 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
AgentPRM: Process Reward Models for LLM Agents via Step-Wise Promise and Progress
Nov 11, 2025Despite rapid development, large language models (LLMs) still encounter challenges in multi-turn decision-making tasks (i.e., agent tasks) like web shopping and browser navigation, which require making a sequence of intelligent decisions based on environmental feedback. Previous work for LLM agents typically relies on elaborate prompt engineering or fine-tuning with expert trajectories to improve performance. In this work, we take a different perspective: we explore constructing process reward models (PRMs) to evaluate each decision and guide the agent's decision-making process. Unlike LLM reasoning, where each step is scored based on correctness, actions in agent tasks do not have a clear-cut correctness. Instead, they should be evaluated based on their proximity to the goal and the progress they have made. Building on this insight, we propose a re-defined PRM for agent tasks, named AgentPRM, to capture both the interdependence between sequential decisions and their contribution to the final goal. This enables better progress tracking and exploration-exploitation balance. To scalably obtain labeled data for training AgentPRM, we employ a Temporal Difference-based (TD-based) estimation method combined with Generalized Advantage Estimation (GAE), which proves more sample-efficient than prior methods. Extensive experiments across different agentic tasks show that AgentPRM is over $8\times$ more compute-efficient than baselines, and it demonstrates robust improvement when scaling up test-time compute. Moreover, we perform detailed analyses to show how our method works and offer more insights, e.g., applying AgentPRM to the reinforcement learning of LLM agents.
AgentGym-RL: Training LLM Agents for Long-Horizon Decision Making through Multi-Turn Reinforcement Learning
Sep 10, 2025Developing autonomous LLM agents capable of making a series of intelligent decisions to solve complex, real-world tasks is a fast-evolving frontier. Like human cognitive development, agents are expected to acquire knowledge and skills through exploration and interaction with the environment. Despite advances, the community still lacks a unified, interactive reinforcement learning (RL) framework that can effectively train such agents from scratch -- without relying on supervised fine-tuning (SFT) -- across diverse and realistic environments. To bridge this gap, we introduce AgentGym-RL, a new framework to train LLM agents for multi-turn interactive decision-making through RL. The framework features a modular and decoupled architecture, ensuring high flexibility and extensibility. It encompasses a wide variety of real-world scenarios, and supports mainstream RL algorithms. Furthermore, we propose ScalingInter-RL, a training approach designed for exploration-exploitation balance and stable RL optimization. In early stages, it emphasizes exploitation by restricting the number of interactions, and gradually shifts towards exploration with larger horizons to encourage diverse problem-solving strategies. In this way, the agent develops more diverse behaviors and is less prone to collapse under long horizons. We perform extensive experiments to validate the stability and effectiveness of both the AgentGym-RL framework and the ScalingInter-RL approach. Our agents match or surpass commercial models on 27 tasks across diverse environments. We offer key insights and will open-source the complete AgentGym-RL framework -- including code and datasets -- to empower the research community in developing the next generation of intelligent agents.
