 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised User Profile Generation for Personalization
Jun 03, 2026Personalizing large language models (LLMs) has become a central challenge as LLMs are deployed across recommendation, search, dialogue, and content generation -- settings where the same query should yield different answers given different users. A promising route is to summarize each user's interaction history into a natural-language memory or profile and prepend it to the prompt to facilitate personalization. Existing methods learn such profile generators with explicit rewards derived from labeled downstream tasks, which are expensive and sparse as they require annotated supervision for every target task. In light of this challenge, we introduce Bidirectional User Modeling via Profiles (BUMP), a self-supervised framework that trains a profile generator without any downstream labels. Specifically, given a user's interaction history, we use GRPO to train an LLM to emit a free-form textual profile under a bidirectional in-batch ranking objective: a small LLM judge measures (i) how well the generated profile, used as a query, ranks the user's own held-out interactions above interactions from other users in the batch, and (ii) how well a held-out interaction, used as a query, ranks the user's own profile above profiles of other users. Both directions are scored with multi-positive NDCG and combined into a dense reward per rollout; other users in the batch supply free negatives, so every training example yields supervision from raw interaction logs alone. Evaluated on the LaMP benchmark, BUMP matches or outperforms closed-source APIs and prior methods relying on labeled rewards, while requiring no task label at training.
Revisiting Self-attention for Cross-domain Sequential Recommendation
May 27, 2025Sequential recommendation is a popular paradigm in modern recommender systems. In particular, one challenging problem in this space is cross-domain sequential recommendation (CDSR), which aims to predict future behaviors given user interactions across multiple domains. Existing CDSR frameworks are mostly built on the self-attention transformer and seek to improve by explicitly injecting additional domain-specific components (e.g. domain-aware module blocks). While these additional components help, we argue they overlook the core self-attention module already present in the transformer, a naturally powerful tool to learn correlations among behaviors. In this work, we aim to improve the CDSR performance for simple models from a novel perspective of enhancing the self-attention. Specifically, we introduce a Pareto-optimal self-attention and formulate the cross-domain learning as a multi-objective problem, where we optimize the recommendation task while dynamically minimizing the cross-domain attention scores. Our approach automates knowledge transfer in CDSR (dubbed as AutoCDSR) -- it not only mitigates negative transfer but also encourages complementary knowledge exchange among auxiliary domains. Based on the idea, we further introduce AutoCDSR+, a more performant variant with slight additional cost. Our proposal is easy to implement and works as a plug-and-play module that can be incorporated into existing transformer-based recommenders. Besides flexibility, it is practical to deploy because it brings little extra computational overheads without heavy hyper-parameter tuning. AutoCDSR on average improves Recall@10 for SASRec and Bert4Rec by 9.8% and 16.0% and NDCG@10 by 12.0% and 16.7%, respectively. Code is available at https://github.com/snap-research/AutoCDSR.
Learning Universal User Representations Leveraging Cross-domain User Intent at Snapchat
Apr 30, 2025The development of powerful user representations is a key factor in the success of recommender systems (RecSys). Online platforms employ a range of RecSys techniques to personalize user experience across diverse in-app surfaces. User representations are often learned individually through user's historical interactions within each surface and user representations across different surfaces can be shared post-hoc as auxiliary features or additional retrieval sources. While effective, such schemes cannot directly encode collaborative filtering signals across different surfaces, hindering its capacity to discover complex relationships between user behaviors and preferences across the whole platform. To bridge this gap at Snapchat, we seek to conduct universal user modeling (UUM) across different in-app surfaces, learning general-purpose user representations which encode behaviors across surfaces. Instead of replacing domain-specific representations, UUM representations capture cross-domain trends, enriching existing representations with complementary information. This work discusses our efforts in developing initial UUM versions, practical challenges, technical choices and modeling and research directions with promising offline performance. Following successful A/B testing, UUM representations have been launched in production, powering multiple use cases and demonstrating their value. UUM embedding has been incorporated into (i) Long-form Video embedding-based retrieval, leading to 2.78% increase in Long-form Video Open Rate, (ii) Long-form Video L2 ranking, with 19.2% increase in Long-form Video View Time sum, (iii) Lens L2 ranking, leading to 1.76% increase in Lens play time, and (iv) Notification L2 ranking, with 0.87% increase in Notification Open Rate.
