 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting ID-Text Complementarity via Ensembling for Sequential Recommendation
Dec 19, 2025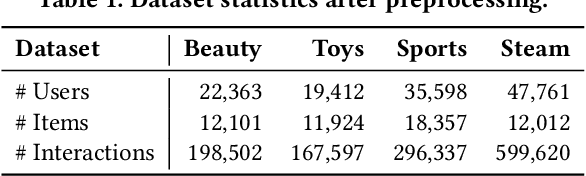
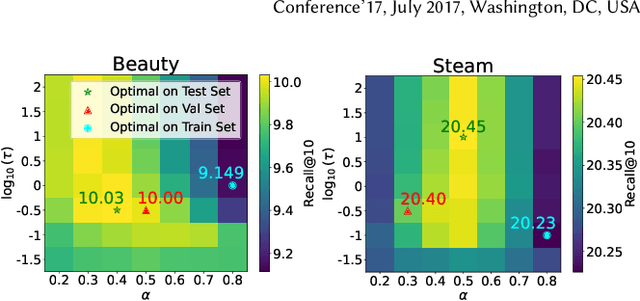
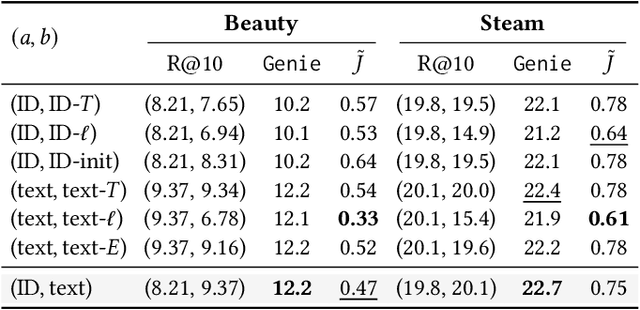
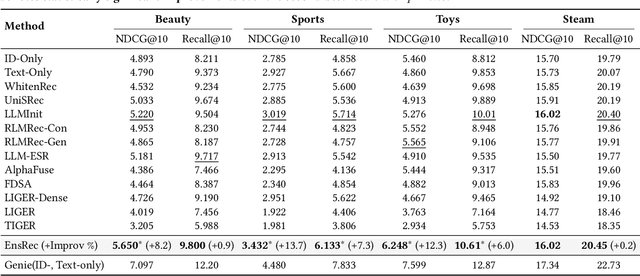
Modern Sequential Recommendation (SR) models commonly utilize modality features to represent items, motivated in large part by recent advancements in language and vision modeling. To do so, several works completely replace ID embeddings with modality embeddings, claiming that modality embeddings render ID embeddings unnecessary because they can match or even exceed ID embedding performance. On the other hand, many works jointly utilize ID and modality features, but posit that complex fusion strategies, such as multi-stage training and/or intricate alignment architectures, are necessary for this joint utilization. However, underlying both these lines of work is a lack of understanding of the complementarity of ID and modality features. In this work, we address this gap by studying the complementarity of ID- and text-based SR models. We show that these models do learn complementary signals, meaning that either should provide performance gain when used properly alongside the other. Motivated by this, we propose a new SR method that preserves ID-text complementarity through independent model training, then harnesses it through a simple ensembling strategy. Despite this method's simplicity, we show it outperforms several competitive SR baselines, implying that both ID and text features are necessary to achieve state-of-the-art SR performance but complex fusion architectures are not.
