 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Memorization Behavior of LLMs in Generative Recommendation: Observations, Implications, and Training Strategies
Jun 17, 2026Generative recommendation (GR) has emerged as a promising direction for recommender systems. Recently, large language models (LLMs) have been increasingly adopted for GR, as their rich pretrained knowledge is expected to help them generalize beyond common user behavior patterns that traditional memorization-oriented baselines can capture. However, existing LLM-based GR works largely ignore LLMs' well-known tendency to memorize, which, if present in LLMs fine-tuned for GR, would restrict their utilization of pretrained knowledge. In this work, we investigate this concern by examining one-hop memorization, where a model recommends items that are direct successors of items in the training data. We show that LLMs do this more than non-LLM-based GR models-in fact, the vast majority of their gains over GR baselines are actually on users whose target items can be predicted through one-hop memorization. We intuit that improving performance on the remaining users requires LLMs to learn richer item-item relations beyond one-hop transitions. To achieve this, we propose IIRG, a novel training strategy that teaches LLMs to capture: (1) collaborative relations derived from item co-occurrences across multiple hops in user sequences, and (2) semantic relations among items with similar themes, both of which can serve as useful recommendation signals. We show that IIRG significantly improves over LLMs trained solely with standard next-item prediction, with especially large gains for users whose test items are not covered by train-time one-hop transitions.
Implicit Reasoning for Large Language Model-based Generative Recommendation
Jun 12, 2026Large Language Models (LLMs) are increasingly adopted as backbones for Generative Recommendation (GR), promising access to pretrained world knowledge. Yet reliably invoking this knowledge for GR remains poorly understood. A key obstacle is that LLM-based GR typically represents items with Semantic IDs (SIDs), disrupting LLMs' natural-language reasoning interface because these tokens are unseen by the LLM during pretraining. Existing approaches address this with expensive multi-stage pipelines that ground SIDs and elicit explicit rationales, but offer limited insight into when and why each stage is necessary. In this work, we systematically decompose explicit reasoning training pipelines for LLM-based GR, revealing three key limitations: weakened world-knowledge verbalization, misalignment between SID and natural-language token embedding spaces, and sensitivity to rationale quality, all of which hurt explicit reasoning performance. To circumvent these issues, we propose PauseRec, a lightweight implicit reasoning paradigm tailored for GR. PauseRec is exceptionally practical, avoiding costly reasoning trace acquisition and reasoning alignment training, leading to a multitude of benefits: (1) it outperforms standard explicit CoT methods by up to 6.22%, (2) it reduces training cost by up to 65% GPU hours, and (3) it speeds up inference by up to 71.3%. These results position PauseRec as a lightweight alternative to explicit rationale generation, enabling more effective and efficient LLM-based GR.
CoSearch: Joint Training of Reasoning and Document Ranking via Reinforcement Learning for Agentic Search
Apr 21, 2026Agentic search -- the task of training agents that iteratively reason, issue queries, and synthesize retrieved information to answer complex questions -- has achieved remarkable progress through reinforcement learning (RL). However, existing approaches such as Search-R1, treat the retrieval system as a fixed tool, optimizing only the reasoning agent while the retrieval component remains unchanged. A preliminary experiment reveals that the gap between an oracle and a fixed retrieval system reaches up to +26.8% relative F1 improvement across seven QA benchmarks, suggesting that the retrieval system is a key bottleneck in scaling agentic search performance. Motivated by this finding, we propose CoSearch, a framework that jointly trains a multi-step reasoning agent and a generative document ranking model via Group Relative Policy Optimization (GRPO). To enable effective GRPO training for the ranker -- whose inputs vary across reasoning trajectories -- we introduce a semantic grouping strategy that clusters sub-queries by token-level similarity, forming valid optimization groups without additional rollouts. We further design a composite reward combining ranking quality signals with trajectory-level outcome feedback, providing the ranker with both immediate and long-term learning signals. Experiments on seven single-hop and multi-hop QA benchmarks demonstrate consistent improvements over strong baselines, with ablation studies validating each design choice. Our results show that joint training of the reasoning agent and retrieval system is both feasible and strongly performant, pointing to a key ingredient for future search agents.