MB-TaylorFormer V2: Improved Multi-branch Linear Transformer Expanded by Taylor Formula for Image Restoration
Jan 08, 2025Recently, Transformer networks have demonstrated outstanding performance in the field of image restoration due to the global receptive field and adaptability to input. However, the quadratic computational complexity of Softmax-attention poses a significant limitation on its extensive application in image restoration tasks, particularly for high-resolution images. To tackle this challenge, we propose a novel variant of the Transformer. This variant leverages the Taylor expansion to approximate the Softmax-attention and utilizes the concept of norm-preserving mapping to approximate the remainder of the first-order Taylor expansion, resulting in a linear computational complexity. Moreover, we introduce a multi-branch architecture featuring multi-scale patch embedding into the proposed Transformer, which has four distinct advantages: 1) various sizes of the receptive field; 2) multi-level semantic information; 3) flexible shapes of the receptive field; 4) accelerated training and inference speed. Hence, the proposed model, named the second version of Taylor formula expansion-based Transformer (for short MB-TaylorFormer V2) has the capability to concurrently process coarse-to-fine features, capture long-distance pixel interactions with limited computational cost, and improve the approximation of the Taylor expansion remainder. Experimental results across diverse image restoration benchmarks demonstrate that MB-TaylorFormer V2 achieves state-of-the-art performance in multiple image restoration tasks, such as image dehazing, deraining, desnowing, motion deblurring, and denoising, with very little computational overhead. The source code is available at https://github.com/FVL2020/MB-TaylorFormerV2.
MB-TaylorFormer: Multi-branch Efficient Transformer Expanded by Taylor Formula for Image Dehazing
Aug 30, 2023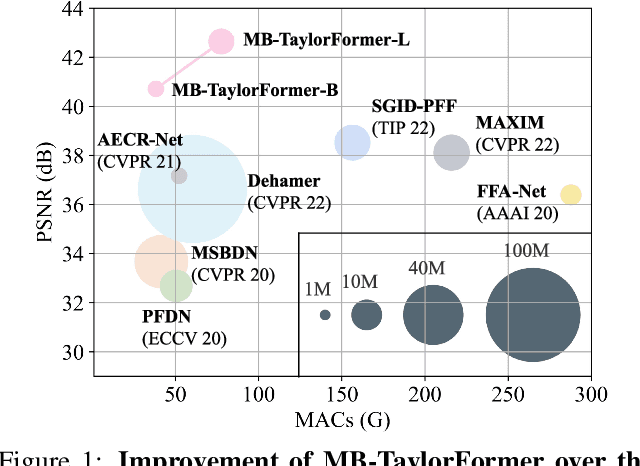



In recent years, Transformer networks are beginning to replace pure convolutional neural networks (CNNs) in the field of computer vision due to their global receptive field and adaptability to input. However, the quadratic computational complexity of softmax-attention limits the wide application in image dehazing task, especially for high-resolution images. To address this issue, we propose a new Transformer variant, which applies the Taylor expansion to approximate the softmax-attention and achieves linear computational complexity. A multi-scale attention refinement module is proposed as a complement to correct the error of the Taylor expansion. Furthermore, we introduce a multi-branch architecture with multi-scale patch embedding to the proposed Transformer, which embeds features by overlapping deformable convolution of different scales. The design of multi-scale patch embedding is based on three key ideas: 1) various sizes of the receptive field; 2) multi-level semantic information; 3) flexible shapes of the receptive field. Our model, named Multi-branch Transformer expanded by Taylor formula (MB-TaylorFormer), can embed coarse to fine features more flexibly at the patch embedding stage and capture long-distance pixel interactions with limited computational cost. Experimental results on several dehazing benchmarks show that MB-TaylorFormer achieves state-of-the-art (SOTA) performance with a light computational burden. The source code and pre-trained models are available at https://github.com/FVL2020/ICCV-2023-MB-TaylorFormer.