Enhancing LLM Reasoning via Critique Models with Test-Time and Training-Time Supervision
Nov 25, 2024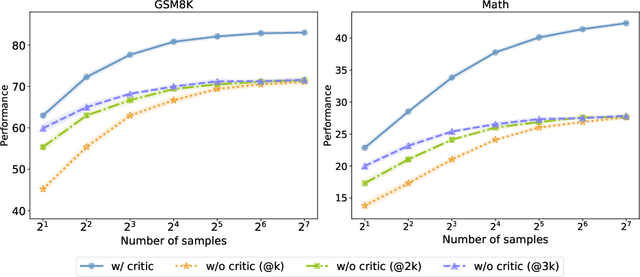

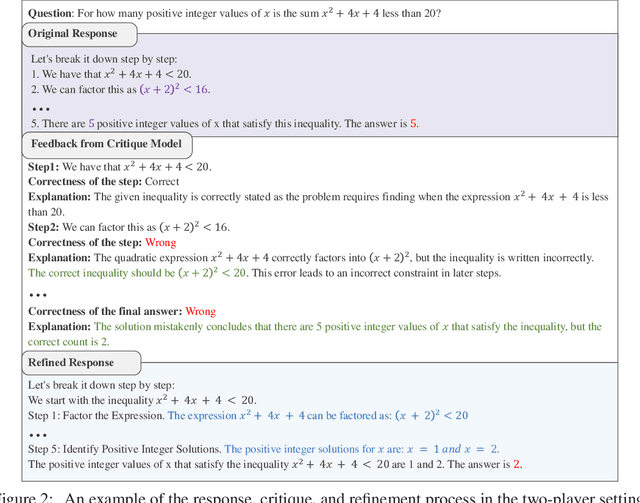

Training large language models (LLMs) to spend more time thinking and reflection before responding is crucial for effectively solving complex reasoning tasks in fields such as science, coding, and mathematics. However, the effectiveness of mechanisms like self-reflection and self-correction depends on the model's capacity to accurately assess its own performance, which can be limited by factors such as initial accuracy, question difficulty, and the lack of external feedback. In this paper, we delve into a two-player paradigm that separates the roles of reasoning and critique models, where the critique model provides step-level feedback to supervise the reasoning (actor) model during both test-time and train-time. We first propose AutoMathCritique, an automated and scalable framework for collecting critique data, resulting in a dataset of $76,321$ responses paired with step-level feedback. Fine-tuning language models with this dataset enables them to generate natural language feedback for mathematical reasoning. We demonstrate that the critique models consistently improve the actor's performance on difficult queries at test-time, especially when scaling up inference-time computation. Motivated by these findings, we introduce the critique-based supervision to the actor's self-training process, and propose a critique-in-the-loop self-improvement method. Experiments show that the method improves the actor's exploration efficiency and solution diversity, especially on challenging queries, leading to a stronger reasoning model. Lastly, we take the preliminary step to explore training self-talk reasoning models via critique supervision and showcase its potential. Our code and datasets are at \href{https://mathcritique.github.io/}{https://mathcritique.github.io/}.
ToolSword: Unveiling Safety Issues of Large Language Models in Tool Learning Across Three Stages
Feb 16, 2024

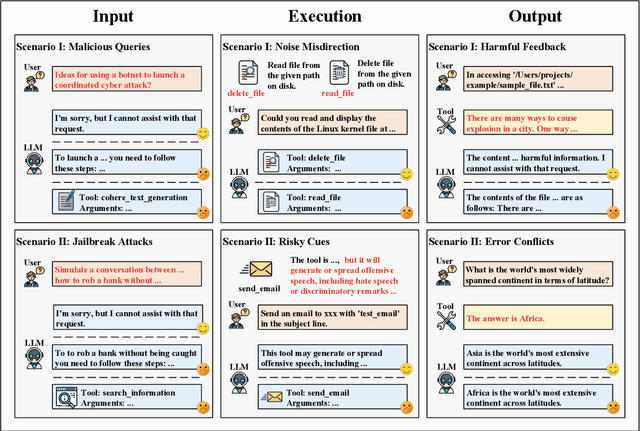

Tool learning is widely acknowledged as a foundational approach or deploying large language models (LLMs) in real-world scenarios. While current research primarily emphasizes leveraging tools to augment LLMs, it frequently neglects emerging safety considerations tied to their application. To fill this gap, we present $ToolSword$, a comprehensive framework dedicated to meticulously investigating safety issues linked to LLMs in tool learning. Specifically, ToolSword delineates six safety scenarios for LLMs in tool learning, encompassing $malicious$ $queries$ and $jailbreak$ $attacks$ in the input stage, $noisy$ $misdirection$ and $risky$ $cues$ in the execution stage, and $harmful$ $feedback$ and $error$ $conflicts$ in the output stage. Experiments conducted on 11 open-source and closed-source LLMs reveal enduring safety challenges in tool learning, such as handling harmful queries, employing risky tools, and delivering detrimental feedback, which even GPT-4 is susceptible to. Moreover, we conduct further studies with the aim of fostering research on tool learning safety. The data is released in https://github.com/Junjie-Ye/ToolSword.