Hierarchical Token Prepending: Enhancing Information Flow in Decoder-based LLM Embeddings
Nov 18, 2025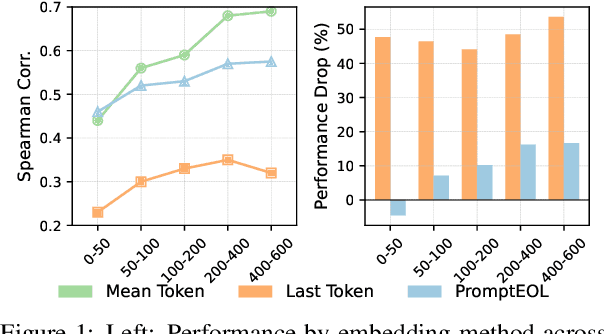
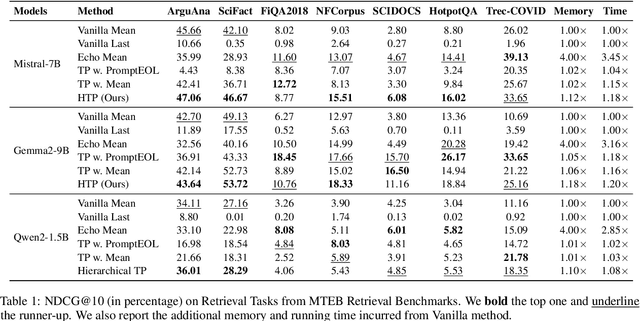
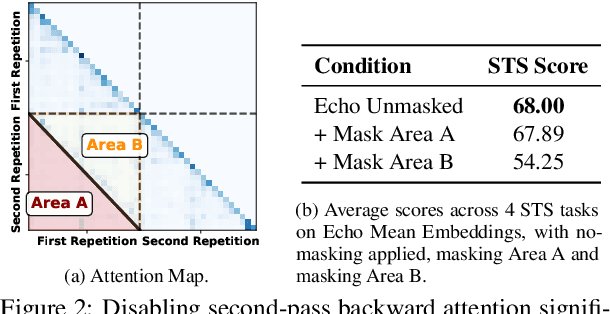
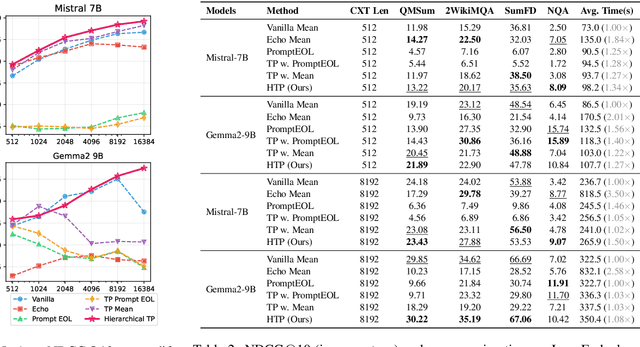
Large language models produce powerful text embeddings, but their causal attention mechanism restricts the flow of information from later to earlier tokens, degrading representation quality. While recent methods attempt to solve this by prepending a single summary token, they over-compress information, hence harming performance on long documents. We propose Hierarchical Token Prepending (HTP), a method that resolves two critical bottlenecks. To mitigate attention-level compression, HTP partitions the input into blocks and prepends block-level summary tokens to subsequent blocks, creating multiple pathways for backward information flow. To address readout-level over-squashing, we replace last-token pooling with mean-pooling, a choice supported by theoretical analysis. HTP achieves consistent performance gains across 11 retrieval datasets and 30 general embedding benchmarks, especially in long-context settings. As a simple, architecture-agnostic method, HTP enhances both zero-shot and finetuned models, offering a scalable route to superior long-document embeddings.
A Fourier-Based Global Denoising Model for Smart Artifacts Removing of Microscopy Images
Nov 12, 2025Microscopy such as Scanning Tunneling Microscopy (STM), Atomic Force Microscopy (AFM) and Scanning Electron Microscopy (SEM) are essential tools in material imaging at micro- and nanoscale resolutions to extract physical knowledge and materials structure-property relationships. However, tuning microscopy controls (e.g. scanning speed, current setpoint, tip bias etc.) to obtain a high-quality of images is a non-trivial and time-consuming effort. On the other hand, with sub-standard images, the key features are not accurately discovered due to noise and artifacts, leading to erroneous analysis. Existing denoising models mostly build on generalizing the weak signals as noises while the strong signals are enhanced as key features, which is not always the case in microscopy images, thus can completely erase a significant amount of hidden physical information. To address these limitations, we propose a global denoising model (GDM) to smartly remove artifacts of microscopy images while preserving weaker but physically important features. The proposed model is developed based on 1) first designing a two-imaging input channel of non-pair and goal specific pre-processed images with user-defined trade-off information between two channels and 2) then integrating a loss function of pixel- and fast Fourier-transformed (FFT) based on training the U-net model. We compared the proposed GDM with the non-FFT denoising model over STM-generated images of Copper(Cu) and Silicon(Si) materials, AFM-generated Pantoea sp.YR343 bio-film images and SEM-generated plastic degradation images. We believe this proposed workflow can be extended to improve other microscopy image quality and will benefit the experimentalists with the proposed design flexibility to smartly tune via domain-experts preferences.
