 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan RL Improve Generalization of LLM Agents? An Empirical Study
Mar 12, 2026Reinforcement fine-tuning (RFT) has shown promise for training LLM agents to perform multi-turn decision-making based on environment feedback. However, most existing evaluations remain largely in-domain: training and testing are conducted in the same environment or even on the same tasks. In real-world deployment, agents may operate in unseen environments with different background knowledge, observation spaces, and action interfaces. To characterize the generalization profile of RFT under such shifts, we conduct a systematic study along three axes: (1) within-environment generalization across task difficulty, (2) cross-environment transfer to unseen environments, and (3) sequential multi-environment training to quantify transfer and forgetting. Our results show that RFT generalizes well across task difficulty within an environment, but exhibits weaker transfer to unseen environments, which correlates with shifts in both semantic priors and observation/action interfaces. In contrast, sequential training yields promising downstream gains with minimal upstream forgetting, and mixture training across environments improves the overall balance. We further provide detailed analyses and deeper insights, and hope our work helps the community develop and deploy generalizable LLM agents.
LongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
Developing a Fundamental Diagram for Urban Air Mobility Based on Physical Experiments
Dec 24, 2025Urban Air Mobility (UAM) is an emerging application of unmanned aerial vehicles (UAVs) that promises to reduce travel time and alleviate congestion in urban transportation systems. As drone density increases, UAM operations are expected to experience congestion similar to that in ground traffic. However, the fundamental characteristics of UAM traffic flow, particularly under real-world operating conditions, remain poorly understood. This study proposes a general framework for constructing the fundamental diagram (FD) of UAM traffic by integrating theoretical analysis with physical experiments. To the best of our knowledge, this is the first study to derive a UAM FD using real-world physical test data. On the theoretical side, we design two drone control laws for collision avoidance and develop simulation-based traffic generation methods to produce diverse UAM traffic scenarios. Based on Edie's definition, traffic flow theory is then applied to construct the FD and characterize the macroscopic properties of UAM traffic. To account for real-world disturbances and modeling uncertainties, we further conduct physical experiments on a reduced-scale testbed using Bitcraze Crazyflie drones. Both simulation and physical test trajectory data are collected and organized into the UAMTra2Flow dataset, which is analyzed using the proposed framework. Preliminary results indicate that classical FD structures for ground transportation are also applicable to UAM systems. Notably, FD curves obtained from physical experiments exhibit deviations from simulation-based results, highlighting the importance of experimental validation. Finally, results from the reduced-scale testbed are scaled to realistic operating conditions to provide practical insights for future UAM traffic systems. The dataset and code for this paper are publicly available at https://github.com/CATS-Lab/UAM-FD.
Counteracting Matthew Effect in Self-Improvement of LVLMs through Head-Tail Re-balancing
Oct 30, 2025Self-improvement has emerged as a mainstream paradigm for advancing the reasoning capabilities of large vision-language models (LVLMs), where models explore and learn from successful trajectories iteratively. However, we identify a critical issue during this process: the model excels at generating high-quality trajectories for simple queries (i.e., head data) but struggles with more complex ones (i.e., tail data). This leads to an imbalanced optimization that drives the model to prioritize simple reasoning skills, while hindering its ability to tackle more complex reasoning tasks. Over iterations, this imbalance becomes increasingly pronounced--a dynamic we term the "Matthew effect"--which ultimately hinders further model improvement and leads to performance bottlenecks. To counteract this challenge, we introduce four efficient strategies from two perspectives: distribution-reshaping and trajectory-resampling, to achieve head-tail re-balancing during the exploration-and-learning self-improvement process. Extensive experiments on Qwen2-VL-7B-Instruct and InternVL2.5-4B models across visual reasoning tasks demonstrate that our methods consistently improve visual reasoning capabilities, outperforming vanilla self-improvement by 3.86 points on average.
MUA-RL: Multi-turn User-interacting Agent Reinforcement Learning for agentic tool use
Aug 26, 2025With the recent rapid advancement of Agentic Intelligence, agentic tool use in LLMs has become increasingly important. During multi-turn interactions between agents and users, the dynamic, uncertain, and stochastic nature of user demands poses significant challenges to the agent's tool invocation capabilities. Agents are no longer expected to simply call tools to deliver a result; rather, they must iteratively refine their understanding of user needs through communication while simultaneously invoking tools to resolve user queries. Existing reinforcement learning (RL) approaches for tool use lack the integration of genuinely dynamic users during the RL training process. To bridge this gap, we introduce MUA-RL (Multi-turn User-interacting Agent Reinforcement Learning for agentic tool use), a novel reinforcement learning framework that, for the first time in the field of agentic tool use, integrates LLM-simulated users into the reinforcement learning loop. MUA-RL aims to enable autonomous learning of models to communicate with users efficiently and use various tools to solve practical problems in dynamic multi-turn interactions. Evaluations are done on several multi-turn tool-using benchmarks (see Figure 1). Specifically, MUA-RL-32B achieves 67.3 on TAU2 Retail, 45.4 on TAU2 Airline, 28.3 on TAU2 Telecom, 28.4 on BFCL-V3 Multi Turn, and 82.5 on ACEBench Agent -- outperforming or matching the performance of larger open-source models such as DeepSeek-V3-0324 and Qwen3-235B-A22B in non-thinking settings.