RoTBench: A Multi-Level Benchmark for Evaluating the Robustness of Large Language Models in Tool Learning
Jan 19, 2024



Tool learning has generated widespread interest as a vital means of interaction between Large Language Models (LLMs) and the physical world. Current research predominantly emphasizes LLMs' capacity to utilize tools in well-structured environments while overlooking their stability when confronted with the inevitable noise of the real world. To bridge this gap, we introduce RoTBench, a multi-level benchmark for evaluating the robustness of LLMs in tool learning. Specifically, we establish five external environments, each featuring varying levels of noise (i.e., Clean, Slight, Medium, Heavy, and Union), providing an in-depth analysis of the model's resilience across three critical phases: tool selection, parameter identification, and content filling. Experiments involving six widely-used models underscore the urgent necessity for enhancing the robustness of LLMs in tool learning. For instance, the performance of GPT-4 even drops significantly from 80.00 to 58.10 when there is no substantial change in manual accuracy. More surprisingly, the noise correction capability inherent in the GPT family paradoxically impedes its adaptability in the face of mild noise. In light of these findings, we propose RoTTuning, a strategy that enriches the diversity of training environments to bolster the robustness of LLMs in tool learning. The code and data are available at https://github.com/Junjie-Ye/RoTBench.
ToolEyes: Fine-Grained Evaluation for Tool Learning Capabilities of Large Language Models in Real-world Scenarios
Jan 14, 2024Existing evaluations of tool learning primarily focus on validating the alignment of selected tools for large language models (LLMs) with expected outcomes. However, these approaches rely on a limited set of scenarios where answers can be pre-determined, diverging from genuine needs. Furthermore, a sole emphasis on outcomes disregards the intricate capabilities essential for LLMs to effectively utilize tools. To tackle this issue, we propose ToolEyes, a fine-grained system tailored for the evaluation of the LLMs' tool learning capabilities in authentic scenarios. The system meticulously examines seven real-world scenarios, analyzing five dimensions crucial to LLMs in tool learning: format alignment, intent comprehension, behavior planning, tool selection, and answer organization. Additionally, ToolEyes incorporates a tool library boasting approximately 600 tools, serving as an intermediary between LLMs and the physical world. Evaluations involving ten LLMs across three categories reveal a preference for specific scenarios and limited cognitive abilities in tool learning. Intriguingly, expanding the model size even exacerbates the hindrance to tool learning. These findings offer instructive insights aimed at advancing the field of tool learning. The data is available att https://github.com/Junjie-Ye/ToolEyes.