Generative Recommendation with Semantic IDs: A Practitioner's Handbook
Jul 29, 2025Generative recommendation (GR) has gained increasing attention for its promising performance compared to traditional models. A key factor contributing to the success of GR is the semantic ID (SID), which converts continuous semantic representations (e.g., from large language models) into discrete ID sequences. This enables GR models with SIDs to both incorporate semantic information and learn collaborative filtering signals, while retaining the benefits of discrete decoding. However, varied modeling techniques, hyper-parameters, and experimental setups in existing literature make direct comparisons between GR proposals challenging. Furthermore, the absence of an open-source, unified framework hinders systematic benchmarking and extension, slowing model iteration. To address this challenge, our work introduces and open-sources a framework for Generative Recommendation with semantic ID, namely GRID, specifically designed for modularity to facilitate easy component swapping and accelerate idea iteration. Using GRID, we systematically experiment with and ablate different components of GR models with SIDs on public benchmarks. Our comprehensive experiments with GRID reveal that many overlooked architectural components in GR models with SIDs substantially impact performance. This offers both novel insights and validates the utility of an open-source platform for robust benchmarking and GR research advancement. GRID is open-sourced at https://github.com/snap-research/GRID.
Revisiting Self-attention for Cross-domain Sequential Recommendation
May 27, 2025Sequential recommendation is a popular paradigm in modern recommender systems. In particular, one challenging problem in this space is cross-domain sequential recommendation (CDSR), which aims to predict future behaviors given user interactions across multiple domains. Existing CDSR frameworks are mostly built on the self-attention transformer and seek to improve by explicitly injecting additional domain-specific components (e.g. domain-aware module blocks). While these additional components help, we argue they overlook the core self-attention module already present in the transformer, a naturally powerful tool to learn correlations among behaviors. In this work, we aim to improve the CDSR performance for simple models from a novel perspective of enhancing the self-attention. Specifically, we introduce a Pareto-optimal self-attention and formulate the cross-domain learning as a multi-objective problem, where we optimize the recommendation task while dynamically minimizing the cross-domain attention scores. Our approach automates knowledge transfer in CDSR (dubbed as AutoCDSR) -- it not only mitigates negative transfer but also encourages complementary knowledge exchange among auxiliary domains. Based on the idea, we further introduce AutoCDSR+, a more performant variant with slight additional cost. Our proposal is easy to implement and works as a plug-and-play module that can be incorporated into existing transformer-based recommenders. Besides flexibility, it is practical to deploy because it brings little extra computational overheads without heavy hyper-parameter tuning. AutoCDSR on average improves Recall@10 for SASRec and Bert4Rec by 9.8% and 16.0% and NDCG@10 by 12.0% and 16.7%, respectively. Code is available at https://github.com/snap-research/AutoCDSR.
Learning Universal User Representations Leveraging Cross-domain User Intent at Snapchat
Apr 30, 2025The development of powerful user representations is a key factor in the success of recommender systems (RecSys). Online platforms employ a range of RecSys techniques to personalize user experience across diverse in-app surfaces. User representations are often learned individually through user's historical interactions within each surface and user representations across different surfaces can be shared post-hoc as auxiliary features or additional retrieval sources. While effective, such schemes cannot directly encode collaborative filtering signals across different surfaces, hindering its capacity to discover complex relationships between user behaviors and preferences across the whole platform. To bridge this gap at Snapchat, we seek to conduct universal user modeling (UUM) across different in-app surfaces, learning general-purpose user representations which encode behaviors across surfaces. Instead of replacing domain-specific representations, UUM representations capture cross-domain trends, enriching existing representations with complementary information. This work discusses our efforts in developing initial UUM versions, practical challenges, technical choices and modeling and research directions with promising offline performance. Following successful A/B testing, UUM representations have been launched in production, powering multiple use cases and demonstrating their value. UUM embedding has been incorporated into (i) Long-form Video embedding-based retrieval, leading to 2.78% increase in Long-form Video Open Rate, (ii) Long-form Video L2 ranking, with 19.2% increase in Long-form Video View Time sum, (iii) Lens L2 ranking, leading to 1.76% increase in Lens play time, and (iv) Notification L2 ranking, with 0.87% increase in Notification Open Rate.
