 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongAV-Compass: Towards Unified Evaluation of Minute-Scale Audio-Visual Generation Across T2AV, I2AV, and V2AV
May 25, 2026Audio-visual generation is rapidly advancing from short clips to minute-long content, while existing evaluation protocols remain largely confined to short-form settings. Existing benchmarks primarily focus on 5--10 second text-conditioned generation and rarely support unified evaluation across text, image, and video conditioning modalities. Moreover, they provide limited insight into how identity consistency, narrative coherence, and audio-visual alignment degrade over extended temporal horizons. To bridge this gap, we introduce LongAV-Compass, a systematic benchmark for minute-long audio-visual generation. LongAV-Compass contains 284 curated test cases spanning text-to-audio-video (T2AV), image-to-audio-video (I2AV), and video-to-audio-video (V2AV), organized by application scenario and generation complexity. The benchmark combines taxonomy-guided benchmark construction with a unified evaluation framework that integrates MLLM-assisted assessment with complementary perceptual and multimodal metrics, including DINO-v2, ArcFace, CLIP, and ImageBind. The framework evaluates more than 20 fine-grained dimensions covering within-segment quality, cross-segment consistency, global narrative coherence, semantic alignment, and audio-visual synchronization. Through experiments on 11 representative models together with human-alignment validation, LongAV-Compass provides a diagnostic testbed for analyzing the limitations of current systems in sustaining coherent, semantically aligned, and temporally consistent minute-scale audio-visual generation across diverse input modalities.
Can LLMs Generate Reliable Test Case Generators? A Study on Competition-Level Programming Problems
Jun 07, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities in code generation, capable of tackling complex tasks during inference. However, the extent to which LLMs can be utilized for code checking or debugging through test case generation remains largely unexplored. We investigate this problem from the perspective of competition-level programming (CP) programs and propose TCGBench, a Benchmark for (LLM generation of) Test Case Generators. This benchmark comprises two tasks, aimed at studying the capabilities of LLMs in (1) generating valid test case generators for a given CP problem, and further (2) generating targeted test case generators that expose bugs in human-written code. Experimental results indicate that while state-of-the-art LLMs can generate valid test case generators in most cases, most LLMs struggle to generate targeted test cases that reveal flaws in human code effectively. Especially, even advanced reasoning models (e.g., o3-mini) fall significantly short of human performance in the task of generating targeted generators. Furthermore, we construct a high-quality, manually curated dataset of instructions for generating targeted generators. Analysis demonstrates that the performance of LLMs can be enhanced with the aid of this dataset, by both prompting and fine-tuning.
Enhancing LLM Reasoning via Critique Models with Test-Time and Training-Time Supervision
Nov 25, 2024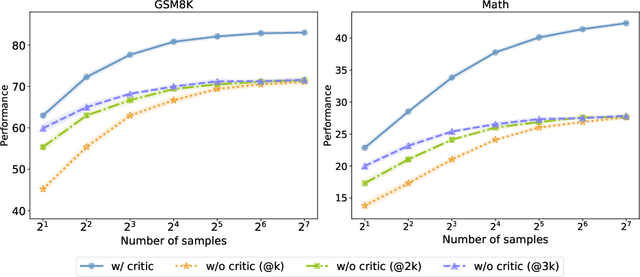

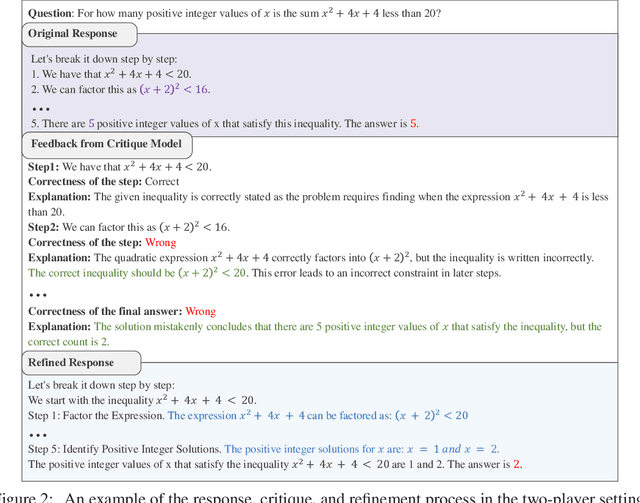

Training large language models (LLMs) to spend more time thinking and reflection before responding is crucial for effectively solving complex reasoning tasks in fields such as science, coding, and mathematics. However, the effectiveness of mechanisms like self-reflection and self-correction depends on the model's capacity to accurately assess its own performance, which can be limited by factors such as initial accuracy, question difficulty, and the lack of external feedback. In this paper, we delve into a two-player paradigm that separates the roles of reasoning and critique models, where the critique model provides step-level feedback to supervise the reasoning (actor) model during both test-time and train-time. We first propose AutoMathCritique, an automated and scalable framework for collecting critique data, resulting in a dataset of $76,321$ responses paired with step-level feedback. Fine-tuning language models with this dataset enables them to generate natural language feedback for mathematical reasoning. We demonstrate that the critique models consistently improve the actor's performance on difficult queries at test-time, especially when scaling up inference-time computation. Motivated by these findings, we introduce the critique-based supervision to the actor's self-training process, and propose a critique-in-the-loop self-improvement method. Experiments show that the method improves the actor's exploration efficiency and solution diversity, especially on challenging queries, leading to a stronger reasoning model. Lastly, we take the preliminary step to explore training self-talk reasoning models via critique supervision and showcase its potential. Our code and datasets are at \href{https://mathcritique.github.io/}{https://mathcritique.github.io/}.
