 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMANTA: A Large-Scale Multi-View and Visual-Text Anomaly Detection Dataset for Tiny Objects
Paper and Code
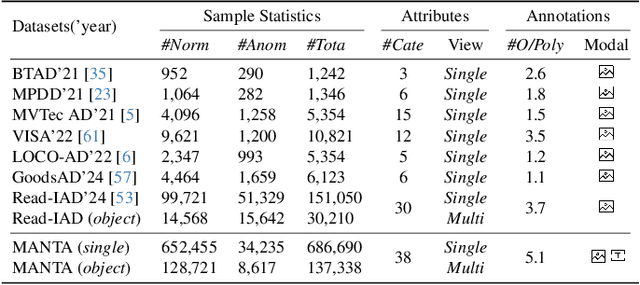
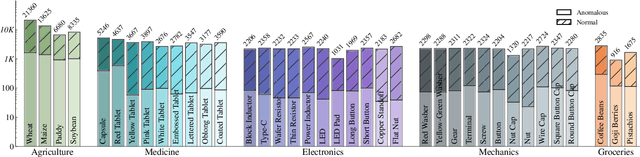

We present MANTA, a visual-text anomaly detection dataset for tiny objects. The visual component comprises over 137.3K images across 38 object categories spanning five typical domains, of which 8.6K images are labeled as anomalous with pixel-level annotations. Each image is captured from five distinct viewpoints to ensure comprehensive object coverage. The text component consists of two subsets: Declarative Knowledge, including 875 words that describe common anomalies across various domains and specific categories, with detailed explanations for < what, why, how>, including causes and visual characteristics; and Constructivist Learning, providing 2K multiple-choice questions with varying levels of difficulty, each paired with images and corresponded answer explanations. We also propose a baseline for visual-text tasks and conduct extensive benchmarking experiments to evaluate advanced methods across different settings, highlighting the challenges and efficacy of our dataset.