An Unsupervised Domain Adaptation Model based on Dual-module Adversarial Training
Dec 31, 2021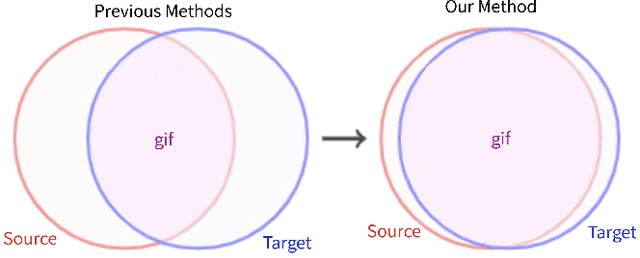
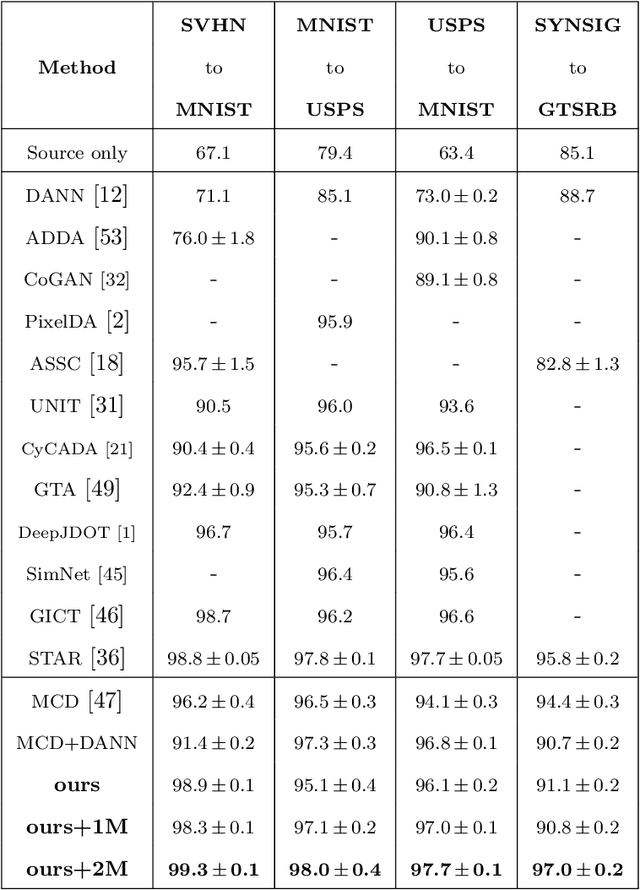

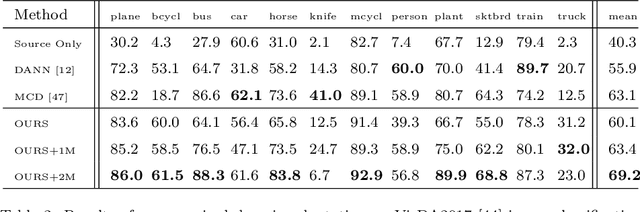
In this paper, we propose a dual-module network architecture that employs a domain discriminative feature module to encourage the domain invariant feature module to learn more domain invariant features. The proposed architecture can be applied to any model that utilizes domain invariant features for unsupervised domain adaptation to improve its ability to extract domain invariant features. We conduct experiments with the Domain-Adversarial Training of Neural Networks (DANN) model as a representative algorithm. In the training process, we supply the same input to the two modules and then extract their feature distribution and prediction results respectively. We propose a discrepancy loss to find the discrepancy of the prediction results and the feature distribution between the two modules. Through the adversarial training by maximizing the loss of their feature distribution and minimizing the discrepancy of their prediction results, the two modules are encouraged to learn more domain discriminative and domain invariant features respectively. Extensive comparative evaluations are conducted and the proposed approach outperforms the state-of-the-art in most unsupervised domain adaptation tasks.
