Apr 01, 2024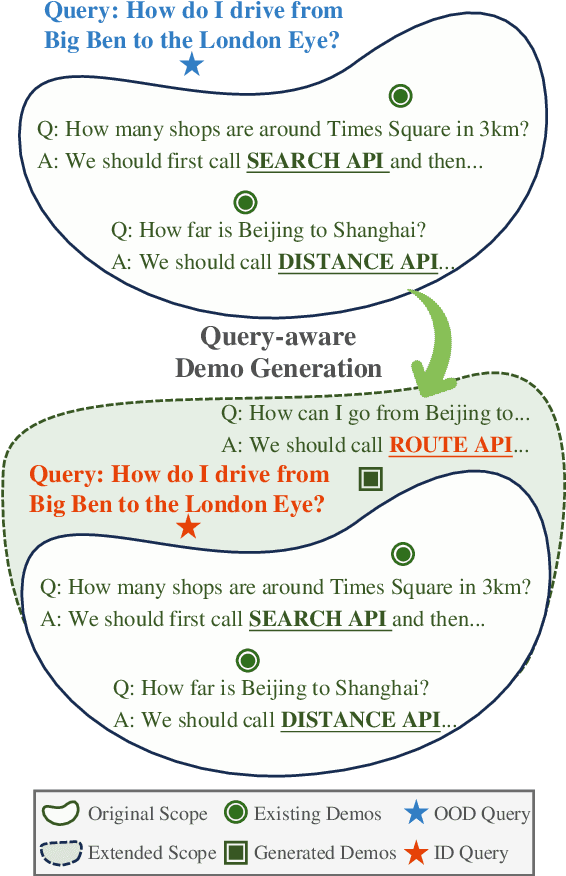



Large language models (LLMs) have shown promising abilities of in-context learning (ICL), adapting swiftly to new tasks with only few-shot demonstrations. However, current few-shot methods heavily depend on high-quality, query-specific demos, which are often lacking. When faced with out-of-demonstration (OOD) queries, methods that rely on hand-crafted demos or external retrievers might fail. To bridge the gap between limited demos and OOD queries, we propose Self-Demos, a novel prompting method that elicits the inherent generalizability in LLMs by query-aware demo generation. The generated demos strategically interpolate between existing demos and the given query, transforming the query from OOD to ID. To evaluate the effectiveness of our approach, we manually constructed OOD-Toolset, a dataset in the tool-using scenario with over 300 real-world APIs and 1000 instances, each consisting of three tool-use cases as demos and an OOD query. Thorough experiments on our dataset and two public math benchmarks have shown that our method can outperform state-of-the-art baselines in the OOD setting. Moreover, we conduct a range of analyses to validate Self-Demos's generalization and provide more insights.