 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAML and ANIL Provably Learn Representations
Paper and Code
Feb 07, 2022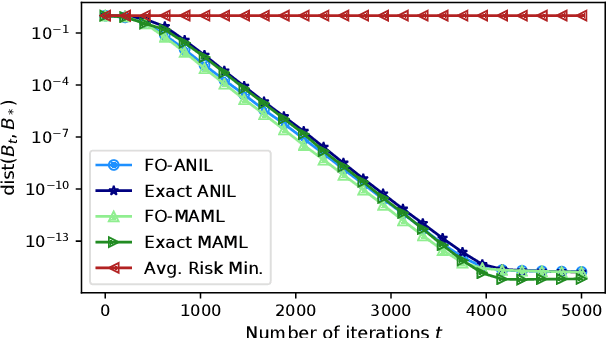

Recent empirical evidence has driven conventional wisdom to believe that gradient-based meta-learning (GBML) methods perform well at few-shot learning because they learn an expressive data representation that is shared across tasks. However, the mechanics of GBML have remained largely mysterious from a theoretical perspective. In this paper, we prove that two well-known GBML methods, MAML and ANIL, as well as their first-order approximations, are capable of learning common representation among a set of given tasks. Specifically, in the well-known multi-task linear representation learning setting, they are able to recover the ground-truth representation at an exponentially fast rate. Moreover, our analysis illuminates that the driving force causing MAML and ANIL to recover the underlying representation is that they adapt the final layer of their model, which harnesses the underlying task diversity to improve the representation in all directions of interest. To the best of our knowledge, these are the first results to show that MAML and/or ANIL learn expressive representations and to rigorously explain why they do so.