 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Robustness of Epoch-Greedy in Multi-Agent Contextual Bandit Mechanisms
Paper and Code
Jul 15, 2023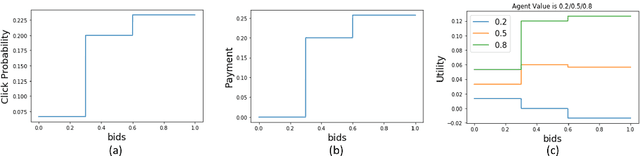
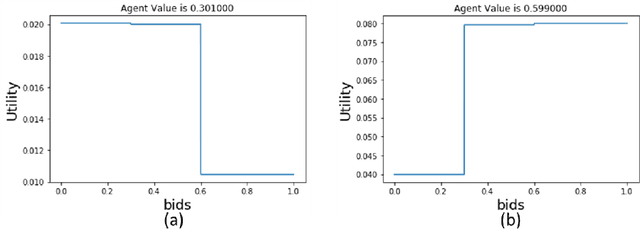
Efficient learning in multi-armed bandit mechanisms such as pay-per-click (PPC) auctions typically involves three challenges: 1) inducing truthful bidding behavior (incentives), 2) using personalization in the users (context), and 3) circumventing manipulations in click patterns (corruptions). Each of these challenges has been studied orthogonally in the literature; incentives have been addressed by a line of work on truthful multi-armed bandit mechanisms, context has been extensively tackled by contextual bandit algorithms, while corruptions have been discussed via a recent line of work on bandits with adversarial corruptions. Since these challenges co-exist, it is important to understand the robustness of each of these approaches in addressing the other challenges, provide algorithms that can handle all simultaneously, and highlight inherent limitations in this combination. In this work, we show that the most prominent contextual bandit algorithm, $\epsilon$-greedy can be extended to handle the challenges introduced by strategic arms in the contextual multi-arm bandit mechanism setting. We further show that $\epsilon$-greedy is inherently robust to adversarial data corruption attacks and achieves performance that degrades linearly with the amount of corruption.