 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaNet: Elevation-Guided Flood Extent Mapping on Earth Imagery
Apr 27, 2024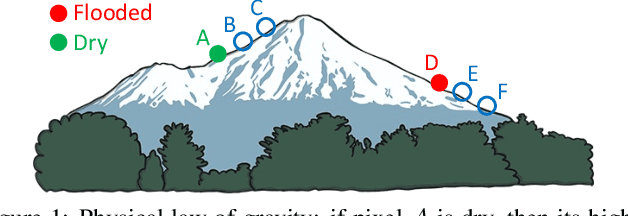
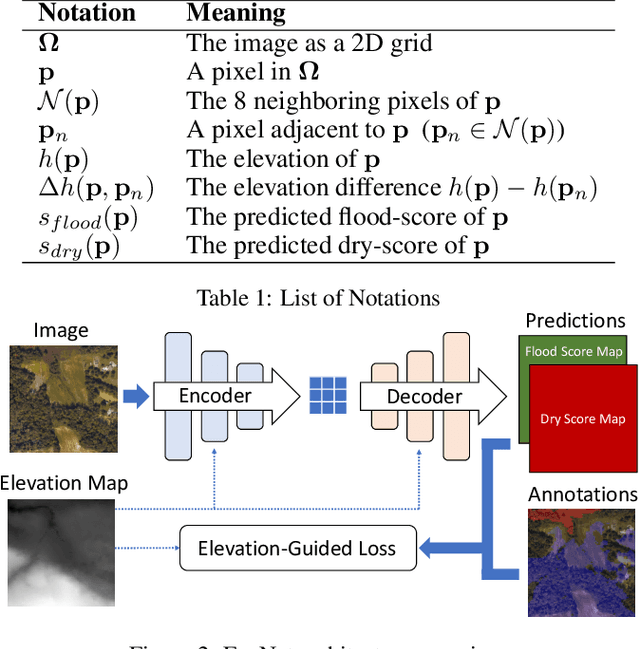
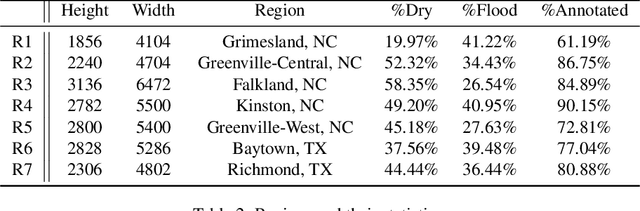
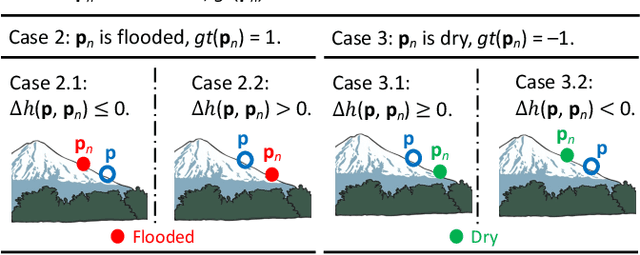
Accurate and timely mapping of flood extent from high-resolution satellite imagery plays a crucial role in disaster management such as damage assessment and relief activities. However, current state-of-the-art solutions are based on U-Net, which can-not segment the flood pixels accurately due to the ambiguous pixels (e.g., tree canopies, clouds) that prevent a direct judgement from only the spectral features. Thanks to the digital elevation model (DEM) data readily available from sources such as United States Geological Survey (USGS), this work explores the use of an elevation map to improve flood extent mapping. We propose, EvaNet, an elevation-guided segmentation model based on the encoder-decoder architecture with two novel techniques: (1) a loss function encoding the physical law of gravity that if a location is flooded (resp. dry), then its adjacent locations with a lower (resp. higher) elevation must also be flooded (resp. dry); (2) a new (de)convolution operation that integrates the elevation map by a location sensitive gating mechanism to regulate how much spectral features flow through adjacent layers. Extensive experiments show that EvaNet significantly outperforms the U-Net baselines, and works as a perfect drop-in replacement for U-Net in existing solutions to flood extent mapping.
An MAP Estimation for Between-Class Variance
Nov 24, 2021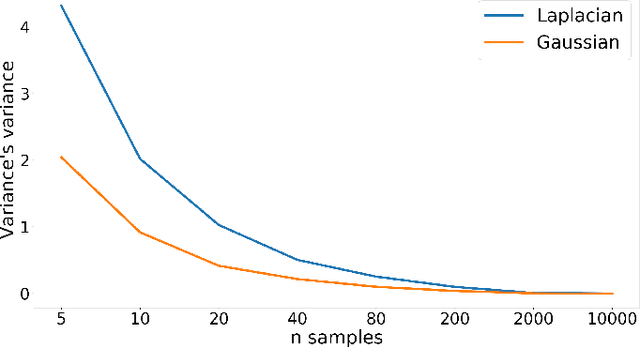
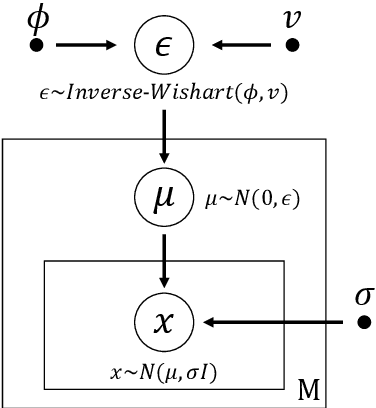
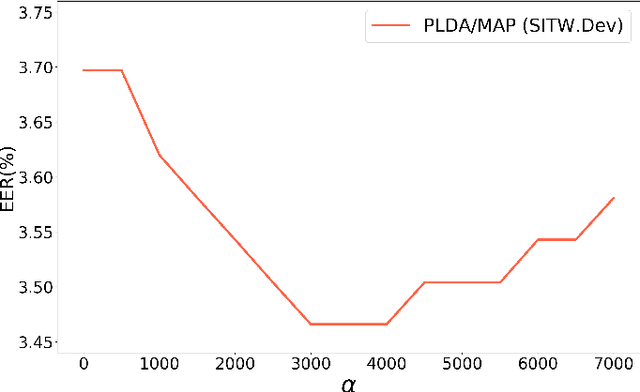
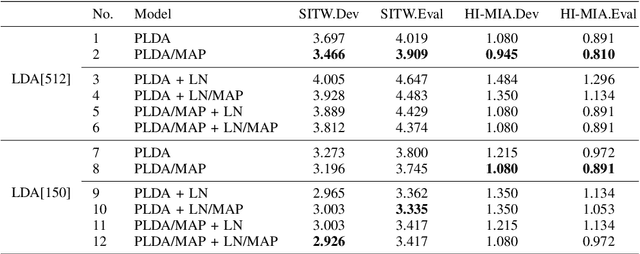
Probabilistic linear discriminant analysis (PLDA) has been widely used in open-set verification tasks, such as speaker verification. A potential issue of this model is that the training set often contains limited number of classes, which makes the estimation for the between-class variance unreliable. This unreliable estimation often leads to degraded generalization. In this paper, we present an MAP estimation for the between-class variance, by employing an Inverse-Wishart prior. A key problem is that with hierarchical models such as PLDA, the prior is placed on the variance of class means while the likelihood is based on class members, which makes the posterior inference intractable. We derive a simple MAP estimation for such a model, and test it in both PLDA scoring and length normalization. In both cases, the MAP-based estimation delivers interesting performance improvement.