Semantic IDs for Recommender Systems at Snapchat: Use Cases, Technical Challenges, and Design Choices
Apr 05, 2026Effective item identifiers (IDs) are an important component for recommender systems (RecSys) in practice, and are commonly adopted in many use cases such as retrieval and ranking. IDs can encode collaborative filtering signals within training data, such that RecSys models can extrapolate during the inference and personalize the prediction based on users' behavioral histories. Recently, Semantic IDs (SIDs) have become a trending paradigm for RecSys. In comparison to the conventional atomic ID, an SID is an ordered list of codes, derived from tokenizers such as residual quantization, applied to semantic representations commonly extracted from foundation models or collaborative signals. SIDs have drastically smaller cardinality than the atomic counterpart, and induce semantic clustering in the ID space. At Snapchat, we apply SIDs as auxiliary features for ranking models, and also explore SIDs as additional retrieval sources in different ML applications. In this paper, we discuss practical technical challenges we encountered while applying SIDs, experiments we have conducted, and design choices we have iterated to mitigate these challenges. Backed by promising offline results on both internal data and academic benchmarks as well as online A/B studies, SID variants have been launched in multiple production models with positive metrics impact.
Exploiting ID-Text Complementarity via Ensembling for Sequential Recommendation
Dec 19, 2025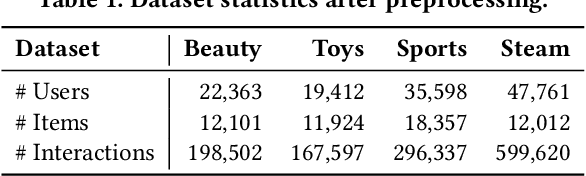
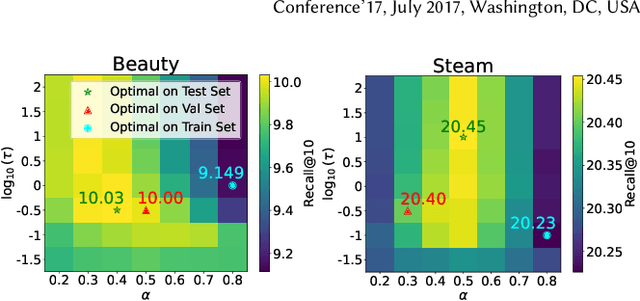
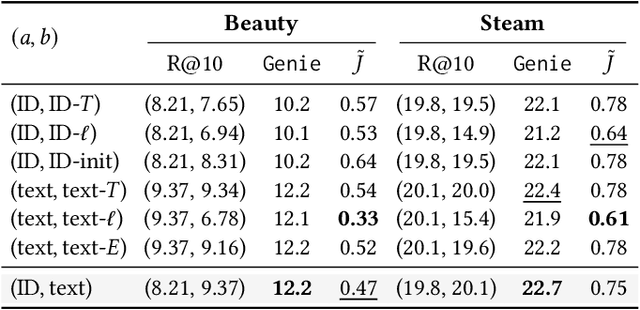
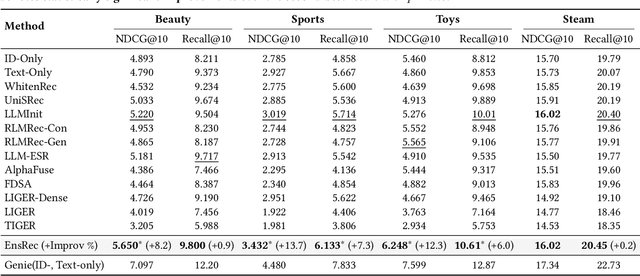
Modern Sequential Recommendation (SR) models commonly utilize modality features to represent items, motivated in large part by recent advancements in language and vision modeling. To do so, several works completely replace ID embeddings with modality embeddings, claiming that modality embeddings render ID embeddings unnecessary because they can match or even exceed ID embedding performance. On the other hand, many works jointly utilize ID and modality features, but posit that complex fusion strategies, such as multi-stage training and/or intricate alignment architectures, are necessary for this joint utilization. However, underlying both these lines of work is a lack of understanding of the complementarity of ID and modality features. In this work, we address this gap by studying the complementarity of ID- and text-based SR models. We show that these models do learn complementary signals, meaning that either should provide performance gain when used properly alongside the other. Motivated by this, we propose a new SR method that preserves ID-text complementarity through independent model training, then harnesses it through a simple ensembling strategy. Despite this method's simplicity, we show it outperforms several competitive SR baselines, implying that both ID and text features are necessary to achieve state-of-the-art SR performance but complex fusion architectures are not.