A Bi-channel Aided Stitching of Atomic Force Microscopy Images
Mar 11, 2025Microscopy is an essential tool in scientific research, enabling the visualization of structures at micro- and nanoscale resolutions. However, the field of microscopy often encounters limitations in field-of-view (FOV), restricting the amount of sample that can be imaged in a single capture. To overcome this limitation, image stitching techniques have been developed to seamlessly merge multiple overlapping images into a single, high-resolution composite. The images collected from microscope need to be optimally stitched before accurate physical information can be extracted from post analysis. However, the existing stitching tools either struggle to stitch images together when the microscopy images are feature sparse or cannot address all the transformations of images. To address these issues, we propose a bi-channel aided feature-based image stitching method and demonstrate its use on AFM generated biofilm images. The topographical channel image of AFM data captures the morphological details of the sample, and a stitched topographical image is desired for researchers. We utilize the amplitude channel of AFM data to maximize the matching features and to estimate the position of the original topographical images and show that the proposed bi-channel aided stitching method outperforms the traditional stitching approach. Furthermore, we found that the differentiation of the topographical images along the x-axis provides similar feature information to the amplitude channel image, which generalizes our approach when the amplitude images are not available. Here we demonstrated the application on AFM, but similar approaches could be employed of optical microscopy with brightfield and fluorescence channels. We believe this proposed workflow will benefit the experimentalist to avoid erroneous analysis and discovery due to incorrect stitching.
Meta-Learning Adaptable Foundation Models
Oct 29, 2024The power of foundation models (FMs) lies in their capacity to learn highly expressive representations that can be adapted to a broad spectrum of tasks. However, these pretrained models require multiple stages of fine-tuning to become effective for downstream applications. Conventionally, the model is first retrained on the aggregate of a diverse set of tasks of interest and then adapted to specific low-resource downstream tasks by utilizing a parameter-efficient fine-tuning (PEFT) scheme. While this two-phase procedure seems reasonable, the independence of the retraining and fine-tuning phases causes a major issue, as there is no guarantee the retrained model will achieve good performance post-fine-tuning. To explicitly address this issue, we introduce a meta-learning framework infused with PEFT in this intermediate retraining stage to learn a model that can be easily adapted to unseen tasks. For our theoretical results, we focus on linear models using low-rank adaptations. In this setting, we demonstrate the suboptimality of standard retraining for finding an adaptable set of parameters. Further, we prove that our method recovers the optimally adaptable parameters. We then apply these theoretical insights to retraining the RoBERTa model to predict the continuation of conversations between different personas within the ConvAI2 dataset. Empirically, we observe significant performance benefits using our proposed meta-learning scheme during retraining relative to the conventional approach.
In-Context Learning with Transformers: Softmax Attention Adapts to Function Lipschitzness
Feb 18, 2024



A striking property of transformers is their ability to perform in-context learning (ICL), a machine learning framework in which the learner is presented with a novel context during inference implicitly through some data, and tasked with making a prediction in that context. As such that learner must adapt to the context without additional training. We explore the role of softmax attention in an ICL setting where each context encodes a regression task. We show that an attention unit learns a window that it uses to implement a nearest-neighbors predictor adapted to the landscape of the pretraining tasks. Specifically, we show that this window widens with decreasing Lipschitzness and increasing label noise in the pretraining tasks. We also show that on low-rank, linear problems, the attention unit learns to project onto the appropriate subspace before inference. Further, we show that this adaptivity relies crucially on the softmax activation and thus cannot be replicated by the linear activation often studied in prior theoretical analyses.
Profit: Benchmarking Personalization and Robustness Trade-off in Federated Prompt Tuning
Oct 06, 2023In many applications of federated learning (FL), clients desire models that are personalized using their local data, yet are also robust in the sense that they retain general global knowledge. However, the presence of data heterogeneity across clients induces a fundamental trade-off between personalization (i.e., adaptation to a local distribution) and robustness (i.e., not forgetting previously learned general knowledge). It is critical to understand how to navigate this personalization vs robustness trade-off when designing federated systems, which are increasingly moving towards a paradigm of fine-tuning large foundation models. Due to limited computational and communication capabilities in most federated settings, this foundation model fine-tuning must be done using parameter-efficient fine-tuning (PEFT) approaches. While some recent work has studied federated approaches to PEFT, the personalization vs robustness trade-off of federated PEFT has been largely unexplored. In this work, we take a step towards bridging this gap by benchmarking fundamental FL algorithms -- FedAvg and FedSGD plus personalization (via client local fine-tuning) -- applied to one of the most ubiquitous PEFT approaches to large language models (LLMs) -- prompt tuning -- in a multitude of hyperparameter settings under varying levels of data heterogeneity. Our results show that federated-trained prompts can be surprisingly robust when using a small learning rate with many local epochs for personalization, especially when using an adaptive optimizer as the client optimizer during federated training. We also demonstrate that simple approaches such as adding regularization and interpolating two prompts are effective in improving the personalization vs robustness trade-off in computation-limited settings with few local updates allowed for personalization.