 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Thompson Sampling Algorithms Against Reward Poisoning Attacks
Paper and Code
Oct 25, 2024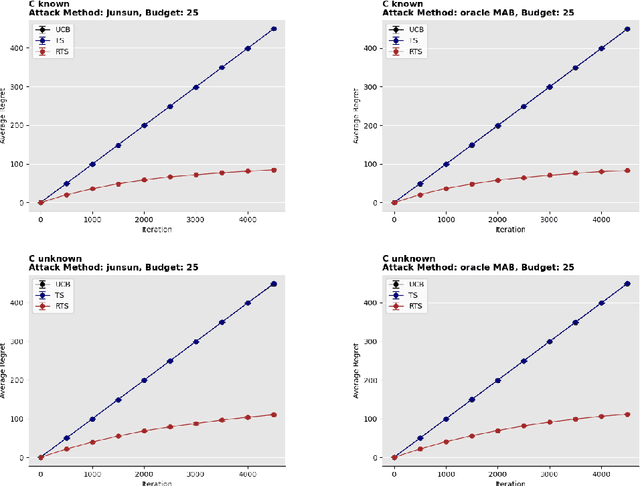


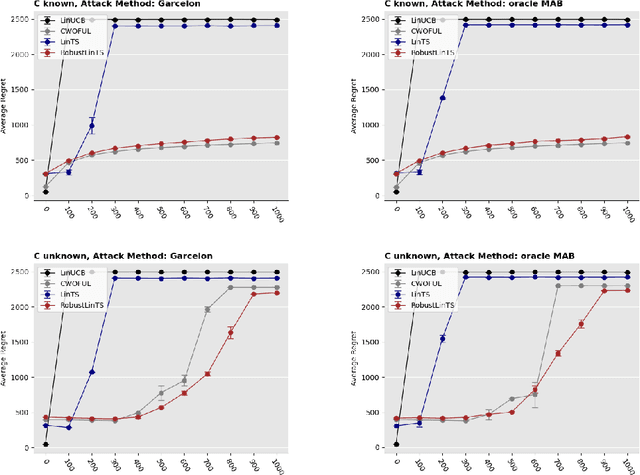
Thompson sampling is one of the most popular learning algorithms for online sequential decision-making problems and has rich real-world applications. However, current Thompson sampling algorithms are limited by the assumption that the rewards received are uncorrupted, which may not be true in real-world applications where adversarial reward poisoning exists. To make Thompson sampling more reliable, we want to make it robust against adversarial reward poisoning. The main challenge is that one can no longer compute the actual posteriors for the true reward, as the agent can only observe the rewards after corruption. In this work, we solve this problem by computing pseudo-posteriors that are less likely to be manipulated by the attack. We propose robust algorithms based on Thompson sampling for the popular stochastic and contextual linear bandit settings in both cases where the agent is aware or unaware of the budget of the attacker. We theoretically show that our algorithms guarantee near-optimal regret under any attack strategy.