Generative Recommendation with Semantic IDs: A Practitioner's Handbook
Jul 29, 2025Generative recommendation (GR) has gained increasing attention for its promising performance compared to traditional models. A key factor contributing to the success of GR is the semantic ID (SID), which converts continuous semantic representations (e.g., from large language models) into discrete ID sequences. This enables GR models with SIDs to both incorporate semantic information and learn collaborative filtering signals, while retaining the benefits of discrete decoding. However, varied modeling techniques, hyper-parameters, and experimental setups in existing literature make direct comparisons between GR proposals challenging. Furthermore, the absence of an open-source, unified framework hinders systematic benchmarking and extension, slowing model iteration. To address this challenge, our work introduces and open-sources a framework for Generative Recommendation with semantic ID, namely GRID, specifically designed for modularity to facilitate easy component swapping and accelerate idea iteration. Using GRID, we systematically experiment with and ablate different components of GR models with SIDs on public benchmarks. Our comprehensive experiments with GRID reveal that many overlooked architectural components in GR models with SIDs substantially impact performance. This offers both novel insights and validates the utility of an open-source platform for robust benchmarking and GR research advancement. GRID is open-sourced at https://github.com/snap-research/GRID.
Revisiting Self-attention for Cross-domain Sequential Recommendation
May 27, 2025Sequential recommendation is a popular paradigm in modern recommender systems. In particular, one challenging problem in this space is cross-domain sequential recommendation (CDSR), which aims to predict future behaviors given user interactions across multiple domains. Existing CDSR frameworks are mostly built on the self-attention transformer and seek to improve by explicitly injecting additional domain-specific components (e.g. domain-aware module blocks). While these additional components help, we argue they overlook the core self-attention module already present in the transformer, a naturally powerful tool to learn correlations among behaviors. In this work, we aim to improve the CDSR performance for simple models from a novel perspective of enhancing the self-attention. Specifically, we introduce a Pareto-optimal self-attention and formulate the cross-domain learning as a multi-objective problem, where we optimize the recommendation task while dynamically minimizing the cross-domain attention scores. Our approach automates knowledge transfer in CDSR (dubbed as AutoCDSR) -- it not only mitigates negative transfer but also encourages complementary knowledge exchange among auxiliary domains. Based on the idea, we further introduce AutoCDSR+, a more performant variant with slight additional cost. Our proposal is easy to implement and works as a plug-and-play module that can be incorporated into existing transformer-based recommenders. Besides flexibility, it is practical to deploy because it brings little extra computational overheads without heavy hyper-parameter tuning. AutoCDSR on average improves Recall@10 for SASRec and Bert4Rec by 9.8% and 16.0% and NDCG@10 by 12.0% and 16.7%, respectively. Code is available at https://github.com/snap-research/AutoCDSR.
Learning Universal User Representations Leveraging Cross-domain User Intent at Snapchat
Apr 30, 2025The development of powerful user representations is a key factor in the success of recommender systems (RecSys). Online platforms employ a range of RecSys techniques to personalize user experience across diverse in-app surfaces. User representations are often learned individually through user's historical interactions within each surface and user representations across different surfaces can be shared post-hoc as auxiliary features or additional retrieval sources. While effective, such schemes cannot directly encode collaborative filtering signals across different surfaces, hindering its capacity to discover complex relationships between user behaviors and preferences across the whole platform. To bridge this gap at Snapchat, we seek to conduct universal user modeling (UUM) across different in-app surfaces, learning general-purpose user representations which encode behaviors across surfaces. Instead of replacing domain-specific representations, UUM representations capture cross-domain trends, enriching existing representations with complementary information. This work discusses our efforts in developing initial UUM versions, practical challenges, technical choices and modeling and research directions with promising offline performance. Following successful A/B testing, UUM representations have been launched in production, powering multiple use cases and demonstrating their value. UUM embedding has been incorporated into (i) Long-form Video embedding-based retrieval, leading to 2.78% increase in Long-form Video Open Rate, (ii) Long-form Video L2 ranking, with 19.2% increase in Long-form Video View Time sum, (iii) Lens L2 ranking, leading to 1.76% increase in Lens play time, and (iv) Notification L2 ranking, with 0.87% increase in Notification Open Rate.