A Time Series is Worth Five Experts: Heterogeneous Mixture of Experts for Traffic Flow Prediction
Sep 26, 2024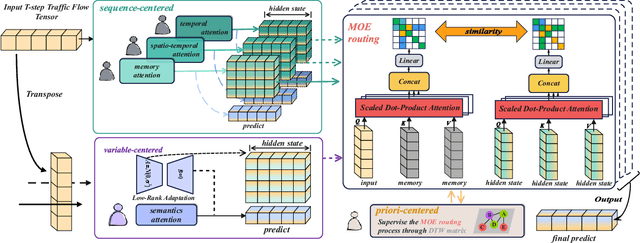
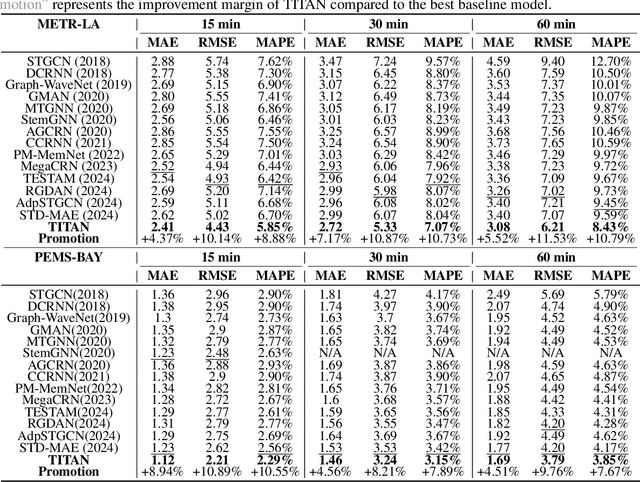
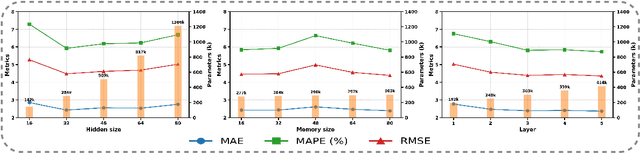
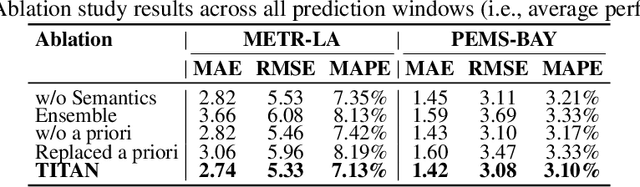
Accurate traffic prediction faces significant challenges, necessitating a deep understanding of both temporal and spatial cues and their complex interactions across multiple variables. Recent advancements in traffic prediction systems are primarily due to the development of complex sequence-centric models. However, existing approaches often embed multiple variables and spatial relationships at each time step, which may hinder effective variable-centric learning, ultimately leading to performance degradation in traditional traffic prediction tasks. To overcome these limitations, we introduce variable-centric and prior knowledge-centric modeling techniques. Specifically, we propose a Heterogeneous Mixture of Experts (TITAN) model for traffic flow prediction. TITAN initially consists of three experts focused on sequence-centric modeling. Then, designed a low-rank adaptive method, TITAN simultaneously enables variable-centric modeling. Furthermore, we supervise the gating process using a prior knowledge-centric modeling strategy to ensure accurate routing. Experiments on two public traffic network datasets, METR-LA and PEMS-BAY, demonstrate that TITAN effectively captures variable-centric dependencies while ensuring accurate routing. Consequently, it achieves improvements in all evaluation metrics, ranging from approximately 4.37\% to 11.53\%, compared to previous state-of-the-art (SOTA) models. The code is open at \href{https://github.com/sqlcow/TITAN}{https://github.com/sqlcow/TITAN}.