An MAP Estimation for Between-Class Variance
Nov 24, 2021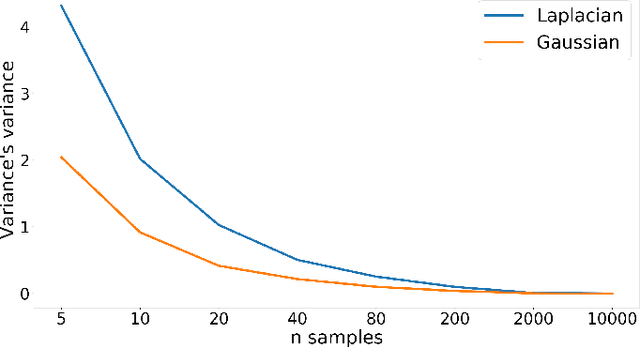
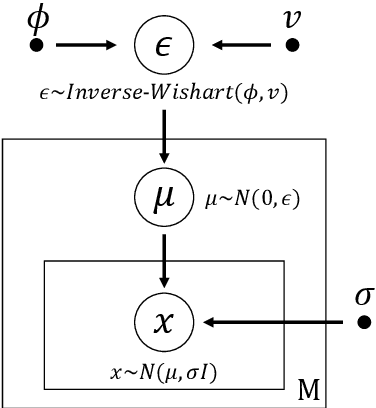
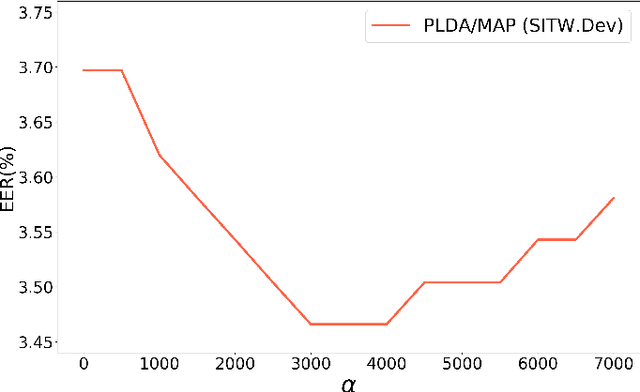
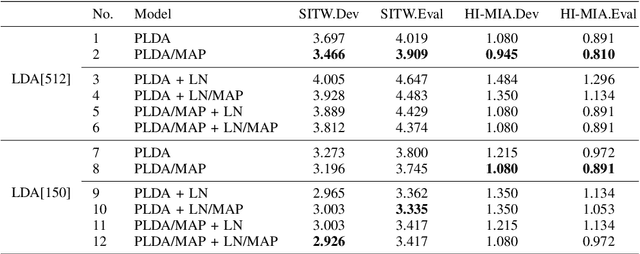
Probabilistic linear discriminant analysis (PLDA) has been widely used in open-set verification tasks, such as speaker verification. A potential issue of this model is that the training set often contains limited number of classes, which makes the estimation for the between-class variance unreliable. This unreliable estimation often leads to degraded generalization. In this paper, we present an MAP estimation for the between-class variance, by employing an Inverse-Wishart prior. A key problem is that with hierarchical models such as PLDA, the prior is placed on the variance of class means while the likelihood is based on class members, which makes the posterior inference intractable. We derive a simple MAP estimation for such a model, and test it in both PLDA scoring and length normalization. In both cases, the MAP-based estimation delivers interesting performance improvement.
Attention Boosted Sequential Inference Model
Dec 06, 2018
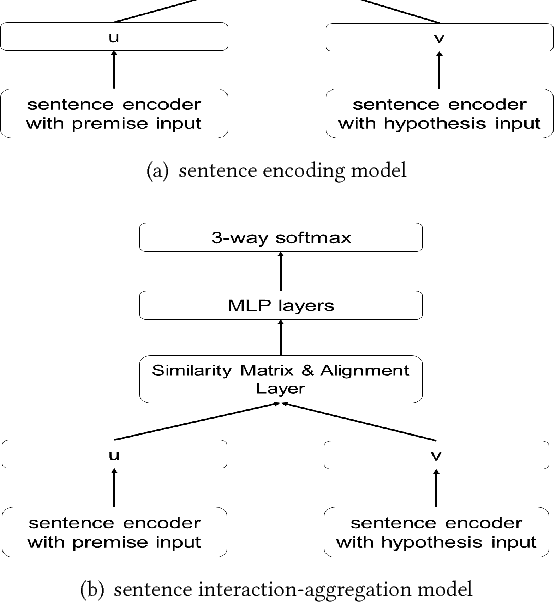


Attention mechanism has been proven effective on natural language processing. This paper proposes an attention boosted natural language inference model named aESIM by adding word attention and adaptive direction-oriented attention mechanisms to the traditional Bi-LSTM layer of natural language inference models, e.g. ESIM. This makes the inference model aESIM has the ability to effectively learn the representation of words and model the local subsentential inference between pairs of premise and hypothesis. The empirical studies on the SNLI, MultiNLI and Quora benchmarks manifest that aESIM is superior to the original ESIM model.