On the Robustness of Epoch-Greedy in Multi-Agent Contextual Bandit Mechanisms
Jul 15, 2023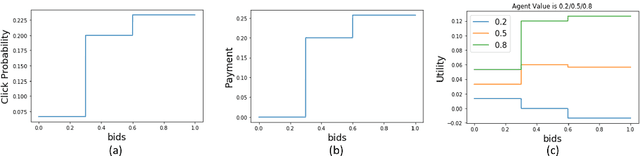
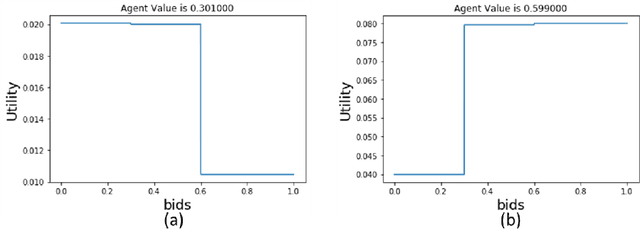
Efficient learning in multi-armed bandit mechanisms such as pay-per-click (PPC) auctions typically involves three challenges: 1) inducing truthful bidding behavior (incentives), 2) using personalization in the users (context), and 3) circumventing manipulations in click patterns (corruptions). Each of these challenges has been studied orthogonally in the literature; incentives have been addressed by a line of work on truthful multi-armed bandit mechanisms, context has been extensively tackled by contextual bandit algorithms, while corruptions have been discussed via a recent line of work on bandits with adversarial corruptions. Since these challenges co-exist, it is important to understand the robustness of each of these approaches in addressing the other challenges, provide algorithms that can handle all simultaneously, and highlight inherent limitations in this combination. In this work, we show that the most prominent contextual bandit algorithm, $\epsilon$-greedy can be extended to handle the challenges introduced by strategic arms in the contextual multi-arm bandit mechanism setting. We further show that $\epsilon$-greedy is inherently robust to adversarial data corruption attacks and achieves performance that degrades linearly with the amount of corruption.
Optimal Spend Rate Estimation and Pacing for Ad Campaigns with Budgets
Feb 04, 2022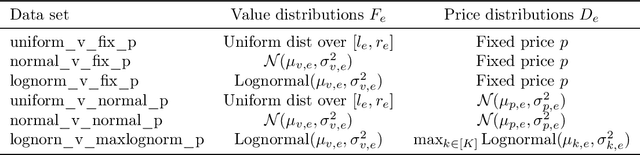
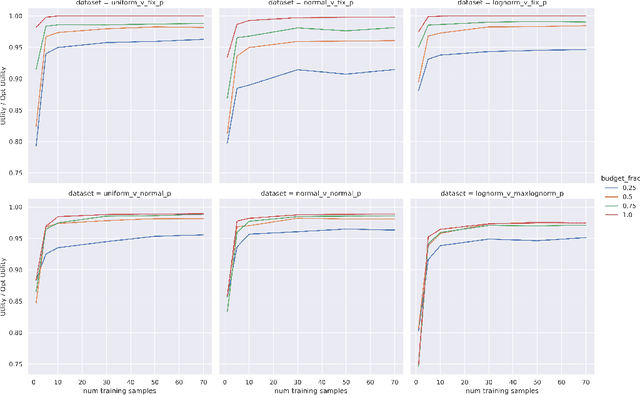
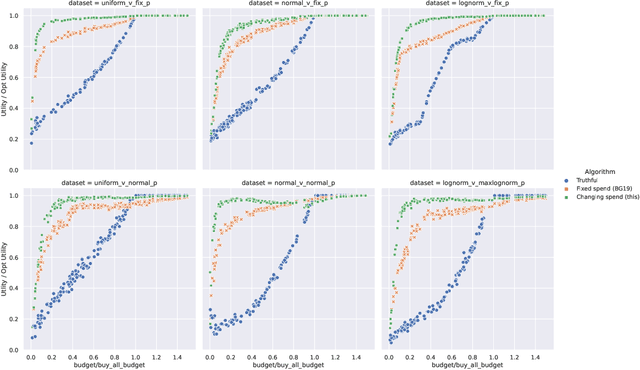
Online ad platforms offer budget management tools for advertisers that aim to maximize the number of conversions given a budget constraint. As the volume of impressions, conversion rates and prices vary over time, these budget management systems learn a spend plan (to find the optimal distribution of budget over time) and run a pacing algorithm which follows the spend plan. This paper considers two models for impressions and competition that varies with time: a) an episodic model which exhibits stationarity in each episode, but each episode can be arbitrarily different from the next, and b) a model where the distributions of prices and values change slowly over time. We present the first learning theoretic guarantees on both the accuracy of spend plans and the resulting end-to-end budget management system. We present four main results: 1) for the episodic setting we give sample complexity bounds for the spend rate prediction problem: given $n$ samples from each episode, with high probability we have $|\widehat{\rho}_e - \rho_e| \leq \tilde{O}(\frac{1}{n^{1/3}})$ where $\rho_e$ is the optimal spend rate for the episode, $\widehat{\rho}_e$ is the estimate from our algorithm, 2) we extend the algorithm of Balseiro and Gur (2017) to operate on varying, approximate spend rates and show that the resulting combined system of optimal spend rate estimation and online pacing algorithm for episodic settings has regret that vanishes in number of historic samples $n$ and the number of rounds $T$, 3) for non-episodic but slowly-changing distributions we show that the same approach approximates the optimal bidding strategy up to a factor dependent on the rate-of-change of the distributions and 4) we provide experiments showing that our algorithm outperforms both static spend plans and non-pacing across a wide variety of settings.