Enhancing LLM Reasoning via Critique Models with Test-Time and Training-Time Supervision
Nov 25, 2024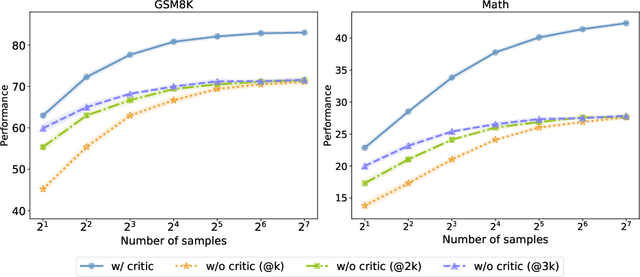

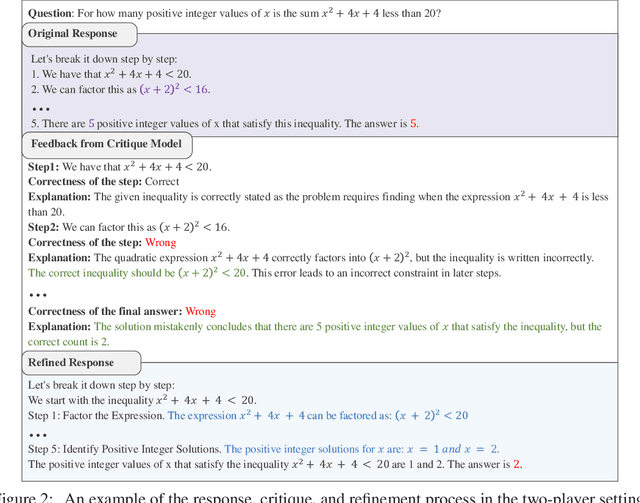

Training large language models (LLMs) to spend more time thinking and reflection before responding is crucial for effectively solving complex reasoning tasks in fields such as science, coding, and mathematics. However, the effectiveness of mechanisms like self-reflection and self-correction depends on the model's capacity to accurately assess its own performance, which can be limited by factors such as initial accuracy, question difficulty, and the lack of external feedback. In this paper, we delve into a two-player paradigm that separates the roles of reasoning and critique models, where the critique model provides step-level feedback to supervise the reasoning (actor) model during both test-time and train-time. We first propose AutoMathCritique, an automated and scalable framework for collecting critique data, resulting in a dataset of $76,321$ responses paired with step-level feedback. Fine-tuning language models with this dataset enables them to generate natural language feedback for mathematical reasoning. We demonstrate that the critique models consistently improve the actor's performance on difficult queries at test-time, especially when scaling up inference-time computation. Motivated by these findings, we introduce the critique-based supervision to the actor's self-training process, and propose a critique-in-the-loop self-improvement method. Experiments show that the method improves the actor's exploration efficiency and solution diversity, especially on challenging queries, leading to a stronger reasoning model. Lastly, we take the preliminary step to explore training self-talk reasoning models via critique supervision and showcase its potential. Our code and datasets are at \href{https://mathcritique.github.io/}{https://mathcritique.github.io/}.
Mitigating Tail Narrowing in LLM Self-Improvement via Socratic-Guided Sampling
Nov 01, 2024Self-improvement methods enable large language models (LLMs) to generate solutions themselves and iteratively train on filtered, high-quality rationales. This process proves effective and reduces the reliance on human supervision in LLMs' reasoning, but the performance soon plateaus. We delve into the process and find that models tend to over-sample on easy queries and under-sample on queries they have yet to master. As iterations proceed, this imbalance in sampling is exacerbated, leading to a long-tail distribution where solutions to difficult queries almost diminish. This phenomenon limits the performance gain of self-improving models. A straightforward solution is brute-force sampling to balance the distribution, which significantly raises computational costs. In this paper, we introduce Guided Self-Improvement (GSI), a strategy aimed at improving the efficiency of sampling challenging heavy-tailed data. It leverages Socratic-style guidance signals to help LLM reasoning with complex queries, reducing the exploration effort and minimizing computational overhead. Experiments on four models across diverse mathematical tasks show that GSI strikes a balance between performance and efficiency, while also being effective on held-out tasks.